AgentHallu
收藏github2026-01-17 更新2026-02-11 收录
下载链接:
https://github.com/liuxuannan/AgentHallu
下载链接
链接失效反馈官方服务:
资源简介:
AgentHallu是一个全面的基准测试数据集,旨在支持基于LLM的代理的自动幻觉归因研究。它包含693个高质量轨迹,涵盖7种代理框架和5个领域(世界知识、科学、数学、通用助手和工具使用)。数据集还包括一个幻觉分类法,分为5个类别(规划、检索、推理、人机交互和工具使用)和14个子类别,以及由人类策划的多级注释,涵盖二进制标签、幻觉责任步骤和因果解释。
AgentHallu is a comprehensive benchmark dataset designed to support automated hallucination attribution research for LLM-based agents. It contains 693 high-quality trajectories spanning 7 agent frameworks and 5 domains: world knowledge, science, mathematics, general-purpose assistant, and tool use. The dataset also includes a hallucination taxonomy, which is divided into 5 categories (planning, retrieval, reasoning, human-machine interaction, and tool use) and 14 subcategories, as well as human-curated multi-level annotations covering binary labels, hallucination responsibility steps, and causal explanations.
创建时间:
2026-01-11
原始信息汇总
AgentHallu 数据集概述
数据集基本信息
- 数据集名称: AgentHallu: Benchmarking Automated Hallucination Attribution of LLM-based Agents
- 主页地址: https://liuxuannan.github.io/AgentHallu.github.io/
- 论文地址: https://arxiv.org/abs/2601.06818
- 数据地址: 未提供具体链接(页面显示为“🤗 Data”但无链接)
- 许可协议: CC-BY 4.0 (https://creativecommons.org/licenses/by/4.0/)
研究背景与目标
- 核心任务: 提出并支持“基于LLM的智能体自动幻觉归因”这一新研究任务。
- 问题定义: 旨在识别导致幻觉产生的具体步骤并解释原因。
- 研究动机: 解决多步推理工作流中的幻觉诊断问题,与单轮响应中的幻觉检测不同,需要定位初始偏差发生的步骤。
数据集内容与规模
- 轨迹数量: 693条高质量轨迹。
- 覆盖范围:
- 智能体框架: 7种。
- 领域: 5个,包括世界知识、科学、数学、通用助手和工具使用。
幻觉分类体系
- 主要类别: 5类,包括规划、检索、推理、人机交互和工具使用。
- 子类别: 14个。
标注信息
- 标注级别: 多级人工标注。
- 标注内容:
- 二进制标签。
- 幻觉责任步骤。
- 因果解释。
使用说明
- 代码与数据: 页面提示“Code and data will be coming soon!”,目前尚未发布。
引用信息
- 引用格式: 提供BibTeX格式引用条目。
- 预印本: arXiv:2601.06818。
- 发表年份: 2026。
搜集汇总
数据集介绍
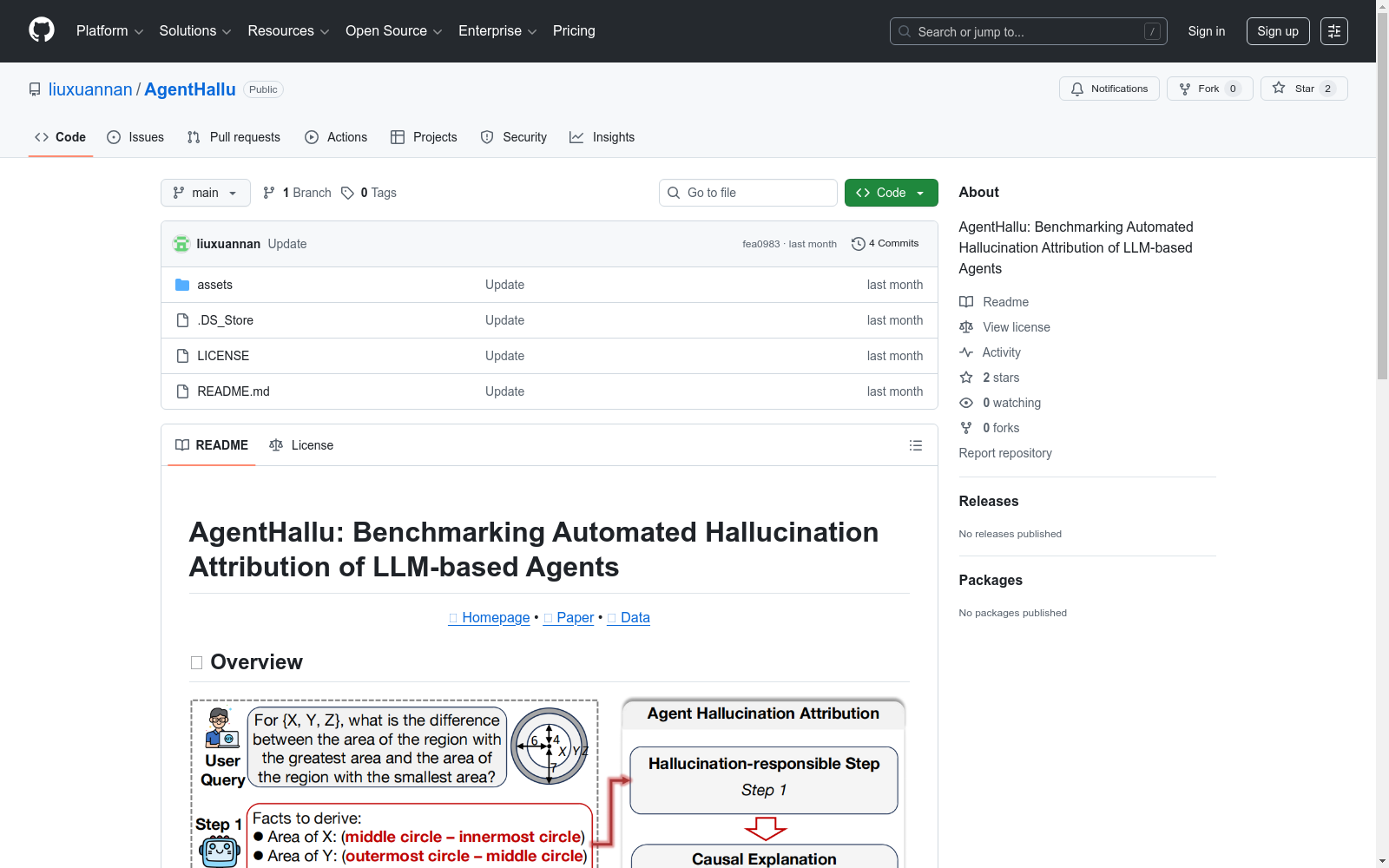
构建方式
在大型语言模型驱动的智能体日益普及的背景下,多步推理过程中的幻觉传播问题成为制约其可靠性的关键瓶颈。为系统研究此问题,AgentHallu基准数据集应运而生。其构建过程严谨而系统,研究者首先精心设计了涵盖世界知识、科学、数学、通用助理及工具使用五大领域的多样化任务场景。在此基础上,数据集汇集了基于七种主流智能体框架生成的693条高质量任务轨迹。每条轨迹均经由人工专家进行多层次精细标注,不仅包含二元幻觉标签,更关键地标注了导致幻觉的具体责任步骤,并提供了因果解释,从而构建了一个层次分明、注释详实的评估体系。
使用方法
该数据集为评估和提升基于大型语言模型的智能体的可靠性提供了标准化的测试平台。研究人员可利用AgentHallu来系统评估不同模型或方法在自动化幻觉归因任务上的性能,即模型能否准确识别导致最终幻觉的具体推理步骤,并给出合理解释。使用过程中,开发者可以加载提供的轨迹数据及其对应的人工标注(包括二元标签、责任步骤和因果解释),以此作为基准真值来训练或测试各自的归因模型。通过分析模型在五大幻觉类别及不同任务领域上的表现,能够精准定位智能体工作流程中的薄弱环节,从而推动更具可解释性和鲁棒性的智能体架构发展。
背景与挑战
背景概述
随着基于大语言模型的智能体在多步骤推理任务中的广泛应用,其在中间步骤产生的幻觉风险会沿推理轨迹传播,从而严重影响整体可靠性。为应对这一挑战,研究者于2026年提出了AgentHallu基准数据集,由Xuannan Liu等学者联合构建,旨在推动自动化幻觉归因这一新兴研究方向。该数据集涵盖了世界知识、科学、数学、通用助手及工具使用等五个领域,包含693条高质量轨迹,并提供了多层次的人工标注,为核心研究问题——即精准定位并解释多步工作流中幻觉产生的初始步骤——提供了系统化的评估框架,对提升智能体可信度具有重要影响力。
当前挑战
在领域问题层面,AgentHallu致力于解决多步骤智能体工作流中的幻觉归因挑战,这要求模型不仅能检测幻觉的存在,还需在复杂的序列决策中识别引发错误的特定步骤及其因果机制,其难度远超单轮对话的幻觉检测。在构建过程中,研究团队面临高质量轨迹收集与标注的严峻考验,需跨越七种不同智能体框架与多样领域,确保幻觉分类体系涵盖规划、检索、推理、人机交互及工具使用等五大类别与十四种子类,同时维持多级注释的一致性与解释深度,这些工作对标注的专业性与规模提出了极高要求。
常用场景
经典使用场景
在大型语言模型(LLM)驱动的智能代理领域,AgentHallu数据集为评估多步推理流程中的幻觉溯源问题提供了标准化的测试平台。该数据集通过涵盖世界知识、科学、数学、通用助手和工具使用等五个领域,以及七种主流代理框架的693条高质量轨迹,使研究者能够系统分析代理在复杂任务执行过程中,幻觉如何在中间步骤产生并沿轨迹传播。这一场景典型应用于开发自动化方法,以精准定位导致幻觉的初始步骤,并解释其成因,从而提升多步工作流的可靠性。
解决学术问题
AgentHallu数据集致力于解决智能代理研究中一个关键挑战:多步推理中的幻觉归因问题。传统研究多聚焦于单轮响应的幻觉检测,而该数据集通过引入细粒度的幻觉分类(包括规划、检索、推理、人机交互和工具使用五大类别及14个子类)以及人工标注的多层次注释(如二元标签、责任步骤和因果解释),为自动化幻觉溯源任务提供了结构化基准。这填补了学术空白,推动了从静态检测到动态溯源的范式转变,有助于深入理解幻觉在序列决策中的传播机制,并为开发更可靠的代理系统奠定理论基础。
实际应用
在实际应用中,AgentHallu数据集为构建高可靠性的LLM代理系统提供了评估工具。例如,在自动化客服、科研辅助或金融分析等需要多步工具调用的场景中,代理可能因错误检索或推理偏差而产生幻觉,导致决策失误。利用该数据集,开发者可以测试并优化代理的幻觉溯源能力,从而在真实工作流中及时识别并纠正错误步骤。这不仅增强了代理在医疗诊断、法律咨询等高风险领域的适用性,也为工业界提供了可部署的监控与调试方案,以提升智能系统的安全性与信任度。
数据集最近研究
最新研究方向
在大型语言模型(LLM)驱动的智能体日益普及的背景下,其多步推理过程中产生的幻觉问题已成为制约可靠性的关键瓶颈。AgentHallu基准应运而生,专注于自动化幻觉归因这一前沿任务,旨在精准定位导致幻觉产生的具体步骤并提供因果解释。该数据集涵盖七个主流智能体框架和五个核心领域,通过多层级人工标注构建了系统的幻觉分类体系。相关研究正推动智能体在知识密集型应用中的可信部署,为缓解幻觉传播、提升决策透明度提供了重要评估工具,对促进负责任人工智能发展具有深远意义。
以上内容由遇见数据集搜集并总结生成


