AVQA-Hard, Music-AVQA-Hard
收藏arXiv2025-09-22 更新2025-09-24 收录
下载链接:
https://github.com/naver-ai/LLaVA-AV-SSM
下载链接
链接失效反馈官方服务:
资源简介:
AVQA-Hard 和 Music-AVQA-Hard 是针对现有视频问答基准测试中存在的视觉捷径问题进行筛选后的数据集。这些数据集旨在强调音频信息的重要性,并推动视频问答模型在音频理解和时序整合方面的研究。数据集的构建过程涉及对现有视频问答数据集进行单帧推理测试,并筛选出那些不能仅通过视觉信息就能解决的项目,从而构成对音频信息敏感的难题集。这些数据集的应用领域在于评估和改进视频问答模型的音频理解和时序整合能力,以期更好地反映实际应用场景中用户对视频内容的理解需求。
AVQA-Hard and Music-AVQA-Hard are datasets curated to mitigate the visual shortcut problems prevalent in existing video question answering (VideoQA) benchmarks. These datasets are designed to emphasize the critical role of audio information and promote research on audio comprehension and temporal integration for video QA models. The construction process entails performing single-frame inference tests on existing video QA datasets, and screening out instances that cannot be resolved using only visual cues, thereby forming a challenging problem set sensitive to audio information. These datasets serve to evaluate and enhance the audio understanding and temporal integration capabilities of video QA models, thereby better aligning with users' demands for comprehending video content in real-world application scenarios.
提供机构:
NAVER Cloud AI, KAIST AI
创建时间:
2025-09-22
原始信息汇总
LLaVA-AV-SSM 数据集概述
基本信息
- 数据集名称: LLaVA-AV-SSM
- 研究主题: 音频对现代视频大语言模型及其基准测试的重要性
- 状态: 预印本(arXiv:2509.17901),正在评审中
- 发布日期: 2025年9月22日
核心发现
- 现有视频理解基准测试大多可通过单帧图像解决,音频常被忽略且不影响性能
- 在标准测试集上音频带来的提升有限
- 在音频敏感的子集(AVQA-Hard、Music-AVQA-Hard)上音频起决定性作用
技术方案
- 基于LLaVA架构,增加语音/音频编码器
- 使用轻量级Mamba状态空间压缩器解决音频令牌爆炸问题
- 提出音频敏感评估方法
评估基准
- 主流测试套件: 音频贡献较小
- 定制化子集:
- AVQA-Hard
- Music-AVQA-Hard
相关资源
- 论文地址: https://arxiv.org/abs/2509.17901
- 作者: Geewook Kim, Minjoon Seo
搜集汇总
数据集介绍
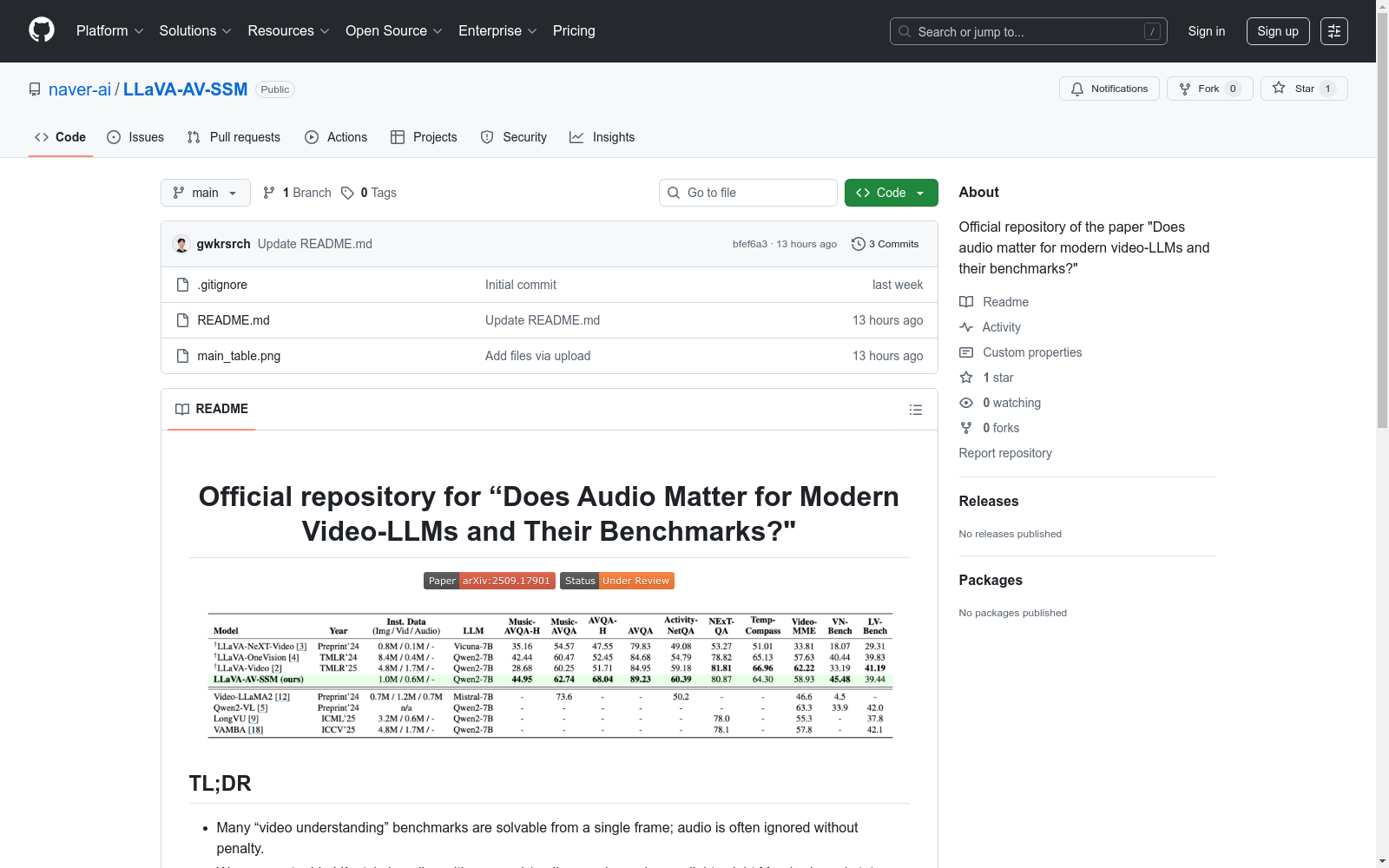
构建方式
在音视频问答研究领域,现有基准存在视觉捷径问题,导致音频模态的价值被低估。AVQA-Hard和Music-AVQA-Hard通过系统性筛选构建,首先利用GPT-4o对原始AVQA和Music-AVQA数据集中仅提供单帧图像(无音频)的样本进行推理测试,过滤掉约80%的AVQA和54%的Music-AVQA中仅凭视觉线索即可解答的样本。最终保留的样本要求模型必须结合音频信息与动态视觉上下文才能正确回答,从而确保数据集的音频敏感性。
特点
该数据集的核心特征在于其严格的音频依赖性设计。与通用视频问答基准不同,AVQA-Hard和Music-AVQA-Hard通过剔除单帧可解的样本,强制模型融合时空视觉信息与音频语义(如语音内容、环境声或音乐特征)。数据集覆盖对话理解、事件推理及音乐分析等多类场景,其中Music-AVQA-Hard特别强调对旋律、乐器音色等细粒度音频属性的辨识。这种设计有效避免了模型依赖视觉捷径,为评估音视频多模态模型的真实感知能力提供了可靠基准。
使用方法
研究者可通过加载标准音视频编码器(如Whisper音频编码器和SigLIP视觉编码器)提取特征,并采用时间对齐的交织策略将音频与视频令牌输入大语言模型。为应对长视频序列的令牌爆炸问题,建议搭配基于Mamba的周期性查询压缩器,以25倍比率将音频令牌从25Hz降至1Hz。评估时需对比纯视觉基线、非交织音频注入及交织音频注入三种策略的性能差异,重点关注模型在音频敏感任务上的提升幅度,从而验证音视频融合技术的有效性。
背景与挑战
背景概述
随着多模态大语言模型在视频理解领域的快速发展,AVQA-Hard与Music-AVQA-Hard数据集于2025年由NAVER Cloud AI与KAIST的研究团队联合提出,旨在解决当前视频问答评测中音频信息被系统性忽视的问题。该数据集基于原有AVQA和Music-AVQA基准,通过剔除仅凭单帧视觉信息即可解答的样本,构建了真正依赖音视频协同推理的挑战性子集。其核心研究问题聚焦于验证音频在视频语义理解中的不可替代性,推动了多模态模型从“视觉中心”向“视听均衡”范式的转变,对下一代视频大语言模型的评测标准产生了深远影响。
当前挑战
在解决领域问题层面,该数据集直面现有视频问答基准过度依赖视觉捷径的缺陷,要求模型具备跨模态时序对齐与音频语义提取能力,例如需理解对话内容、环境音效或音乐情感等非视觉线索。构建过程中的挑战包括:首先需通过大规模单帧探测实验精准识别并过滤可被视觉单独解决的样本,确保数据集的音频敏感性;其次需设计高效的音视频 token 压缩算法以应对长视频带来的序列建模压力,例如采用 Mamba 状态空间模型对高频音频流进行降维,避免 token 爆炸导致的计算瓶颈。
常用场景
经典使用场景
在视频多模态大语言模型(Video-LLM)的研究中,AVQA-Hard和Music-AVQA-Hard数据集被设计用于严格评估模型对音频信息的依赖能力。通过筛选掉仅凭单帧图像即可回答的问题项,这两个数据集强制模型必须结合视觉与音频线索进行综合分析,从而检验其真正的视听融合理解水平。此类评估场景常见于学术实验中,用于对比不同模型在音频敏感任务上的性能差异。
衍生相关工作
围绕该数据集衍生的经典工作包括LLaVA-AV-SSM模型架构,其通过引入轻量级Mamba状态空间模块压缩音频令牌,解决了长视频中音频序列爆炸问题。同时,研究社区进一步探索了双向Mamba(BiMamba)与注意力重采样器(Resampler)等变体,推动了高效跨模态序列建模技术的发展。这些工作为后续如Video-LLaMA2、VAMBA等模型提供了视听令牌压缩的理论与实践参照。
数据集最近研究
最新研究方向
在视听问答领域,AVQA-Hard与Music-AVQA-Hard数据集的提出标志着对视频大语言模型评估范式的革新。当前研究聚焦于揭示音频信息在视频理解中的关键作用,通过剔除可仅凭单帧视觉信息解答的样本,构建了真正依赖音频推理的硬核子集。前沿工作表明,传统基准如VideoMME或NExTQA因偏重视觉时序分析而难以体现音频价值,而新数据集则凸显了音频编码器与状态空间模型(如Mamba)结合的高效令牌压缩技术,为长视频多模态建模提供了线性复杂度解决方案。这一方向不仅推动了模型在真实场景下的视听融合能力评估,更引发了学术界对基准数据质量与模型实际应用差距的深入反思。
相关研究论文
- 1Does Audio Matter for Modern Video-LLMs and Their Benchmarks?NAVER Cloud AI, KAIST AI · 2025年
以上内容由遇见数据集搜集并总结生成


