relaion2b-natural-embeddings
收藏Hugging Face2025-12-10 更新2025-12-11 收录
下载链接:
https://huggingface.co/datasets/andropar/relaion2b-natural-embeddings
下载链接
链接失效反馈官方服务:
资源简介:
ReLAION-2B自然嵌入数据集包含约5亿张自然照片的预计算CLIP ViT-H/14嵌入。这些嵌入适用于特征提取、图像分类、零样本分类和图像到图像等任务。数据集包含图像URL、自然分数(0.7-1.0)和768维CLIP嵌入等元数据,格式为Parquet(Snappy压缩),总大小约711 GB。数据集还提供了使用示例、相关数据集、许可信息和限制说明。
创建时间:
2025-12-09
原始信息汇总
ReLAION-2B Natural Embeddings 数据集概述
基本信息
- 数据集名称:ReLAION-2B Natural Embeddings
- 许可证:CC-BY 4.0
- 任务类别:特征提取、图像分类、零样本分类、图像到图像
- 语言:英语
- 标签:embeddings、clip、laion、image-embeddings、natural-images、image-retrieval
- 数据规模:1亿条 < n < 10亿条
核心内容
- 描述:该数据集包含从ReLAION-2B中筛选出的约5亿张自然照片的预计算CLIP ViT-H/14嵌入向量。
- 嵌入模型:CLIP ViT-H/14 (https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K)
- 嵌入维度:768
- 自然度分数范围:0.7 - 1.0(已过滤为自然照片)
- 格式:Parquet(Snappy压缩)
- 总大小:约711 GB
- 总嵌入向量数:约5.14亿条
- 文件数量:2,298个文件,命名格式为
relaion2b_features_*.parquet
数据集结构
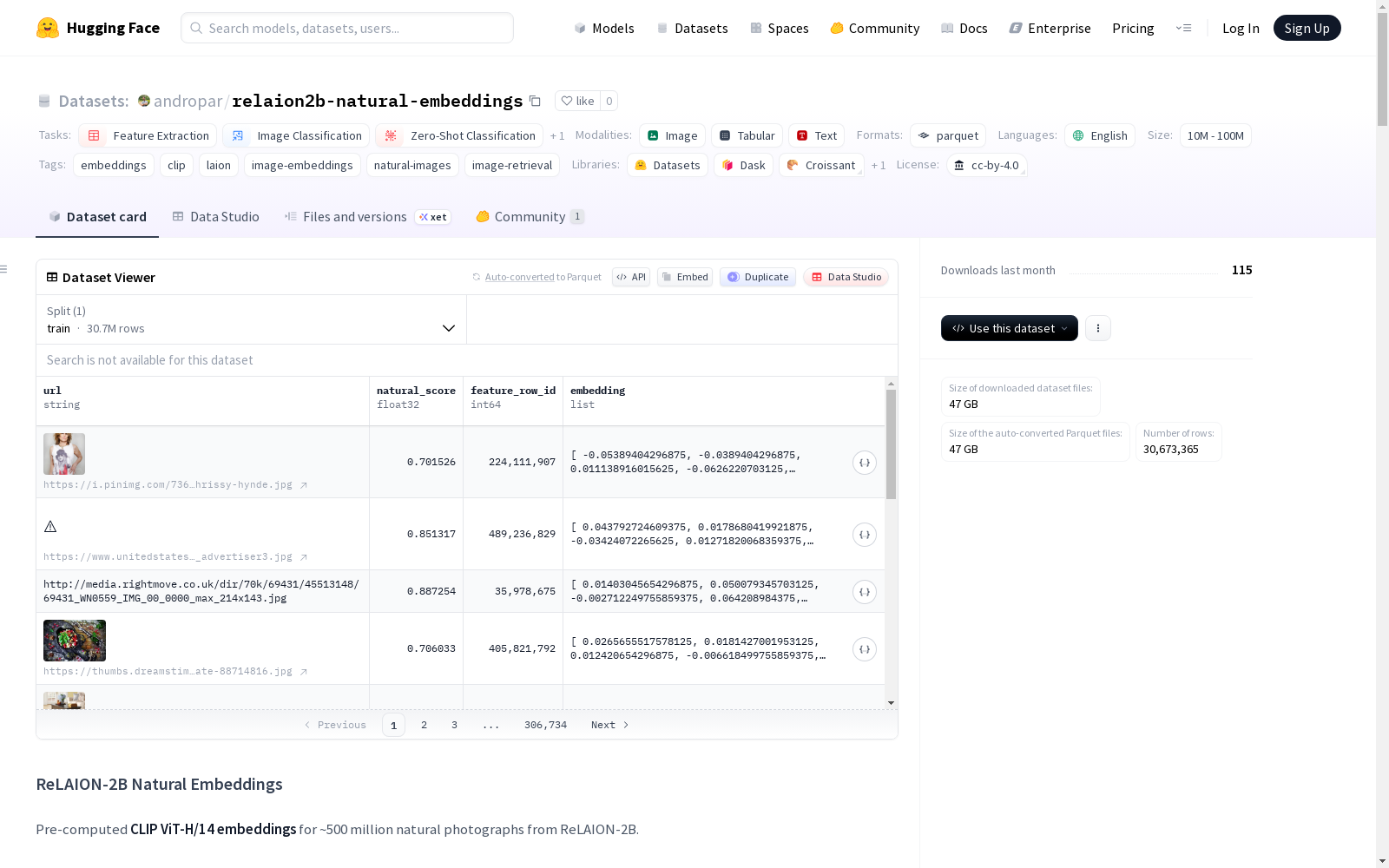
| 列名 | 类型 | 描述 |
|---|---|---|
url |
string | 来自ReLAION-2B的图像URL |
natural_score |
float32 | 自然度预测分数(0.7 - 1.0) |
feature_row_id |
int64 | 原始LAION-2B嵌入向量中的行索引 |
embedding |
float32[768] | CLIP ViT-H/14图像嵌入向量 |
使用示例
- 快速开始:可使用Hugging Face
datasets库以流式方式加载数据集。 - 加载嵌入向量:可使用PyArrow读取Parquet文件。
- 图像相似性搜索:可使用余弦相似度计算。
- 构建FAISS索引:用于快速搜索。
- 流式处理:支持使用Hugging Face datasets进行批处理。
应用场景
- 图像相似性搜索
- 零样本分类
- 聚类分析
- 下游模型训练数据
- 大规模视觉表示研究
相关数据集
- andropar/relaion2b-natural (https://huggingface.co/datasets/andropar/relaion2b-natural):包含所有21亿张ReLAION-2B图像的自然度分数。
来源与授权
- 源数据集:LAION的ReLAION-2B-en-research-safe (https://huggingface.co/datasets/laion/relaion2B-en-research-safe),采用Apache 2.0许可证。
- 内容说明:本仓库仅包含元数据和衍生特征(URL、自然度分数、嵌入向量),不包含图像。底层图像由第三方网站托管,受其原始版权和使用条款约束。本数据集的添加内容(嵌入向量、文档)采用CC-BY 4.0许可证发布。
引用
bibtex @inproceedings{ roth2025how, title={How to sample the world for understanding the visual system}, author={Johannes Roth and Martin N Hebart}, booktitle={8th Annual Conference on Cognitive Computational Neuroscience}, year={2025}, url={https://openreview.net/forum?id=T9k6KkZoca} }
局限性
- 嵌入向量来自CLIP ViT-H/14模型,该模型基于网络数据训练,可能反映其偏见。
- “自然度”基于学习的分类器,具体方法请参阅relaion2b-natural数据集。
- 部分URL可能已失效或指向已移除/更改的图像。
- 本数据集仅供研究使用。
搜集汇总
数据集介绍
构建方式
在计算机视觉与多模态学习领域,大规模图像嵌入数据集为模型训练与评估提供了关键资源。ReLAION-2B Natural Embeddings 的构建源于对海量自然图像进行高效表征的需求,其核心流程依托于 ReLAION-2B-en-research-safe 这一源数据集。通过应用 CLIP ViT-H/14 模型对其中约五亿张图像进行前向推理,生成了维度为768的标准化视觉嵌入向量。为确保数据质量,构建过程中引入了一个自然度评分过滤器,仅保留评分介于0.7至1.0之间的样本,从而聚焦于具有高度自然视觉特征的摄影图像。最终,所有元数据与嵌入向量以Parquet格式进行存储与压缩,形成了总计约711GB的结构化数据集合。
使用方法
该数据集为视觉表征学习与跨模态研究提供了直接可用的基础设施。用户可通过Hugging Face Datasets库以流式方式加载数据,有效管理内存使用,并逐批处理嵌入向量。对于本地化分析,可直接使用PyArrow读取Parquet文件,将嵌入转换为NumPy数组以进行后续计算。典型的应用场景包括构建基于余弦相似度的图像检索系统,或利用FAISS库建立高效的近似最近邻索引,以实现毫秒级的大规模相似性搜索。此外,这些预计算嵌入可直接作为特征输入,服务于零样本分类、图像聚类、下游模型训练等多种机器学习任务,显著降低了从原始图像进行特征提取的计算开销。
背景与挑战
背景概述
在计算机视觉与多模态学习领域,大规模图像嵌入数据集对于推动模型理解与检索能力具有关键作用。ReLAION-2B Natural Embeddings数据集由LAION等研究机构于2025年构建,旨在为约5.14亿张自然摄影图像提供预计算的CLIP ViT-H/14嵌入向量。该数据集的核心研究问题聚焦于如何高效表征海量自然图像的语义信息,以支持图像相似性搜索、零样本分类及聚类分析等任务。其基于ReLAION-2B-en-research-safe源数据,并利用先进的视觉-语言模型提取特征,显著提升了大规模视觉表示学习的效率,为多模态人工智能研究提供了重要的基础资源。
当前挑战
该数据集致力于解决大规模自然图像语义表征与检索的领域挑战,包括如何在亿级规模下实现高效的相似性匹配,以及如何利用CLIP等预训练模型克服零样本学习中的领域适应性问题。在构建过程中,研究者面临多重技术难题:首先,需从原始20亿图像中筛选出高质量自然图像,依赖自然性评分模型确保数据纯度,这一过程涉及复杂的质量评估与过滤流程;其次,处理与存储超过700GB的嵌入向量需要高效的数据压缩与分布式管理策略;此外,数据来源的版权合规性与URL链接的长期稳定性亦构成持续性的维护挑战。
常用场景
经典使用场景
在计算机视觉与多模态学习领域,大规模图像嵌入数据集为高效检索与相似性分析提供了基础。ReLAION-2B Natural Embeddings 以其约5.14亿自然图像的预计算CLIP嵌入,成为图像相似性搜索的经典工具。研究者通过余弦相似度或FAISS索引,能够快速在海量视觉数据中定位与查询图像语义相近的样本,这一过程不仅加速了视觉内容的组织与探索,也为跨模态对齐研究提供了丰富的特征表示。
解决学术问题
该数据集通过提供高质量的自然图像嵌入,有效缓解了视觉表示学习中大规模特征提取的计算负担。它使得学术界能够专注于下游任务的设计与验证,而非重复进行耗时的前处理。此外,其基于自然度分数的筛选机制,为研究视觉感知的自然性偏好、模型偏差分析以及无监督表征学习提供了标准化数据基础,推动了视觉认知与计算模型之间的交叉研究。
实际应用
在实际应用中,该数据集支撑了多种视觉系统的开发与优化。例如,在电子商务平台中,可用于构建以图搜图的推荐引擎;在数字资产管理中,能够实现海量图像库的智能分类与去重;在内容审核领域,则有助于识别违规或敏感视觉材料。这些应用均依赖于数据集提供的高维嵌入所捕获的深层语义信息,从而提升了系统的准确性与响应速度。
数据集最近研究
最新研究方向
在视觉表示学习领域,ReLAION-2B Natural Embeddings数据集凭借其约5.14亿张自然图像的预计算CLIP嵌入,正成为大规模多模态研究的关键资源。前沿探索聚焦于利用这些高质量嵌入进行零样本视觉推理与跨模态检索,尤其在开放词汇图像分类和语义驱动的图像生成任务中展现出潜力。随着生成式人工智能的兴起,该数据集被广泛用于训练视觉-语言模型的检索增强模块,以提升模型对真实世界视觉概念的理解与泛化能力。其自然性评分机制也为研究视觉感知的认知基础提供了数据支撑,推动了计算神经科学中对人类视觉系统建模的实证分析。
以上内容由遇见数据集搜集并总结生成


