google/civil_comments
收藏Hugging Face2024-01-25 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/google/civil_comments
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含来自Civil Comments平台的公开评论,该平台是一个独立新闻网站的评论插件。这些评论创建于2015年至2017年之间,出现在全球大约50个英文新闻网站上。当Civil Comments在2017年关闭时,他们选择将这些公开评论保存在一个持久的开放档案中,以便未来的研究使用。原始数据包括公开评论文本、一些相关的元数据(如文章ID、时间戳和评论者生成的“文明”标签),但不包括用户ID。Jigsaw通过添加额外的毒性标签和身份提及标签扩展了这个数据集。该数据集是Jigsaw在Kaggle上发布的“毒性分类中的无意偏见”挑战中使用的数据的精确复制品。该数据集及其基础评论文本均以CC0许可证发布。
This dataset contains public comments sourced from the Civil Comments platform, a comment plugin for independent news websites. These comments were created between 2015 and 2017, and appeared on approximately 50 English-language news websites worldwide. When Civil Comments shut down in 2017, they opted to preserve these public comments in a permanent open archive for future research use. The original dataset includes public comment text, associated metadata such as article IDs, timestamps, and commenter-generated "civil" labels, but excludes user IDs. Jigsaw expanded this dataset by adding additional toxicity labels and identity mention labels. This dataset is an exact replica of the data used in Jigsaw's "Unintended Bias in Toxicity Classification" challenge hosted on Kaggle. Both this dataset and the underlying comment text are released under the CC0 license.
提供机构:
google
原始信息汇总
数据集概述
数据集基本信息
- 名称: Civil Comments
- 许可证: CC0-1.0
- 标签: toxic-comment-classification
- 任务类别: text-classification
- 任务ID: multi-label-classification
数据集结构
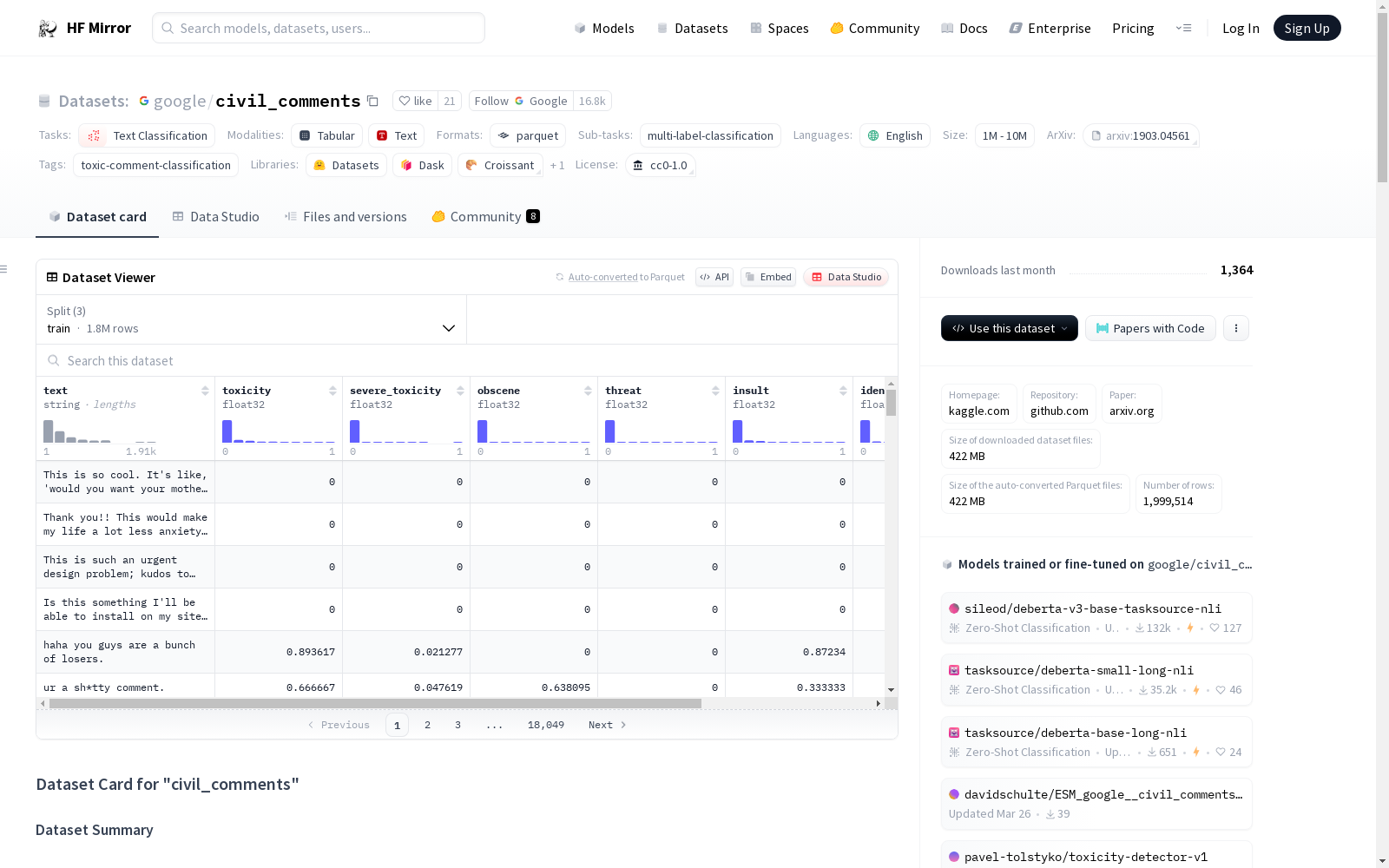
数据特征
- text: 字符串类型
- toxicity: 浮点数类型 (float32)
- severe_toxicity: 浮点数类型 (float32)
- obscene: 浮点数类型 (float32)
- threat: 浮点数类型 (float32)
- insult: 浮点数类型 (float32)
- identity_attack: 浮点数类型 (float32)
- sexual_explicit: 浮点数类型 (float32)
数据分割
- 训练集: 1804874 样本
- 验证集: 97320 样本
- 测试集: 97320 样本
数据集创建
许可证信息
- 许可证: CC0 1.0
引用信息
@article{DBLP:journals/corr/abs-1903-04561, author = {Daniel Borkan and Lucas Dixon and Jeffrey Sorensen and Nithum Thain and Lucy Vasserman}, title = {Nuanced Metrics for Measuring Unintended Bias with Real Data for Text Classification}, journal = {CoRR}, volume = {abs/1903.04561}, year = {2019}, url = {http://arxiv.org/abs/1903.04561}, archivePrefix = {arXiv}, eprint = {1903.04561}, timestamp = {Sun, 31 Mar 2019 19:01:24 +0200}, biburl = {https://dblp.org/rec/bib/journals/corr/abs-1903-04561}, bibsource = {dblp computer science bibliography, https://dblp.org} }
搜集汇总
数据集介绍
构建方式
Civil Comments数据集的构建是基于独立新闻网站上的公开评论,这些评论来自于2015至2017年间,涵盖大约50个英语新闻网站。数据集的原始版本包含评论文本、相关元数据以及评论者生成的'文明度'标签,但不含用户ID。Jigsaw团队在此基础上增加了关于毒性和身份提及的额外标签,形成了现在的数据集。数据集通过CC0协议发布,确保了其使用的开放性。
特点
该数据集的特点在于其丰富的注释信息,不仅包含评论文本,还提供了毒性、严重毒性、粗俗、威胁、侮辱、身份攻击和性明确等维度的标签。这些标签以浮点数形式存在,为研究者和开发人员提供了细粒度的分析可能。数据集分为训练集、验证集和测试集,总计超过180万条评论,为毒性评论分类任务提供了充足的资源。
使用方法
使用Civil Comments数据集时,用户可以从HuggingFace的仓库中下载经过预处理的训练、验证和测试数据文件。数据以JSON格式存储,每个实例包含一条评论和多个标签。用户可以根据具体的任务需求,选择适当的模型进行训练和评估。由于数据集遵循CC0协议,用户在使用时无需担心版权问题,可以自由地进行研究和开发工作。
背景与挑战
背景概述
Civil Comments数据集源自于2015至2017年间,独立新闻网站所使用的评论插件平台Civil Comments的公共评论档案。该数据集包含了大约50个英语新闻网站上的评论,旨在为未来研究提供开放存档。Jigsaw团队对该数据集进行了扩展,增添了毒性和身份提及的额外标签。此数据集的创建,不仅体现了对网络评论内容进行分析的需求,也反映了在文本分类任务中对无意偏见进行研究的重视。数据集的发布,为毒性评论分类和无意图偏见分析领域提供了宝贵的资源,对相关研究领域产生了深远的影响。
当前挑战
在构建Civil Comments数据集的过程中,研究团队面临了多方面的挑战。首先,如何确保注释的质量和一致性是一项关键挑战,特别是在涉及主观性较强的毒性标签时。其次,数据集构建过程中还需处理个人敏感信息的问题,以保护评论者的隐私。此外,数据集可能存在的偏见问题也是使用该数据集时必须考虑的挑战,这可能会影响模型的无意偏见和公平性。在使用该数据集进行模型训练和评估时,研究者需谨慎处理这些挑战,以确保得出的结论具有可靠性和有效性。
常用场景
经典使用场景
在文本分类领域中,'Civil Comments' 数据集的典型应用场景是对网络评论进行 toxicity 检测,以识别和过滤出含有侮辱、威胁、色情等不良内容的评论,从而为网站维护一个健康文明的交流环境。
实际应用
在实际应用中,'Civil Comments' 数据集被广泛应用于社交媒体平台、新闻评论区和在线论坛等,帮助这些平台自动识别和过滤有害内容,提高用户交流的质量和安全性。
衍生相关工作
基于'Civil Comments' 数据集,学术界已经衍生出一系列相关工作,包括但不限于毒性度量的改进、偏见检测算法的研究以及多语言毒性分类模型的开发,进一步推动了文本分类和自然语言处理领域的发展。
以上内容由遇见数据集搜集并总结生成


