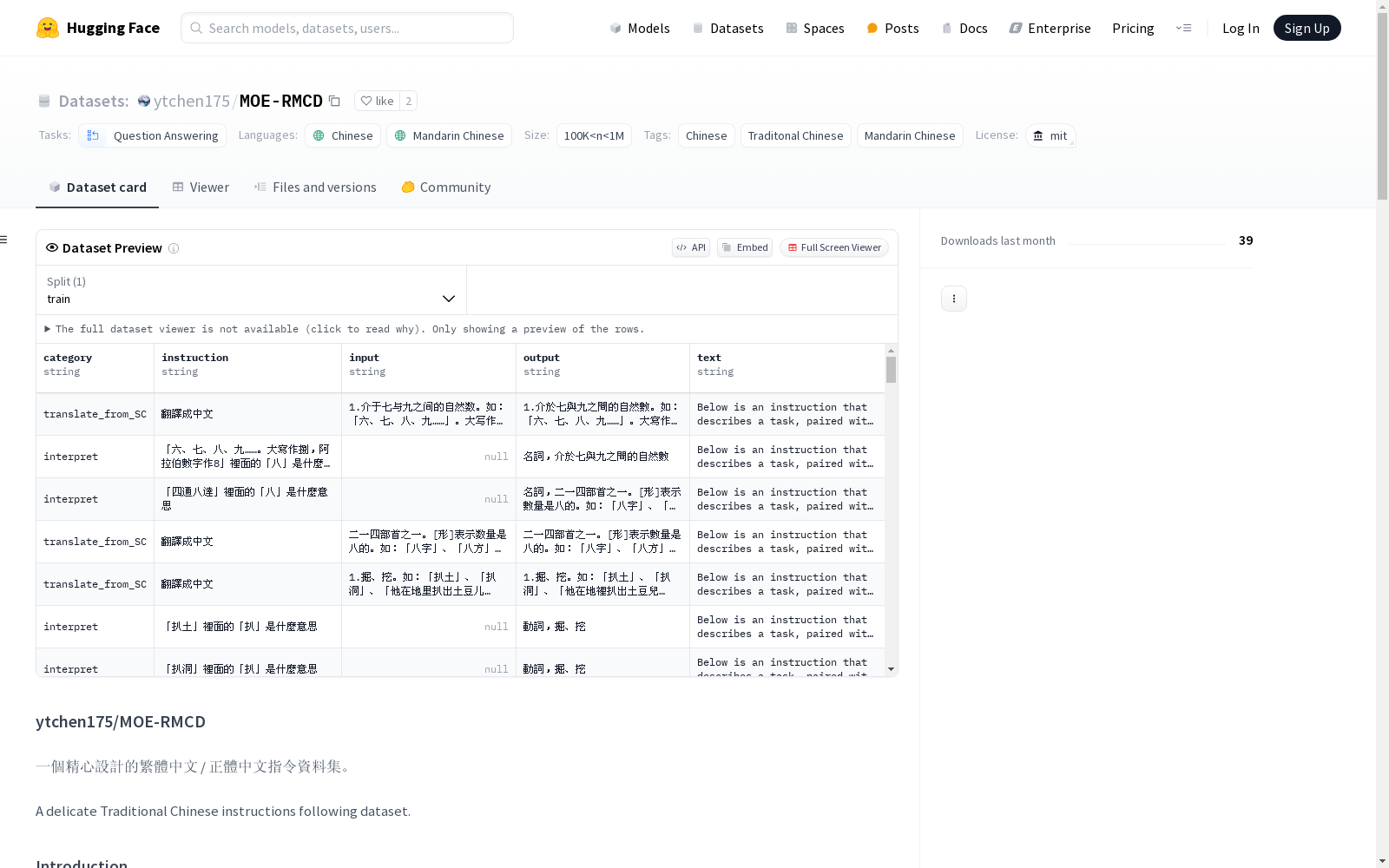
MOE-RMCD
收藏数据集概述
数据集名称
ytchen175/MOE-RMCD
数据集简介
「教育部重編國語辭典修訂本指令資料集」(Ministry of Education Revised Mandarin Chinese Dictionary Instruction Dataset,简称 MOE-RMCD),是由教育部的《重編國語辭典修訂本》为底所构建的指令资料集。
数据集内容
基于最大化利用原始资料潜在价值的想法,从中抽取出五大类任务:
- 詞語解釋
- 簡繁轉換
- 單句釋義
- 近似詞
- 反義詞
共計 36 万笔指令 (instructions)。
数据集范围
排除了过于罕见的字,只留下中日韩统一表意文字列表(CJK Unified Ideographs) 与 中日韩统一表意文字扩展区 A(CJK Unified Ideographs Extension A) 内的所有汉字。
数据集格式
使用 Alpaca 格式呈现此指令跟随数据集。
数据集详细信息
任务统计
| 任务 | 数量 |
|---|---|
| 詞語解釋 (interpret) | 171,097 |
| 簡繁轉換 (translate_from_SC) | 163,692 |
| 單句釋義 (POS) | 8,170 |
| 近似詞 (synonym) | 13,899 |
| 反義詞 (antonym) | 8,603 |
| 总笔数 (total) | 365,461 |
示例
-
簡繁轉換(translate_from_SC)
-
任务描述:以字符的层级而言,从繁体转到简体并没有问题,所以我们将原始语言为繁体中文的国语辞典的文本转换为简体,再作为此 instruction 的 input。
-
来源:国语辞典内无法被特别处理的文本。
-
数据示例 - 现代中文
Instruction:翻譯成中文 Input:自然数的开始。 Output:自然數的開始。
-
数据示例 - 无法被特别处理的文本
Instruction:翻譯成中文 Input:1.清洁。《红楼梦》第四四回:「那市卖的胭脂都不干净,颜色也薄。」《文明小史》第五二回...。 Output:1.清潔。《紅樓夢》第四四回:「那市賣的胭脂都不乾淨,顏色也薄。」《文明小史》第五二回...。
-
-
詞語解釋(interpret)
-
任务描述:解释词或给定句子求特定字的解释。
-
来源:根据国语辞典的「释义」拆分而成。
-
数据示例 - 词义
Instruction:解釋這個詞 Input:泵 Output:一種用以增加液體的壓力,用來移動液體的裝置,即是對流體作功的機械。也稱為「幫浦」。
-
数据示例 - 现代中文例句
Instruction:「你是不是背著我幹了什麼壞事?」裡面的「背」是什麼意思 Input:NaN Output:動詞,躲避、瞞著
-
数据示例 - 文言文例句
Instruction:「《詩經.小雅.常棣》:「妻子好合,如鼓瑟琴。」裡面的「合」是什麼意思 Input:NaN Output:形容詞,和諧、融洽
-
-
單句釋義(POS)
-
任务描述:列出给定词语与词性,要求解释使用时机。
-
来源:根据国语辞典的「释义」拆分而成。
-
数据示例 – 单句释义
Instruction:「旭」什麼時候可以做為這個詞性使用 Input:名詞 Output:剛升起的太陽。如:「朝旭」、「迎旭而舞」。
-
-
近似詞(synonym)
-
任务描述:列出给定词语的近似词。
-
来源:国语辞典的「相似词」。
-
数据示例 – 近似词
Instruction:舉出 1 個近似詞 Input:大都 Output:多數
-
-
反義詞(antonym)
-
任务描述:列出给定词语的反义词。
-
来源:国语辞典的「相反词」。
-
数据示例 – 反义词
Instruction:舉出 4 個反義詞 Input:寬大 Output:狹小、窄小、嚴厲、苛嚴
-