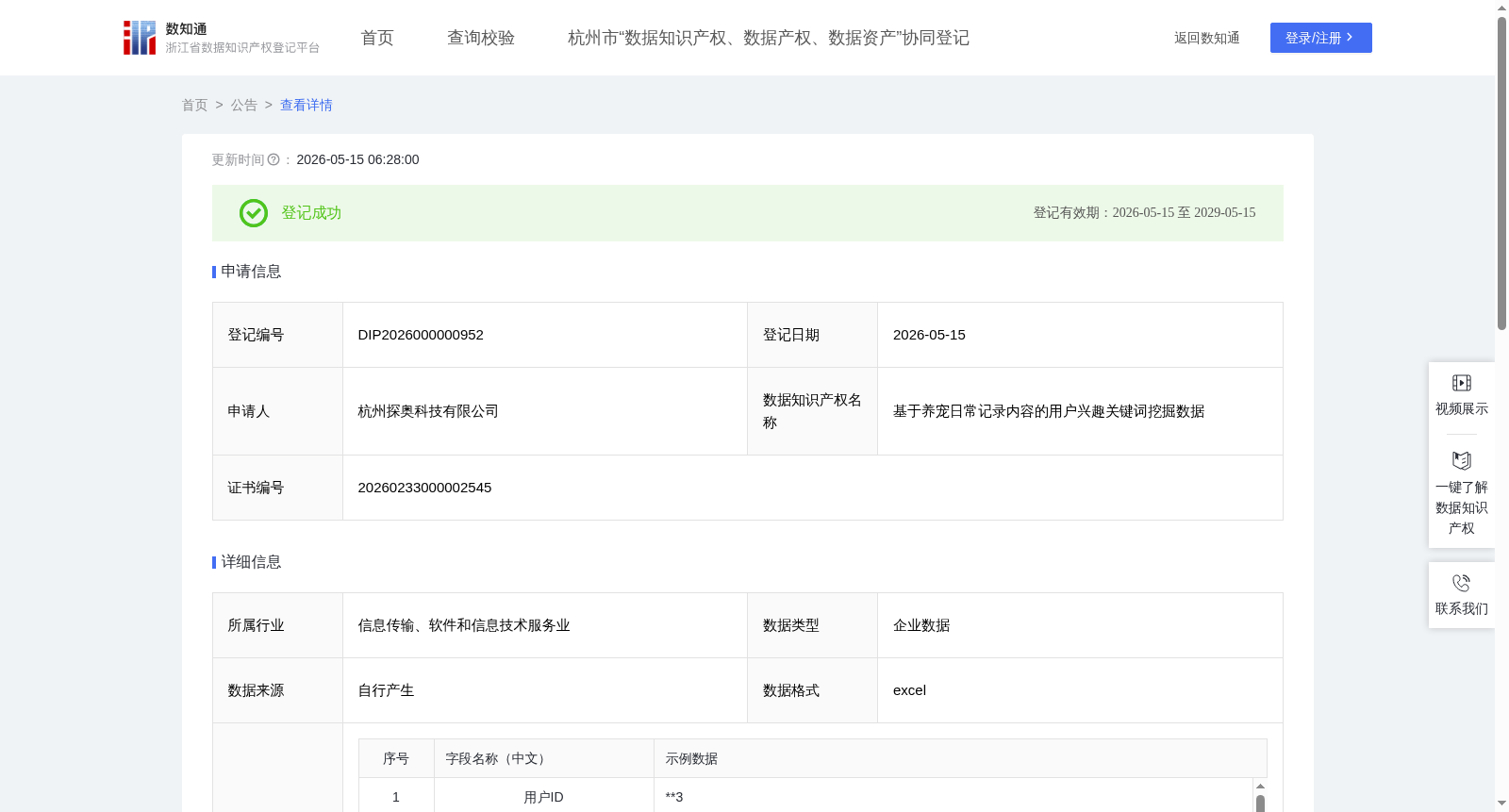
基于养宠日常记录内容的用户兴趣关键词挖掘数据
收藏浙江省数据知识产权登记平台2026-05-15 更新2026-05-16 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8444861
下载链接
链接失效反馈官方服务:
资源简介:
1.“宠one小程序”是公司自研的一款宠物社区平台,因此本数据对内有助于实现精细化用户运营。基于通过BERT模型微调生成的用户兴趣画像,运营团队能够精准把握养宠用户的需求动向,从而动态优化内容推荐与服务策略,有效提升用户活跃度与留存。
2.对外可为合作伙伴提供清晰的兴趣趋势洞察。经脱敏处理的用户主兴趣类别与关键词,能够帮助品牌及服务商把握市场需求的结构性变化,辅助其优化产品规划与营销资源分配,实现更精准的商业协同。
3.为算法模型提供持续迭代的高质量训练与验证样本。本数据产出过程本身即依赖于模型微调,其输出的带标注的兴趣画像数据,可直接作为推荐系统及预测模型的反馈信号,用于模型的再训练与优化,形成从数据到模型、再从业务反馈到数据的增强闭环。1.加工前的数据说明:(1)加工前的数据为公司基于“宠one小程序”日常记录功能实时采集的由小程序用户自行记录的宠物基本信息数据,并已经用户授权合法获得,采集字段包括:用户id、内容、记录类别和创建时间;(2)数据预处理:过滤内容为空或无效字符的异常记录。 2.处理规则: (1)特征构建:对清洗后的“内容”文本应用BERT词嵌入生成上下文向量表示,并与“记录类别”字段共同作为模型输入。 (2)模型微调: ①基础模型:采用RoBERTa-wwm-ext作为预训练模型进行微调。 ②模型结构调整:在RoBERTa模型的最终输出层上接入双任务结构——兴趣分类分支采用Softmax层输出四大兴趣类别(饮食营养/健康医疗/行为训练与托管/居住与日常护理)的概率分布,关键词提取分支采用指针网络(Pointer Network)从原始内容中抽取最具表征性的连续文本片段,构成端到端联合学习模型。 ③训练设置:将数据集按8:1:1划分训练集、验证集与测试集。设置批次大小为24,学习率为2e-5,共训练12个轮次。训练过程同步优化双任务损失函数,使模型能准确预测兴趣类别并定位关键词。 (3)兴趣类别判定:将预处理后的数据输入上述微调好的模型,模型通过兴趣分类分支的Softmax层输出四大类别的概率分布,将概率最高的类别判定为该条记录的主兴趣类别。 (4)核心关键词提取:利用微调后模型中关键词提取分支的指针网络机制,根据模型对原始内容各位置的关注权重,直接抽取权重最高的连续文本片段作为核心兴趣关键词。此过程与分类任务共享同一个训练好的模型,无需引入外部工具。 (5)最终输出:每条日常记录处理完成后,输出其对应的主兴趣类别与核心兴趣关键词。 3.数据内容描述:加工前的数据经上述算法规则处理后,输出的数据内容为:每条日常记录所对应的主兴趣类别与核心兴趣关键词。
提供机构:
杭州探奥科技有限公司
创建时间:
2026-02-06
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集基于宠物社区平台“宠one小程序”的用户日常记录,通过RoBERTa-wwm-ext模型微调,自动挖掘每条记录对应的主兴趣类别(如饮食营养、健康医疗等)与核心兴趣关键词。数据集包含1020条标注样本,用于精细化用户运营、商业洞察以及推荐模型的迭代优化,能够有效提升用户活跃度和商业协同效率。
以上内容由遇见数据集搜集并总结生成


