ml-research-daily
收藏Hugging Face2026-04-26 更新2026-04-27 收录
下载链接:
https://huggingface.co/datasets/nellaivijay/ml-research-daily
下载链接
链接失效反馈官方服务:
资源简介:
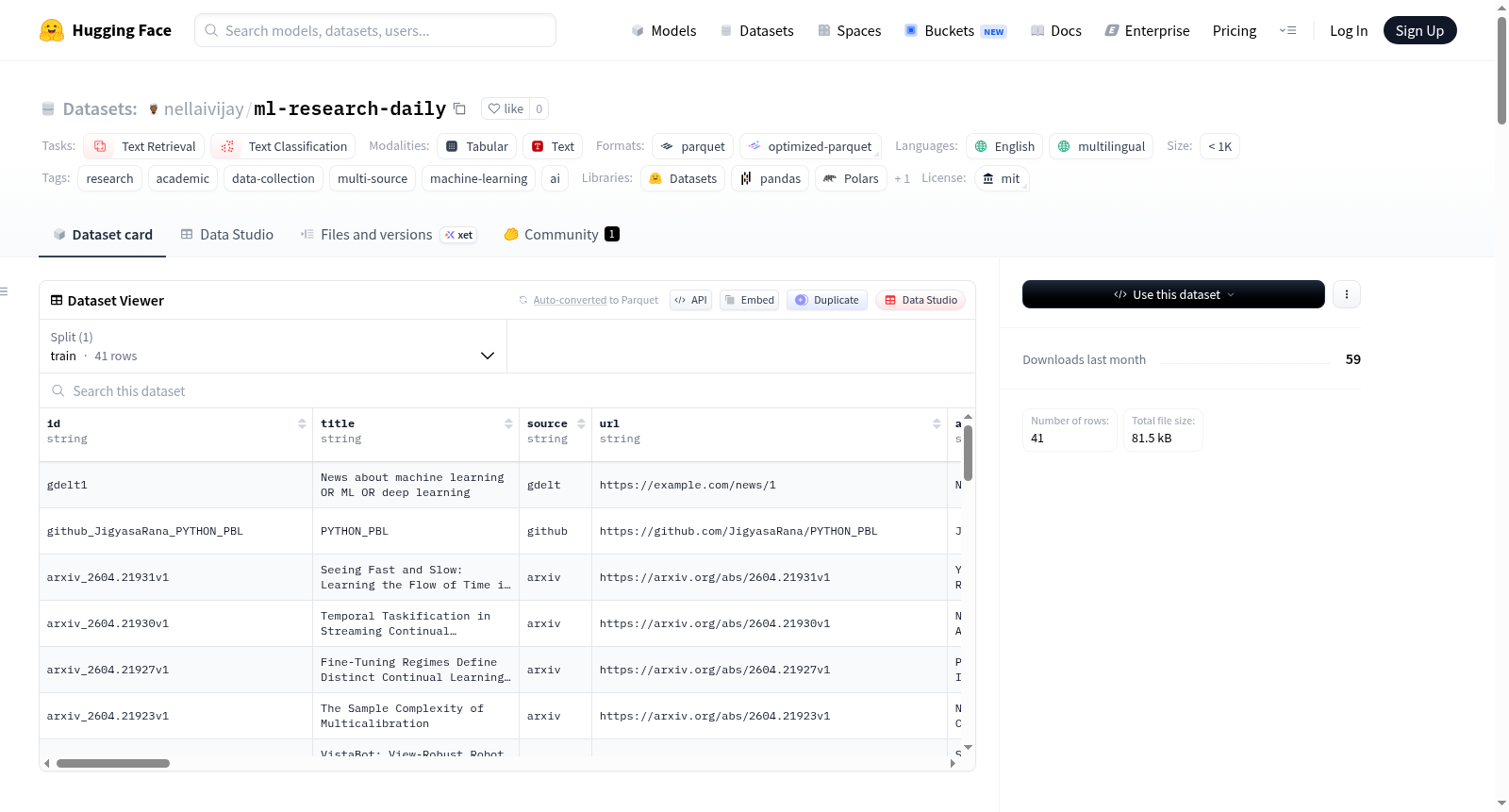
Research Collector数据集是一个通过Research-Collector工具从多个来源聚合的研究结果数据集。每个数据项包含丰富的元数据、ML子领域分类、质量评分和时间特征。数据集涵盖机器学习、深度学习及相关领域,时间范围为2026年4月19日至2026年4月26日,共包含41个数据项。数据来源包括学术平台(如PubMed、arXiv、Semantic Scholar)、专业平台(如GitHub、Stack Overflow、Kaggle)、社交平台(如Reddit、Hacker News)和新闻博客(如Medium、GDELT)。核心字段包括唯一标识符、标题、来源平台、URL、作者、发布日期、引用次数、点赞数、下载数、评论数、内容/摘要/描述和相关性评分。此外还包含丰富的元数据字段,如出版年份、月份、星期、季度、ML子领域分类、关键词提取、质量评分、情感分析、自动摘要、数据质量指标和趋势分析等。数据集适用于文本检索、文本分类等任务,并提供了多种使用示例。数据集的局限性包括时间范围限制、部分来源的API限制和ML子领域分类的不完美性。数据集采用MIT许可证发布。
The Research Collector Dataset is a collection of research results aggregated from multiple sources through the Research-Collector tool. Each data item contains rich metadata, ML subfield classifications, quality scores, and temporal features. The dataset covers topics including machine learning, deep learning, and related fields, spanning from April 19, 2026, to April 26, 2026, with a total of 41 data items. Data sources include academic platforms (e.g., PubMed, arXiv, Semantic Scholar), professional platforms (e.g., GitHub, Stack Overflow, Kaggle), social platforms (e.g., Reddit, Hacker News), and news blogs (e.g., Medium, GDELT). Core fields include unique identifiers, titles, source platforms, URLs, authors, publication dates, citation counts, like counts, download counts, comment counts, content/abstract/description, and relevance scores. Additionally, the dataset includes rich metadata fields such as publication year, month, week, quarter, ML subfield classifications, keyword extraction, quality scores, sentiment analysis, automatic summarization, data quality metrics, and trend analysis. The dataset is suitable for tasks like text retrieval and text classification and provides various usage examples. Limitations include the restricted time range, API limitations of some sources, and imperfect ML subfield classifications. The dataset is released under the MIT License.
创建时间:
2026-04-25
原始信息汇总
数据集概述:Research Collector Dataset
基本信息
- 数据集名称:Research Collector Dataset
- 许可证:MIT License
- 语言:英语(多语言)
- 任务类别:文本检索、文本分类
- 标签:研究、学术、数据收集、多源、机器学习、人工智能
- 数据集规模:少于1000条(n<1K)
数据内容与时间范围
- 主题:机器学习(machine learning / ML / deep learning)
- 时间范围:2026-04-19T15:40:59.228463 至 2026-04-26T15:40:59.228469
- 总条目数:41
- 导出时间:2026-04-26T15:41:25.549891
数据来源
该数据集从以下12个平台聚合研究结果:
| 类别 | 来源 |
|---|---|
| 学术 | PubMed、arXiv、Semantic Scholar、Crossref、Papers with Code |
| 专业 | GitHub、Stack Overflow、Kaggle |
| 社交 | Reddit、Hacker News |
| 新闻 | GDELT |
| 博客 | Medium |
数据集结构
核心字段
id:唯一标识符title:研究条目标题source:来源平台url:原始内容链接author:作者published_date:发布日期(ISO 8601格式)citations:引用数upvotes:点赞数downloads:下载数comments:评论数content:内容/摘要/描述score:相关性评分
丰富元数据字段
- 时间特征:出版年、月、日、周、季度、距今天数
- ML子领域分类:子领域列表(JSON数组)及数量
- 关键词:提取的关键词列表及数量
- 质量评分:质量得分指标(JSON字典)
- 内容类型:论文、预印本、仓库、讨论、问答、新闻
- 代码与DOI标识:是否包含代码、是否有DOI
- 情感分析:情感极性(-1到1)、主观性(0到1)、情感类别(正面/负面/中性)
- 自动摘要:抽取式摘要及摘要长度
- 数据质量指标:完整性、一致性、有效性及总体质量评分(JSON字典)
- 趋势指标:参与度速度评分、趋势类别(hot/warm/cool/cold)、原始参与度评分
- 关联条目:相似条目列表及数量(JSON数组)
来源特定元数据
- PubMed:期刊、DOI、MeSH术语、出版类型、摘要长度
- arXiv:arXiv ID、主分类、分类列表、期刊引用
- GitHub:星标数、分支数、编程语言、许可证、主题标签、是否有README
- Reddit:子版块、链接标签、点赞率、总奖励数、是否被镀金
- Stack Overflow:标签、回答数、是否有被采纳答案、查看数、提问者声誉
- Semantic Scholar:引用数、有影响力引用数、研究领域、是否开放获取
- Medium:作者、出版物、阅读时间、鼓掌数
- Kaggle:投票数、可用性评分、文件数量
数据质量特性
- 标准化日期:所有日期归一化为ISO 8601格式
- ML子领域分类:自动分类为15+个ML子领域
- 质量评分:多维度质量评估(摘要长度、代码可用性、DOI、参与度、时效性)
- 时间特征:年、月、周、季度、距今天数
- 关键词提取:自动提取技术关键词
- 内容类型检测:自动分类条目类型
- 情感分析:情感极性、主观性和类别分类
- 自动摘要:抽取式摘要用于快速内容概览
- 数据质量指标:每个条目的完整性、一致性和有效性评分
- 趋势指标:参与度速度分析及趋势类别
- 交叉引用:基于共享子领域、关键词和标签的关联条目检测
- 模糊去重:智能重复检测与元数据合并
- 元数据完整性:推断缺失元数据字段的备用逻辑
使用示例(Python)
python from datasets import load_dataset
dataset = load_dataset("nellaivijay/ml-research-daily") train_data = dataset["train"]
按来源筛选
pubmed_items = train_data.filter(lambda x: x["source"] == "pubmed")
按内容类型筛选
papers = train_data.filter(lambda x: x.get("metadata_content_type") == "paper")
按ML子领域筛选
cv_papers = train_data.filter(lambda x: "computer-vision" in x.get("metadata_ml_subfields", []))
按质量排序
high_quality = train_data.filter(lambda x: x.get("metadata_quality_scores", {}).get("overall_quality_score", 0) > 0.7)
按趋势类别筛选
trending_items = train_data.filter(lambda x: x.get("metadata_trending_category") == "hot")
按情感筛选
positive_items = train_data.filter(lambda x: x.get("metadata_sentiment_category") == "positive")
局限性
- 数据仅限于指定的时间范围
- 某些来源可能存在速率限制或API限制
- 不同来源的引用计数可能有所不同
- ML子领域分类基于关键词匹配,可能不完美
来源与引用
- 生成工具:Research-Collector
- 引用地址:https://huggingface.co/datasets/nellaivijay/ml-research-daily
搜集汇总
数据集介绍
构建方式
该数据集通过Research-Collector工具从12个多元化信源(涵盖PubMed、arXiv、Semantic Scholar等学术平台,GitHub、Kaggle等专业社区,Reddit、Hacker News等社交媒介,以及GDELT全球新闻数据库)聚合机器学习领域研究动态。系统以'machine learning OR ML OR deep learning'为检索主题,捕获2026年4月19日至26日期间发布的41条记录,并对每项内容执行标准化清洗、模糊去重与元数据补全,最终生成包含核心字段、丰富元数据及信源特有属性的结构化数据集。
使用方法
用户可通过HuggingFace Datasets库便捷加载数据,支持多种功能性筛选与排序操作。例如,按source字段过滤特定平台(如pubmed或github)的条目,依据metadata_content_type区分论文与代码仓库,利用metadata_ml_subfields检索计算机视觉等子领域内容。亦可基于metadata_data_quality中的overall_quality_score筛选高质量记录,按score字段降序排序,或通过metadata_days_since定位近30日最新成果。情感分类与趋势标签同样可作为过滤条件,并能直接调用metadata_related_items获取相似研究推荐。
背景与挑战
背景概述
在人工智能与机器学习领域,学术研究产出呈现爆炸式增长,如何高效聚合多源异构的科研信息成为亟待解决的关键问题。由研究者Vijay Nellai及其团队开发的ml-research-daily数据集应运而生,该数据集于2026年4月发布,依托Research-Collector工具,从PubMed、arXiv、GitHub等13个学术、专业及社交平台协同采集机器学习与深度学习相关的研究成果。其核心研究问题聚焦于构建一个结构化、高质量的多源科研数据聚合体,通过自动分类、质量评分、情感分析与趋势检测等丰富元数据,为文本检索与分类任务提供基准。该数据集虽样本量较小(41条),但其创新的跨平台融合与元数据增强策略,为后续大规模科研数据集成与智能分析开辟了新的路径。
当前挑战
该数据集所解决的领域挑战在于,现有科研数据分散于各独立平台,缺乏统一标准与质量评估,研究者难以快速捕捉跨领域进展。ml-research-daily通过构建标准化的元数据体系与多维质量评分模型,有效应对了多源数据融合时的字段缺失与格式异构问题。在构建过程中,团队面临多重技术挑战:首先,不同API存在速率限制与数据返回差异,需设计弹性采集与重试机制;其次,针对机器学习子领域的自动分类依赖关键词匹配,在术语歧义与领域交叉时易产生偏差;此外,跨平台去重需融合模糊匹配与元数据合并算法,以避免科研信息冗余。数据的时间范围限制与部分源引用计数不统一,也增加了趋势分析与质量评估的复杂度。
常用场景
经典使用场景
在机器学习与人工智能研究领域,追踪前沿动态与挖掘跨源信息是学术探索的关键环节。ml-research-daily 数据集作为一项多源聚合的研究成果集合,其经典使用场景在于支撑学术研究中的多模态信息检索与文本分类任务。研究者可借助该数据集,通过丰富的元数据字段(如来源标签、内容类型、ML子领域分类)进行精准过滤和排序,进而快速定位特定主题下的高质量论文、代码仓库或技术讨论。以时间特征与质量评分作为双轮驱动,该数据集为自动化构建研究综述、热点趋势分析以及多源文献的整合提供了结构化的试验场,成为连接零散学术信息与系统化知识发现的桥梁。
解决学术问题
学术研究中长期存在信息碎片化与知识冗余并存的困境,尤其是跨平台的数据异构性与时间敏感性严重阻碍了高效的知识萃取。ml-research-daily 数据集通过构建标准化的时间特征、质量评分与情感极性字段,系统性地解决了研究热点追踪中的时效性偏差与质量评估主观性问题。其内置的元数据完整性校验、模糊去重与内容类型检测机制,弥补了跨源数据对齐与重复识别领域的空白,为研究者提供了一套可复现的数据清洗与聚合方法。此外,该数据集通过跨源关联与趋势性指标的设计,有力地推动了学术社区对科研动态演化规律这一基础问题的实证探索,显著提升了多源信息融合分析的科学性与可解释性。
实际应用
在实际产业与教育场景中,ml-research-daily 数据集为构建个性化的科研情报系统与智能内容推荐引擎注入了鲜活的数据血液。技术企业可利用其来源特异性元数据(如GitHub的星标数与Stack Overflow的问答统计),开发面向工程师的代码质量评估与学术转化工具。学术服务机构则可借助其内容类型分类与情感分析结果,设计自动化的论文影响力预测模型或跨语种技术新闻简报生成应用。此外,该数据集在科技自媒体与在线教育领域同样展现了广阔前景,通过趋势分类与相关项检测,赋能研究平台向用户动态推送关联度最高的前沿成果,实现从被动检索到主动认知的知识服务升级。
数据集最近研究
最新研究方向
在机器学习的浩瀚前沿,多源异构数据的聚合与智能标注正成为驱动学术洞察与工程实践的关键引擎。ml-research-daily数据集应运而生,它通过跨平台采集PubMed、arXiv、GitHub及Reddit等十余个来源的学术动态,融合了论文、代码库、讨论帖与新闻等多元内容类型,并借助ML子领域分类、情感极性分析、趋势速度评估及数据质量评分等丰富的元数据谱系,构建起一幅时序性极强的研究全景图。该数据集不仅支持细粒度过滤与相关性检索,更以其内置的交叉引用与去重机制,为追踪热点演进、解析跨模态关联、以及构建个性化科研信息流提供了坚实的数据底座,标志着机器学习领域自动化文献分析向深度认知与实时洞察的跨越。
以上内容由遇见数据集搜集并总结生成


