mermaid-text-to-diagram
收藏Hugging Face2026-04-15 更新2026-04-16 收录
下载链接:
https://huggingface.co/datasets/SpongeBOB9684/mermaid-text-to-diagram
下载链接
链接失效反馈官方服务:
资源简介:
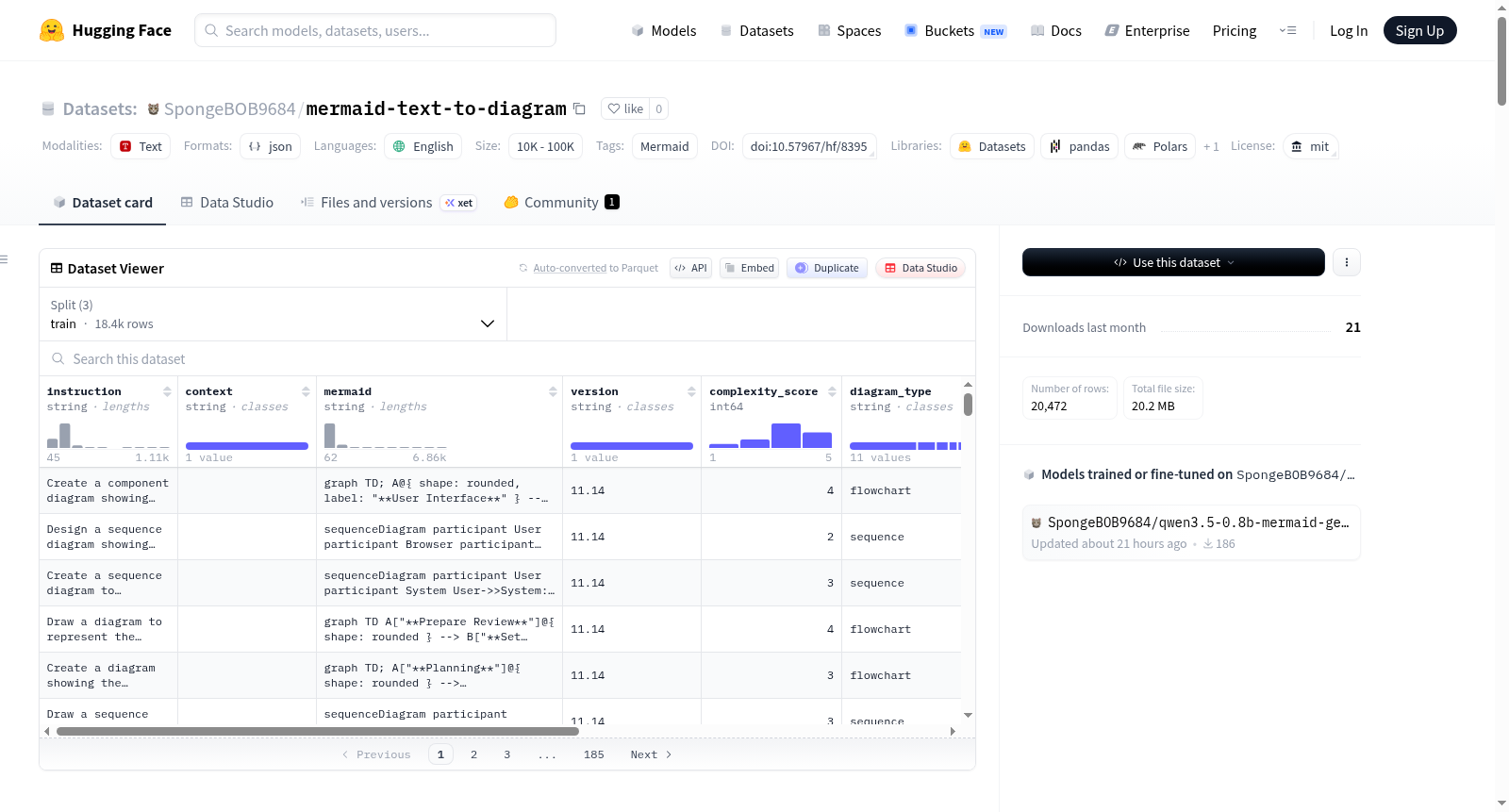
Mermaid 11.14 训练数据集是一个专门用于微调 Qwen3.5-0.8B 模型以进行文本到 Mermaid 图表生成的数据集。该数据集包含 9,913 个经过验证的 Mermaid 11.14 示例,严格基于 Mermaid 11.14.0 官方文档。数据集由三个来源组成:Celiadraw/text-to-mermaid(8,912 例,约 90%)、djds4rce/mermaid-synthetic(926 例,约 9%)和 LLM 生成的边缘案例(75 例,约 1%)。数据集涵盖了多种图表类型,包括流程图(54.7%)、序列图(15.1%)、类图(10.4%)等,并按复杂度分为五个等级。每个示例包含自然语言描述、上下文、Mermaid 代码、版本、复杂度评分、图表类型、特征标签等字段。数据集分为训练集(80%)、验证集(10%)和测试集(10%),所有示例均通过 mermaid-cli 验证以确保语法正确性和渲染成功。该数据集适用于轻量级模型的训练,特别适合浏览器部署场景。
创建时间:
2026-04-15
原始信息汇总
Mermaid 11.14 Training Dataset 概述
数据集基本信息
- 名称: Mermaid 11.14 Training Dataset
- 地址: https://huggingface.co/datasets/SpongeBOB9684/mermaid-text-to-diagram
- 语言: 英语
- 标签: Mermaid
- 许可证: MIT
- 用途: 用于微调 Qwen3.5-0.8B 模型,以实现 Mermaid Studio 的文本到 Mermaid 图表生成。
数据集规模与构成
- 总样本量: 9,913 个经过验证的 Mermaid 11.14 示例。
- 数据来源:
- Celiadraw/text-to-mermaid: 8,912 个示例 (~90%),非 LLM 生成。
- djds4rce/mermaid-synthetic: 926 个示例 (~9%),非 LLM 生成,使用 MIT 许可证。
- Edge Cases (LLM Generated): 75 个示例 (~1%),通过 LLM 生成以覆盖缺失的 Mermaid 11.14 特性。
- 数据分布: 现有数据(非 LLM 生成)占 99%,LLM 生成的边缘案例占 1%。
数据集统计信息
图表类型分布
| 类型 | 数量 | 百分比 |
|---|---|---|
| flowchart | 5,418 | 54.7% |
| sequence | 1,501 | 15.1% |
| class | 1,026 | 10.4% |
| er | 715 | 7.2% |
| state | 503 | 5.1% |
| gantt | 408 | 4.1% |
| mindmap | 165 | 1.7% |
| unknown | 74 | 0.7% |
| pie | 71 | 0.7% |
| git | 30 | 0.3% |
| journey | 2 | 0.0% |
复杂度分布
| 等级 | 描述 | 数量 | 百分比 |
|---|---|---|---|
| 1 | 简单 (≤3 节点) | 757 | 7.6% |
| 2 | 低 (4-6 节点) | 1,634 | 16.5% |
| 3 | 中等 (7-12 节点) | 4,591 | 46.3% |
| 4 | 高 (13-25 节点,子图) | 2,493 | 25.1% |
| 5 | 非常复杂 (>25 节点,样式) | 438 | 4.4% |
特性覆盖
| 特性 | 数量 |
|---|---|
| markdown-in-nodes | 5,341 |
| basic | 4,411 |
| subgraphs | 529 |
| styling | 161 |
| multi-directional-arrows | 49 |
| event-nodes | 17 |
| bolt-nodes | 17 |
| window-nodes | 17 |
数据模式
每个示例包含以下字段: json { "instruction": "图表的自然语言描述", "context": "可选的对话上下文", "mermaid": "经过验证的 Mermaid 11.14 代码", "version": "11.14", "complexity_score": 1-5, "diagram_type": "flowchart|sequence|state|class|er|...", "feature_tags": ["feature1", "feature2", ...], "validation_status": "validated", "source": "celiadraw|djds4rce|generated|...", "timestamp": "2026-04-12T..." }
数据划分
- 训练集: 80% 的示例
- 验证集: 10% 的示例
- 测试集: 10% 的示例
验证方法
所有示例均使用 @mermaid-js/mermaid-cli (mmdc) 进行验证,以确保:
- 正确的 Mermaid 11.14 语法
- 成功渲染
- 无解析错误
- 符合官方规范
文档基础
本数据集严格基于 Mermaid 11.14.0 官方文档:
- 官方文档: https://mermaid.js.org/intro/
- 语法规范: https://mermaid.js.org/syntax/
- 所有示例均符合 11.14.0 版本。
许可证
本数据集源自以下许可证的源数据:
- Celiadraw/text-to-mermaid: 公共数据集
- djds4rce/mermaid-synthetic: MIT 许可证
- Edge cases (LLM generated): Mermaid Studio 项目 Mermaid Studio 项目的修改和改进依据 Apache 2.0 许可证授权。
搜集汇总
数据集介绍
构建方式
在文本到图表生成领域,构建高质量数据集是推动模型性能提升的关键。该数据集通过整合多个来源精心构建,其中约99%的示例源自两个现有非LLM生成的数据集,确保了数据的真实性与可靠性。为了全面覆盖Mermaid 11.14版本的新特性,约1%的示例通过大型语言模型生成,专门针对边缘案例和复杂场景进行补充。所有示例均经过严格的语法验证和渲染测试,确保其完全符合官方规范,为模型训练提供了坚实的数据基础。
使用方法
在自然语言处理与代码生成的研究中,该数据集为指令微调提供了标准化的输入输出对。研究人员可通过加载JSONL格式的文件,便捷地访问每个示例的自然语言描述、上下文信息以及对应的Mermaid代码。数据集已划分为训练集、验证集和测试集,便于直接用于模型训练与性能评估。借助HuggingFace生态系统,用户可以轻松地将数据转换为指令调优所需的格式,进而训练能够理解文本指令并生成准确图表代码的轻量级模型。
背景与挑战
背景概述
在自然语言处理与软件工程交叉领域,文本到图表生成任务旨在将自然语言描述自动转换为结构化的图表代码,以提升技术文档与系统设计的效率。Mermaid-text-to-diagram数据集应运而生,由Mermaid Studio项目于2026年创建,其核心研究问题聚焦于训练超轻量级指令模型,以实现对Mermaid 11.14语法的精准理解与代码生成。该数据集严格依据官方文档构建,整合了Celiadraw与djds4rce等现有数据源,并辅以少量大语言模型生成的边缘案例,共计包含9913个经过验证的示例,覆盖流程图、序列图、类图等多种图表类型。作为首个针对Mermaid 11.14版本的专用训练集,它为轻量化模型的浏览器端部署提供了关键资源,推动了文本到可视化编程工具的发展。
当前挑战
该数据集致力于解决文本到Mermaid图表生成的领域挑战,其核心在于模型需准确解析自然语言中的复杂逻辑关系与空间约束,并映射为符合严格语法规范的图表代码。构建过程中的挑战首先体现在数据质量保障上,必须确保所有示例均遵循Mermaid 11.14的官方语法,并通过mermaid-cli工具进行渲染验证以排除解析错误。其次,数据多样性平衡构成另一难点,需在整合现有非生成数据的同时,通过大语言模型生成仅占1%比例的边缘案例,以覆盖新版本特性与复杂场景,避免生成数据引入噪声。此外,图表类型与复杂度分布不均,如流程图占比过半而旅程图仅有两例,可能影响模型对少数类别的泛化能力。
常用场景
经典使用场景
在自然语言处理与软件工程交叉领域,文本到图表的自动生成技术正逐渐成为提升文档编写效率的关键工具。Mermaid-text-to-diagram数据集作为专门针对Mermaid 11.14语法规范的训练资源,其最经典的使用场景在于微调轻量级指令模型,例如Qwen3.5-0.8B,以实现从自然语言描述到标准化Mermaid图表代码的精准转换。该数据集覆盖流程图、序列图、类图等多种图表类型,并包含从简单到高度复杂的节点结构,为模型提供了全面且多样化的学习样本,从而支持在浏览器环境等资源受限场景下的高效部署与应用。
解决学术问题
该数据集致力于解决自然语言理解与代码生成交叉研究中的核心挑战,即如何将非结构化的文本描述准确映射为结构化的图表定义语言。通过提供近万条经过严格验证的Mermaid 11.14示例,它有效应对了模型训练中数据稀缺、语法一致性不足以及边缘案例覆盖不全等常见学术问题。其意义在于为超轻量级模型(参数小于10亿)的指令微调建立了高质量基准,推动了低资源环境下文本到图表生成技术的可复现性与泛化能力研究,并为多模态文档自动化生成领域的理论探索提供了坚实的数据支撑。
实际应用
在实际应用层面,该数据集支撑的模型能够显著简化技术文档、系统设计图纸以及教育材料的创建流程。开发者或技术写作者仅需输入自然语言描述,即可自动生成符合Mermaid 11.14规范的图表代码,直接嵌入Markdown文档或在线协作平台中。这不仅大幅降低了手动编写图表语法的门槛与时间成本,还确保了图表输出的标准化与可维护性,广泛应用于软件架构可视化、业务流程建模、数据库关系展示以及教学演示等场景,提升了团队协作效率与知识传递的准确性。
数据集最近研究
最新研究方向
在文本到图表生成领域,Mermaid文本到图表数据集正推动着轻量级指令微调模型的前沿探索。该数据集严格遵循Mermaid 11.14.0官方规范,整合了流程图、序列图、类图等多种图表类型的近万条验证样本,其中约99%为非大语言模型生成的现有数据,确保了语法准确性与渲染可靠性。当前研究聚焦于利用此类高质量数据集,训练参数少于10亿的超轻量级模型,以实现高效的浏览器端部署,满足实时图表生成需求。这一方向与低资源环境下的智能文档自动化趋势紧密相连,通过覆盖复杂子图、样式设计等边缘案例,提升了模型在多样化场景下的鲁棒性,为可视化编程和交互式设计工具的发展提供了关键数据支撑。
以上内容由遇见数据集搜集并总结生成


