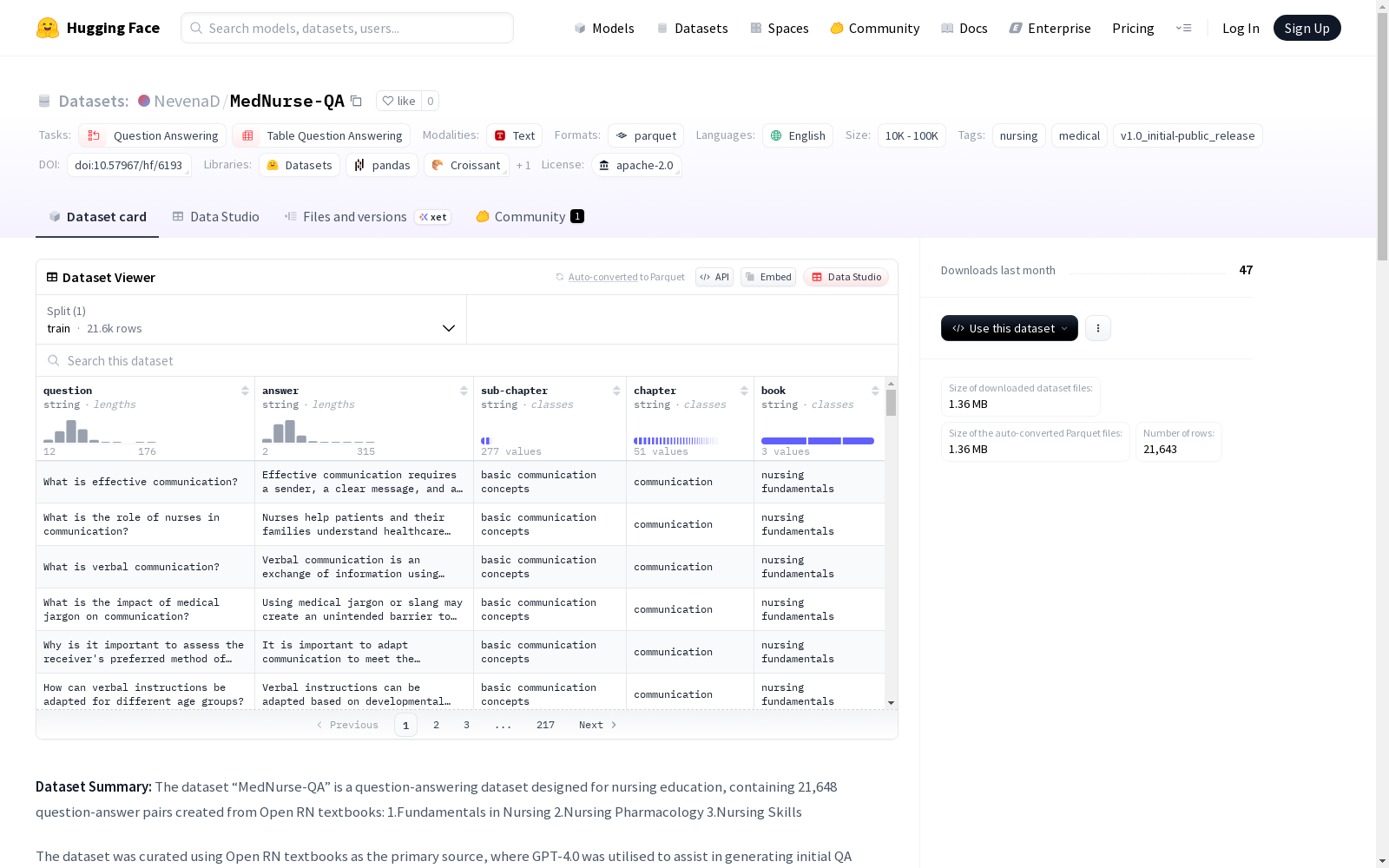
MedNurse-QA
收藏MedNurse-QA 数据集概述
数据集摘要
- 名称: MedNurse-QA
- 用途: 护理教育领域的问答数据集
- 数据量: 21,648个问答对
- 数据来源: Open RN教科书(《Fundamentals in Nursing》《Nursing Pharmacology》《Nursing Skills》)
- 创建方法: 使用GPT-4.0生成初始问答对,并由注册护士审核验证
- 质量保证: 移除错误或误导性内容(特别是药物计算部分)
- 核心主题: 患者护理、临床程序、药理学、专业护理实践
支持任务
- 封闭领域问答(回答护理相关问题)
- 教育AI(训练护理教育虚拟导师)
- 临床决策支持系统(增强AI学习平台)
语言
- 英语("en")
数据集结构
数据实例
json { "book": "Nursing Fundamentals", "chapter": "Communication", "subchapter": " Basic communication concepts ", "question": "How should nurses deal with differing perspectives? ", "answer": " Nurses should communicate in a nonjudgmental manner, respecting patients beliefs and perspectives." }
- 问题长度: 12.0至176.0字符
- 答案长度: 2.0至315字符
数据字段
- "book"(字符串): 来源教科书名称
- "chapter"(字符串): 主话题或章节标题
- "subchapter"(字符串): 章节内具体部分
- "question"(字符串): 护理相关问题
- "answer"(字符串): 正确答案
数据拆分
- 当前为单一问答对集合,用户需自行创建训练/验证/测试集
数据集创建
创建理由
- 解决护理教育领域缺乏特定问答数据集的问题
源数据
- 原始来源: CC-BY 4.0许可的Open RN教科书
- 处理: 使用GPT-4.0生成问答对,保持与原文一致
- 标注: 由注册护士手动检查验证
- 隐私: 不包含个人身份信息(PII)
使用注意事项
预期用途
- 护理教育AI模型的训练与评估
- 护理学生/医疗专业人员的虚拟导师开发
- 护理领域问答应用开发
- 护理教育培训的聊天机器人及智能辅导系统
限制
- 非临床使用:仅限教育用途
- 潜在偏见:基于美国护理教科书,可能未涵盖地区差异
- 时间敏感性:护理指南会更新,部分答案可能过时
许可信息
- 许可证: Creative Commons Attribution 4.0 International (CC-BY 4.0)
- 署名要求: 必须注明Open RN原始来源(https://www.cvtc.edu/grants/open-rn)
引用信息
APA格式
Dicheva, N. K., Rehman, I. U., Husamaldin, L., & Aleshaiker, S. (2025). MedNurse-QA (v1.0) [Data set]. Hugging Face. https://doi.org/10.57967/hf/6193
BibTeX格式
bibtex @misc{dicheva_mednurse_qa_2025, author = {Dicheva, N. K. and Rehman, I. U. and Husamaldin, L. and Aleshaiker, S.}, title = {MedNurse-QA (v1.0)}, year = {2025}, publisher = {Hugging Face}, doi = {10.57967/hf/6193}, url = {https://huggingface.co/datasets/NevenaD/MedNurse-QA} }