RedirectQA
收藏arXiv2026-04-24 更新2026-04-25 收录
下载链接:
https://huggingface.co/datasets/naist-nlp/RedirectQA
下载链接
链接失效反馈官方服务:
资源简介:
RedirectQA是由奈良先端科学技术大学院大学和Future Corporation联合创建的实体问答数据集,旨在研究大语言模型通过不同实体表面形式访问相同事实知识的能力。该数据集包含30,560个表面实例,源自14,672个Wikidata事实三元组,通过维基百科重定向信息关联了实体的规范名称和多种变体形式。数据构建过程包括从Wikidata收集事实三元组、利用维基百科重定向注释实体表面形式,并使用关系特定模板生成问题。该数据集主要应用于评估大语言模型在实体不同表面形式下的非逐字记忆能力,揭示模型在事实访问中的表面形式依赖性。
RedirectQA is an entity question answering dataset jointly developed by Nara Institute of Science and Technology and Future Corporation, which aims to study the capability of large language models (LLMs) to access identical factual knowledge through diverse entity surface forms. This dataset comprises 30,560 surface-level instances derived from 14,672 Wikidata factual triples, and links the canonical names and various variant forms of entities via Wikipedia redirect information. The data construction workflow includes collecting factual triples from Wikidata, annotating entity surface forms using Wikipedia redirects, and generating questions with relation-specific templates. This dataset is mainly applied to evaluate the non-verbatim memory ability of large language models under different entity surface forms, and reveals the surface form dependence of models in factual knowledge access.
提供机构:
奈良先端科学技术大学院大学; Future Corporation
创建时间:
2026-04-24
原始信息汇总
RedirectQA 数据集概述
基本信息
- 数据集名称:RedirectQA
- 许可证:CC BY-SA 4.0
- 语言:英语(en)
- 任务类型:问答(question-answering)
- 数据规模:10K < n < 100K
数据集描述
RedirectQA 是一个基于实体的事实性问答数据集,旨在分析大型语言模型如何通过同一实体的不同表面形式获取相同事实。该版本(v1.0.0)与论文 Revisiting Non-Verbatim Memorization in Large Language Models: The Role of Entity Surface Forms 中描述的数据集一致。
数据集规模
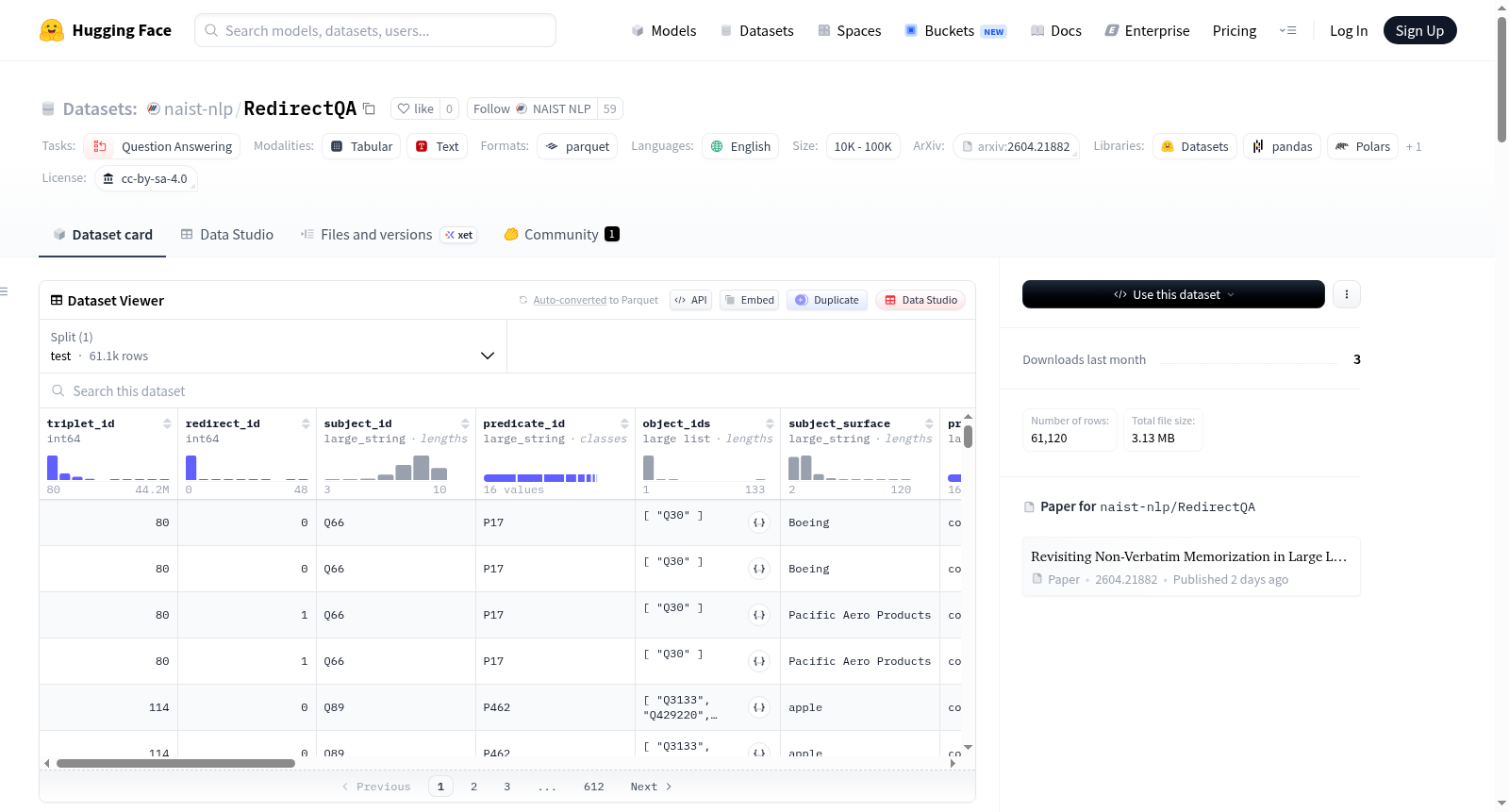
- 问题实现:61,120 个(test 分割)
- 主体-表面实例:30,560 个
- Wikidata 事实三元组:14,672 个
- 规范表面实例:14,672 个
- 重定向表面实例:15,888 个
- 关系类型:16 种
- 重定向类别:33 种
每个表面实例通过两个问题模板呈现:
- original:原始 PopQA 风格模板
- paraphrased:数据集构建过程中生成的释义模板
数据集结构
该版本提供一个配置:
- 配置名称:default
- 分割:test
- 文件路径:
data/test.parquet
在 data/test.parquet 中,每一行对应一个问题实现。由于每个表面实例出现在两个模板下,每个 (triplet_id, redirect_id) 对恰好出现两次:一次 template_type="original",一次 template_type="paraphrased"。
主要数据文件
data/test.parquet:61,120 行,每行一个问题实现
元数据文件
metadata/question_templates.json:每个谓词的两个公开问题模板metadata/redirect_category_to_type.csv:每个重定向类别到论文中使用的更高级别类型的映射
数据字段
| 字段 | 描述 |
|---|---|
triplet_id |
底层事实三元组的标识符 |
redirect_id |
三元组内的表面形式标识符;0 表示规范表面 |
subject_id |
主体实体的 Wikidata ID |
predicate_id |
Wikidata 属性 ID |
object_ids |
答案实体的 Wikidata ID |
subject_surface |
问题中使用的主体字符串 |
predicate_surface |
自然语言关系标签 |
object_surfaces |
规范答案表面形式 |
subject_aliases |
构建过程中收集的主体别名 |
object_aliases |
答案实体的别名列表 |
subject_wiki_title |
主体的规范英文 Wikipedia 标题 |
object_wiki_titles |
答案实体的规范英文 Wikipedia 标题 |
subject_pageviews |
主体的年度 Wikipedia 页面浏览量 |
object_pageviews |
答案实体的年度 Wikipedia 页面浏览量 |
subject_redirect_wiki_title |
当表面非规范时的重定向标题;规范行中为 null |
subject_surface_category |
重定向类别标签;规范行使用 ["__MAIN__"] |
possible_answers |
用于评估的可接受答案字符串 |
template_type |
问题模板类型:original 或 paraphrased |
question |
最终的自然语言问题 |
高级重定向类型
重定向类别分为以下更高级别的类型:
- Aliases_and_Abbreviations:别名和缩写
- Spelling_variants:拼写变体
- Typical_Errors:典型错误
规范行在 metadata/redirect_category_to_type.csv 中单独标记为 Canonical。
数据统计
- 表面实例:30,560 个,源自 14,672 个事实三元组
- 规范表面实例:14,672 个
- 重定向表面实例:15,888 个
- 问题实现:61,120 个(每个表面实例对应两个模板)
- 重定向表面实例细分:
- Aliases_and_Abbreviations:8,667 个
- Spelling_variants:4,928 个
- Typical_Errors:2,884 个
数据来源与许可说明
本数据集基于多个资源构建:
- 英文 Wikipedia 重定向和标题
- Wikidata 事实三元组
- Wikimedia 页面浏览统计
- PopQA 设置(用于关系选择和原始问题模板)
底层来源的许可证不同:
- Wikipedia 文本:CC BY-SA 4.0
- Wikidata 和页面浏览:CC0 1.0
- PopQA:MIT
加载数据集
python from datasets import load_dataset
dataset = load_dataset("naist-nlp/RedirectQA", split="test") print(dataset)
搜集汇总
数据集介绍
构建方式
RedirectQA数据集的构建依托于维基数据(Wikidata)中的事实三元组,并借助维基百科(Wikipedia)的重定向页面信息,为每个实体关联多种表面形式。具体而言,首先从Wikidata中收集以实体为对象、涵盖16种关系类型的事实三元组,确保每个三元组具有唯一且明确的答案。随后,利用维基百科的重定向结构,为每个实体获取其规范表面形式(即文章标题)和多种重定向表面形式(如别名、缩写、拼写变体及常见错误形式),并根据重定向类别将其划分为三大类型:替代名称与缩写、拼写变体以及典型错误。最后,通过关系特定的问题模板,将每个表面形式实例转化为具体的问答对,从而构建出固定事实关系与答案,仅改变实体提及方式的评测数据集。
特点
RedirectQA的核心特点在于其系统性地控制了事实知识本身,仅改变实体的表面提及形式,从而揭示大型语言模型在事实访问中对表面形式的依赖性。该数据集包含了超过3万个表面形式实例,覆盖近1.5万个事实三元组,并精心标注了表面形式的类别(如替代名称、缩写、拼写变体与常见错误),使得研究者能够细粒度地分析不同类型命名变化对模型预测一致性的影响。实验表明,模型对拼写变体等微小正字法变化相对鲁棒,但在别名、缩写等较大词汇变化上表现出的不一致性显著增加,表明非逐字记忆既非完全表面特定,也非完全表面不变。此外,数据集通过双模板生成问题,减少了问题措辞带来的干扰。
使用方法
使用RedirectQA时,研究者可通过加载公开的Hugging Face数据集仓库获取该资源。典型的评估流程包括:选定待评估的大型语言模型(如Pythia、OLMo 2等透明模型或GPT-4o-mini等API模型),采用15-shot上下文学习设置,使用固定种子从其他关系类型中采样示例。对于每个测试问题,模型需在不提供外部证据的开放域问答设定下,基于参数化知识进行回答。预测结果通过别名感知的字符串匹配进行评估,即若预测结果包含答案实体的任一可接受表面形式(允许大小写变体),则判定为正确。数据集的核心分析单元是规范-重定向表面形式对,通过比较同一事实三元组下不同表面形式的预测一致性,研究者可以量化表面形式的依赖程度,并深入分析实体级与表面级频率对记忆效果的影响。
背景与挑战
背景概述
RedirectQA数据集由日本奈良先端科学技术大学院大学与Future Corporation的Yuto Nishida等人于2025年联合构建,旨在深入探究大型语言模型在非逐字记忆中的表面形式依赖性。该数据集以维基百科重定向信息为核心资源,将Wikidata事实三元组与实体的多种表面形式(如别名、缩写、拼写变体及常见错误形式)系统性地关联起来,突破了以往仅依赖单一规范名称评估模型事实记忆的局限。通过控制事实关系与正确答案不变、仅变化实体提及形式的设计,RedirectQA揭示了模型在事实访问中存在的表面条件性偏差,为理解语言模型知识存储与检索的底层机制提供了关键分析工具。该数据集涵盖约3万条实例,覆盖16种关系类型,已被广泛应用于评估GPT-4o、Llama 3.1等前沿模型的鲁棒性,对事实知识记忆研究领域产生了显著影响。
当前挑战
RedirectQA所应对的核心挑战在于:传统基于实体的事实问答评估往往仅使用实体的规范表面形式来查询模型,使得研究者难以区分模型是否真正记忆了关于实体的事实知识,抑或仅仅因特定名称而正确访问了该知识。这种混淆在现实中尤为严峻——同一实体常以多种方式被提及(如“Pelé”与“Edson Arantes do Nascimento”),而模型在不同表面形式下可能展现出截然不同的预测一致性。构建过程中的挑战则体现在:需从维基百科海量重定向页面中筛选出真正代表表面形式变化的类别(如从出生名、首字母缩略词等),同时排除因书籍标题等导致指代实体错误的歧义情况;还需对类别严重不平衡(如无变音符号标题过占优势)进行精细降采样,以保证分析统计效力。此外,确保每种表面实例与事实三元组的正确关联、并生成鲁棒的模板化问题以避免措辞干扰,亦是数据集构建的技术难点。
常用场景
经典使用场景
在大型语言模型非逐字记忆的研究领域中,RedirectQA数据集被广泛用于评估模型在不同实体表面形式下的事实知识访问一致性。该数据集通过利用维基百科重定向信息,将同一实体的多种指称形式(如别名、缩写、拼写变体和常见错误形式)与固定的知识三元组关联起来,从而系统性地揭示模型在面对同一实体不同命名方式时预测结果的不稳定性。这一经典使用场景为探究语言模型对事实知识的记忆是否具有表面形式依赖性提供了关键的实验框架。
衍生相关工作
RedirectQA的发布催生了一系列关于语言模型表面形式敏感性的后续研究工作。受其启发,学者们开始探索在不同语言、领域和知识类型中实体表面形式对事实记忆的影响,并进一步开发了针对缩写、拼写错误、名称变体等特定类别的细粒度评估基准。此外,该数据集所揭示的跨表面耦合特性也激发了关于模型内部表示中实体与表面形式关联机制的研究,促进了从行为分析到认知机理的纵深探索,成为非逐字记忆研究领域的重要参考资源。
数据集最近研究
最新研究方向
RedirectQA数据集聚焦于大语言模型在非逐字记忆中的表面形式依赖性,前沿研究方向在于探究同一实体经由不同表面形式(如别名、缩写、拼写变体)访问事实知识时,模型预测一致性的显著差异。该研究揭示了模型的记忆并非完全表面不变,而是呈现类别依赖性:对拼写变体鲁棒,但面对初始ism等词汇变体时脆弱。这一发现与近期对LLM可靠性及长尾知识记忆的热点议题紧密关联,凸显了表面形式多样性在评估模型事实访问能力中的关键作用,为构建更鲁棒的知识评估基准提供了方法论支撑。
相关研究论文
- 1Revisiting Non-Verbatim Memorization in Large Language Models: The Role of Entity Surface Forms奈良先端科学技术大学院大学; Future Corporation · 2026年
以上内容由遇见数据集搜集并总结生成


