Fatima0923/Automated-Personality-Prediction
收藏Hugging Face2024-02-07 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Fatima0923/Automated-Personality-Prediction
下载链接
链接失效反馈官方服务:
资源简介:
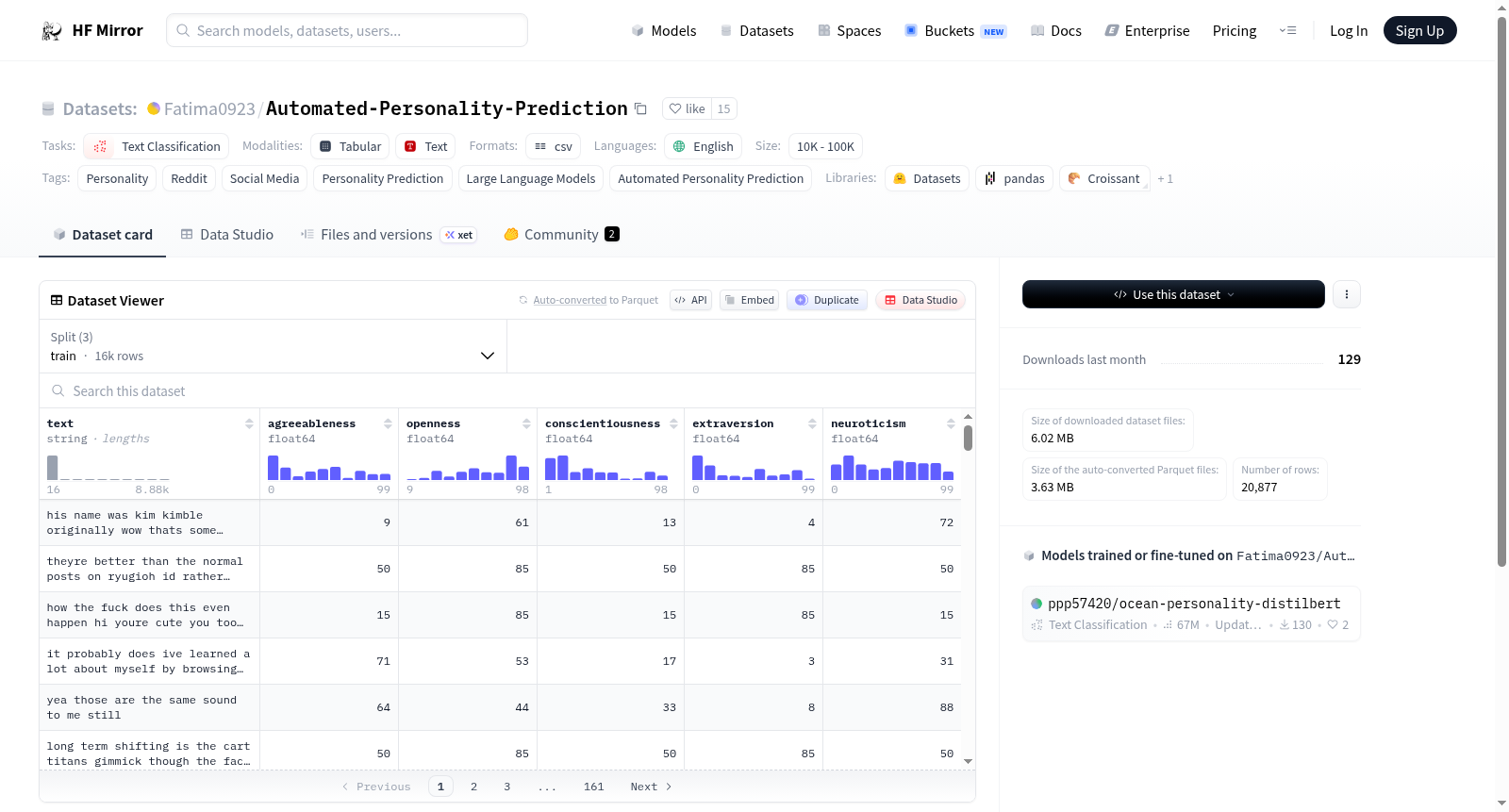
该数据集名为PANDORA,是从https://psy.takelab.fer.hr/datasets/all/pandora/获取的。PANDORA数据集是唯一一个包含多个个性模型相关信息的数据库,包括Reddit评论及其对应的Big Five Traits、MBTI值和Enneagrams分数,覆盖了超过10,000名用户。当前数据集是PANDORA的一个子集,仅包含与Big Five Traits相关的Reddit评论,这些评论来自1608个用户,并且已经过预处理。
The dataset named PANDORA is acquired from https://psy.takelab.fer.hr/datasets/all/pandora/. As the only database housing information related to multiple personality models, PANDORA includes Reddit comments paired with their corresponding Big Five Trait scores, MBTI types and Enneagram scores, covering more than 10,000 users. The current dataset is a subset of PANDORA, which exclusively contains Reddit comments associated with Big Five Traits from 1608 users, and has been preprocessed.
提供机构:
Fatima0923
原始信息汇总
数据集概述
任务类别
- 文本分类
语言
- 英语
标签
- 个性
- 社交媒体
- 个性预测
- 大型语言模型
- 自动个性预测
名称
- Personality-Texts
大小类别
- 10K<n<100K
来源
- 数据集名为PANDORA,来源于https://psy.takelab.fer.hr/datasets/all/pandora/。PANDORA数据集包含多个个性模型的相关信息,包括超过10,000名用户的Reddit评论及其对应的五大特质、MBTI值和九型人格评分。
数据集描述
- 该数据集是PANDORA的一个子集,专注于五大特质。该子集包含1608名用户的预处理英语评论及其五大特质评分。
搜集汇总
数据集介绍
构建方式
在人格计算研究领域,数据集的构建需兼顾规模与深度。该数据集源自PANDORA项目,该项目系统性地采集了Reddit平台用户的公开评论,并依据心理学理论框架,为每位用户标注了包括大五人格特质在内的多维度人格分数。构建过程中,研究者从原始数据集中筛选出1608名用户的英文评论,并进行了文本预处理,确保数据质量与后续分析的可行性,从而形成了一个专注于大五人格特质预测的、结构清晰的文本集合。
特点
该数据集的核心特点在于其心理学基础的坚实性与数据来源的生态效度。它并非简单收集文本,而是将Reddit用户的自然语言表达与经过标准化评估的大五人格分数精确关联,提供了真实社交语境下的行为语言样本。数据规模适中,覆盖了超过十万条评论,确保了统计分析的可靠性,同时聚焦于单一人格模型(大五特质),避免了多模型混杂带来的解释复杂性,为基于文本的人格计算研究提供了高纯度的实验材料。
使用方法
在应用层面,该数据集主要服务于基于机器学习或深度学习的人格特质自动预测任务。研究者可将预处理后的用户评论作为输入特征,对应的大五人格分数作为预测标签,用于训练分类或回归模型。典型流程包括文本向量化、模型训练与验证。该数据集尤其适合探索语言模式与人格特质之间的关联,或作为基准测试集,用于评估不同自然语言处理模型在人格计算这一细分类别上的性能表现。
背景与挑战
背景概述
在心理学与计算社会科学的交叉领域,人格预测研究长期致力于通过个体行为数据推断其稳定心理特质。Fatima0923/Automated-Personality-Prediction数据集源于PANDORA项目,该项目由克罗地亚萨格勒布大学电气工程与计算学院Takelab研究团队构建,并于近年公开发布。该数据集聚焦于大五人格模型,从Reddit平台提取了1608名用户的英文评论及其对应的人格分数,旨在为自动化人格预测提供高质量的文本标注资源。其核心研究问题在于探索如何利用社交媒体文本数据,通过计算模型实现人格特质的精准量化,这一努力推动了心理测量学与自然语言处理技术的深度融合,为人机交互、个性化推荐等应用领域奠定了数据基础。
当前挑战
自动化人格预测领域面临的核心挑战在于人格特质本身的主观性与复杂性,大五人格等模型虽具结构效度,但其基于文本的表征往往受到语境、文化及表达风格的干扰,导致预测模型易出现过拟合或泛化能力不足的问题。在数据集构建过程中,研究者需应对多方面的困难:Reddit评论的匿名性与非结构化特性使得数据清洗与对齐工作繁重;人格分数的标注依赖于用户的自我报告,可能存在社会赞许性偏差或测量误差;此外,为保护用户隐私,数据脱敏与伦理审查流程也增加了构建的复杂度。这些挑战共同制约着数据集的规模扩展与质量提升。
常用场景
经典使用场景
在计算心理学与自然语言处理交叉领域,该数据集为自动化人格预测研究提供了关键资源。其经典使用场景集中于基于社交媒体文本的人格特质分析,研究者利用Reddit用户的评论数据,结合大五人格模型,训练机器学习或深度学习模型以从语言模式中推断个体的人格特征。这一过程通常涉及文本预处理、特征提取与分类任务,为探索语言与人格间的关联提供了实证基础。
解决学术问题
该数据集有效解决了人格计算研究中数据稀缺与模型泛化难题。通过提供大规模、标注详实的社交媒体文本,它支持研究者验证人格特质与语言表达之间的理论关联,如大五人格中的外向性、神经质等维度如何反映于用词习惯与情感倾向。其意义在于推动了自动化人格评估方法的标准化,促进了心理学与人工智能的跨学科融合,为个性化服务与心理健康应用奠定了数据基础。
衍生相关工作
围绕该数据集,已衍生出一系列经典研究工作。早期研究侧重于基于传统机器学习方法的人格预测模型,如使用逻辑回归或支持向量机分析文本特征。随着深度学习发展,后续工作引入了循环神经网络与注意力机制,以捕捉语言中的时序依赖关系。近年来,大语言模型的兴起进一步推动了基于预训练架构的细粒度人格推断,这些工作共同深化了对语言人格关联的理解,并拓展了模型在跨平台与跨文化场景中的适用性。
以上内容由遇见数据集搜集并总结生成


