MiDe-22 Dataset
收藏github2022-12-21 更新2024-05-31 收录
下载链接:
https://github.com/avaapm/mide22
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含10,348条推文,其中5,284条为英文,5,064条为土耳其文。这些推文涵盖了俄罗斯-乌克兰战争、COVID-19大流行、难民问题以及其他杂项事件。数据集中的每条推文都附有三个虚假信息标签。由于遵循Twitter的条款和条件,本数据集发布的是推文ID而非直接的推文内容。
This dataset comprises 10,348 tweets, including 5,284 in English and 5,064 in Turkish. These tweets cover topics such as the Russia-Ukraine war, the COVID-19 pandemic, refugee issues, and other miscellaneous events. Each tweet in the dataset is accompanied by three misinformation labels. In compliance with Twitter's terms and conditions, the dataset releases tweet IDs rather than the direct content of the tweets.
创建时间:
2022-10-12
原始信息汇总
MiDe-22 Dataset概述
数据集内容
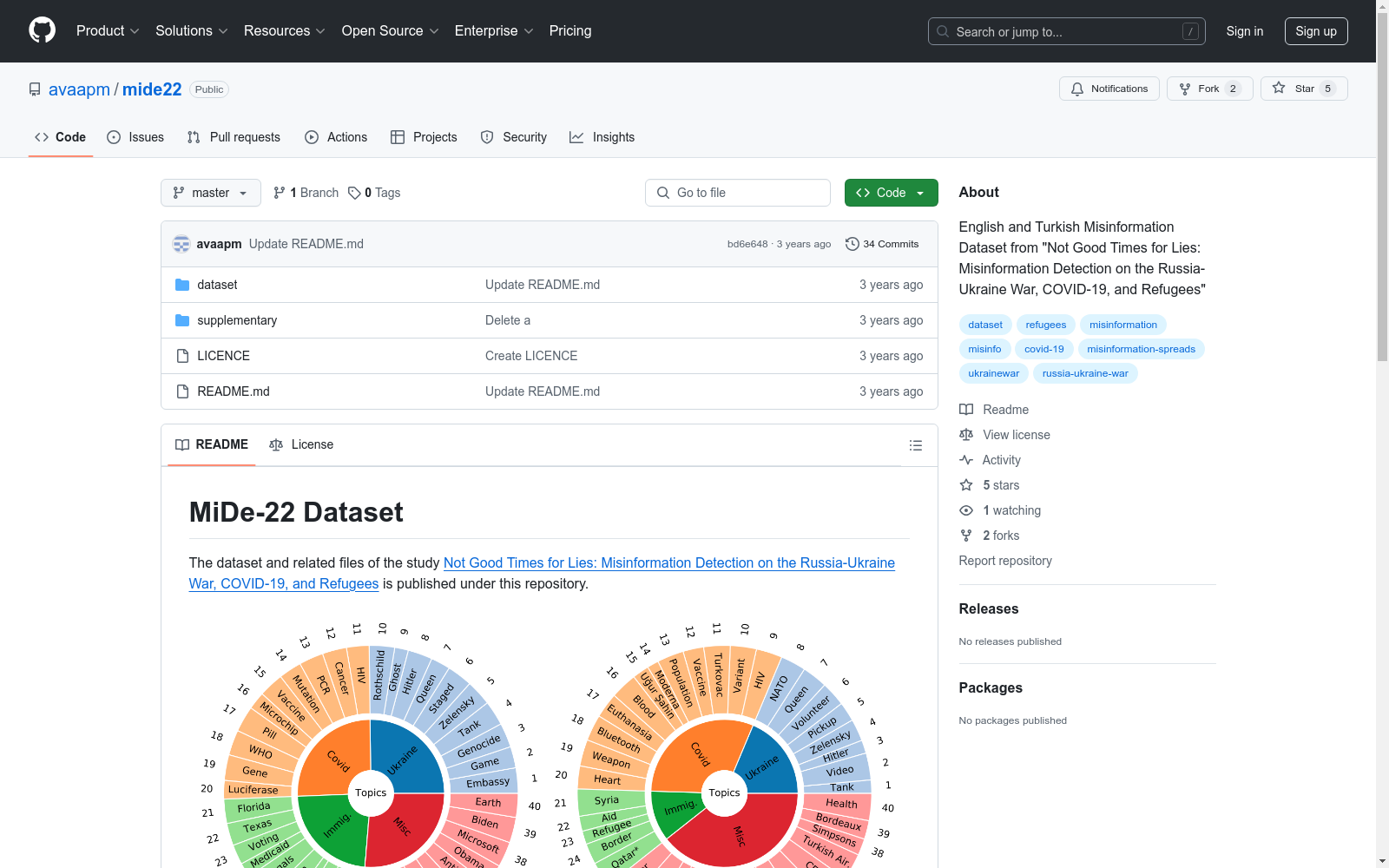
- 数据集大小: 包含10,348条推文,其中5,284条为英文,5,064条为土耳其文。
- 主题覆盖: 数据集涵盖了俄罗斯-乌克兰战争、COVID-19大流行、难民问题以及其他杂项事件。
- 标签信息: 每条推文附带三个错误信息标签:True(真实)、False(虚假)、Other(其他)。
- 数据格式: 由于遵循Twitter的条款和条件,仅发布推文ID,不直接发布推文内容。
数据集结构
数据集文件的列信息如下:
| 列名 | 描述 |
|---|---|
| Topic | 推文主题:乌克兰、Covid、难民或杂项 |
| Event | 推文事件:英文为EN01-EN40,土耳其文为TR01-TR40 |
| Label | 推文标签:真实、虚假或其他 |
| Tweet_id | Twitter推文ID |
数据集分布
数据集中的推文按语言和主题的分布如下:
| 语言 | 主题 | 真实 | 虚假 | 其他 | 总计 |
|---|---|---|---|---|---|
| EN | 乌克兰<br>Covid<br>难民<br>杂项<br>总计 | 320<br>167<br>94<br>146<br>727 | 393<br>514<br>328<br>494<br>1,729 | 618<br>663<br>796<br>751<br>2,828 | 1,331<br>1,344<br>1,218<br>1,391<br>5,284 |
| TR | 乌克兰<br>Covid<br>难民<br>杂项<br>总计 | 129<br>190<br>61<br>289<br>669 | 338<br>558<br>202<br>634<br>1,732 | 477<br>816<br>298<br>1,072<br>2,663 | 944<br>1,564<br>561<br>1,995<br>5,064 |
引用信息
若使用此数据集,请引用以下论文:
bibtex @misc{toraman2022good, title={Not Good Times for Lies: Misinformation Detection on the Russia-Ukraine War, COVID-19, and Refugees}, author={Cagri Toraman and Oguzhan Ozcelik and Furkan Şahinuç and Fazli Can}, year={2022}, eprint={2210.05401}, archivePrefix={arXiv}, primaryClass={cs.SI} }
搜集汇总
数据集介绍
构建方式
MiDe-22数据集通过收集与俄罗斯-乌克兰战争、COVID-19疫情、难民问题及其他杂项事件相关的推文构建而成。数据集包含10,348条推文,其中5,284条为英文,5,064条为土耳其文。每条推文均标注了三个可能的标签:真实、虚假或其他。为确保符合Twitter的使用条款,数据集仅提供推文ID而非具体内容。推文按主题和事件分类,并通过详细的表格展示了各类别下的推文分布情况。
特点
MiDe-22数据集的特点在于其多语言性和广泛的主题覆盖范围。数据集不仅涵盖了当前全球热点话题,如战争、疫情和难民问题,还通过详细的标签系统对推文的真实性进行了分类。此外,数据集的推文分布统计表为研究者提供了清晰的类别分布信息,便于进行针对性的分析和研究。
使用方法
使用MiDe-22数据集时,研究者需通过推文ID从Twitter平台获取具体推文内容。数据集提供了推文的主题、事件和标签信息,可用于训练和测试虚假信息检测模型。通过分析不同语言和主题下的推文分布,研究者可以深入探讨虚假信息在不同语境中的传播模式及其影响。引用该数据集时,需参考提供的文献引用格式。
背景与挑战
背景概述
MiDe-22数据集由Cagri Toraman等人于2022年创建,旨在研究社交媒体中的虚假信息检测问题。该数据集包含10,348条推文,涵盖俄乌战争、COVID-19疫情、难民问题等多个热点话题,并以英语和土耳其语为主。数据集的核心研究问题在于如何通过推文内容识别虚假信息,从而为社交媒体平台和研究者提供有效的工具和方法。该数据集在信息传播、社会计算等领域具有重要影响力,尤其是在全球性事件中虚假信息的传播机制研究方面提供了宝贵的数据支持。
当前挑战
MiDe-22数据集在构建和应用过程中面临多重挑战。首先,虚假信息的定义和标注具有主观性,不同研究者对虚假信息的判断标准可能存在差异,这可能导致数据集标签的不一致性。其次,推文内容的多样性和复杂性增加了数据清洗和预处理的难度,尤其是在多语言环境下,语言差异和文化背景可能影响虚假信息的识别效果。此外,由于数据集仅提供推文ID而非原始内容,研究者需依赖Twitter API获取推文内容,这可能导致数据获取的不完整性和时效性问题。最后,虚假信息的动态性和快速传播特性要求数据集不断更新,以保持其在实际应用中的有效性。
常用场景
经典使用场景
MiDe-22数据集在社交媒体分析领域具有重要应用,尤其是在虚假信息检测方面。该数据集包含了关于俄乌战争、COVID-19疫情、难民问题等多个热点话题的推文,涵盖了英语和土耳其语两种语言。研究人员可以通过分析这些推文的内容和标签,构建和训练机器学习模型,以识别和分类虚假信息。这一数据集为研究社交媒体中的信息传播和虚假信息扩散提供了丰富的数据支持。
解决学术问题
MiDe-22数据集解决了社交媒体中虚假信息检测的关键问题。通过提供大量标注的推文数据,研究人员可以深入探讨虚假信息的传播机制、识别特征及其对社会的影响。该数据集不仅帮助学术界理解虚假信息的生成和传播模式,还为开发高效的检测算法提供了实验基础。其多语言和多主题的特性使得研究结果更具普适性和应用价值。
衍生相关工作
基于MiDe-22数据集,许多经典研究工作得以展开。例如,研究人员开发了多种基于深度学习的虚假信息检测模型,利用该数据集进行训练和验证。此外,该数据集还促进了跨语言虚假信息检测的研究,推动了多语言自然语言处理技术的发展。这些研究成果不仅提升了虚假信息检测的准确性和效率,还为相关领域的进一步研究提供了宝贵的参考。
以上内容由遇见数据集搜集并总结生成


