blip3-grounding-50m
收藏魔搭社区2025-12-05 更新2025-09-13 收录
下载链接:
https://modelscope.cn/datasets/Salesforce/blip3-grounding-50m
下载链接
链接失效反馈官方服务:
资源简介:
# BLIP3-GROUNDING-50M Dataset
## Overview
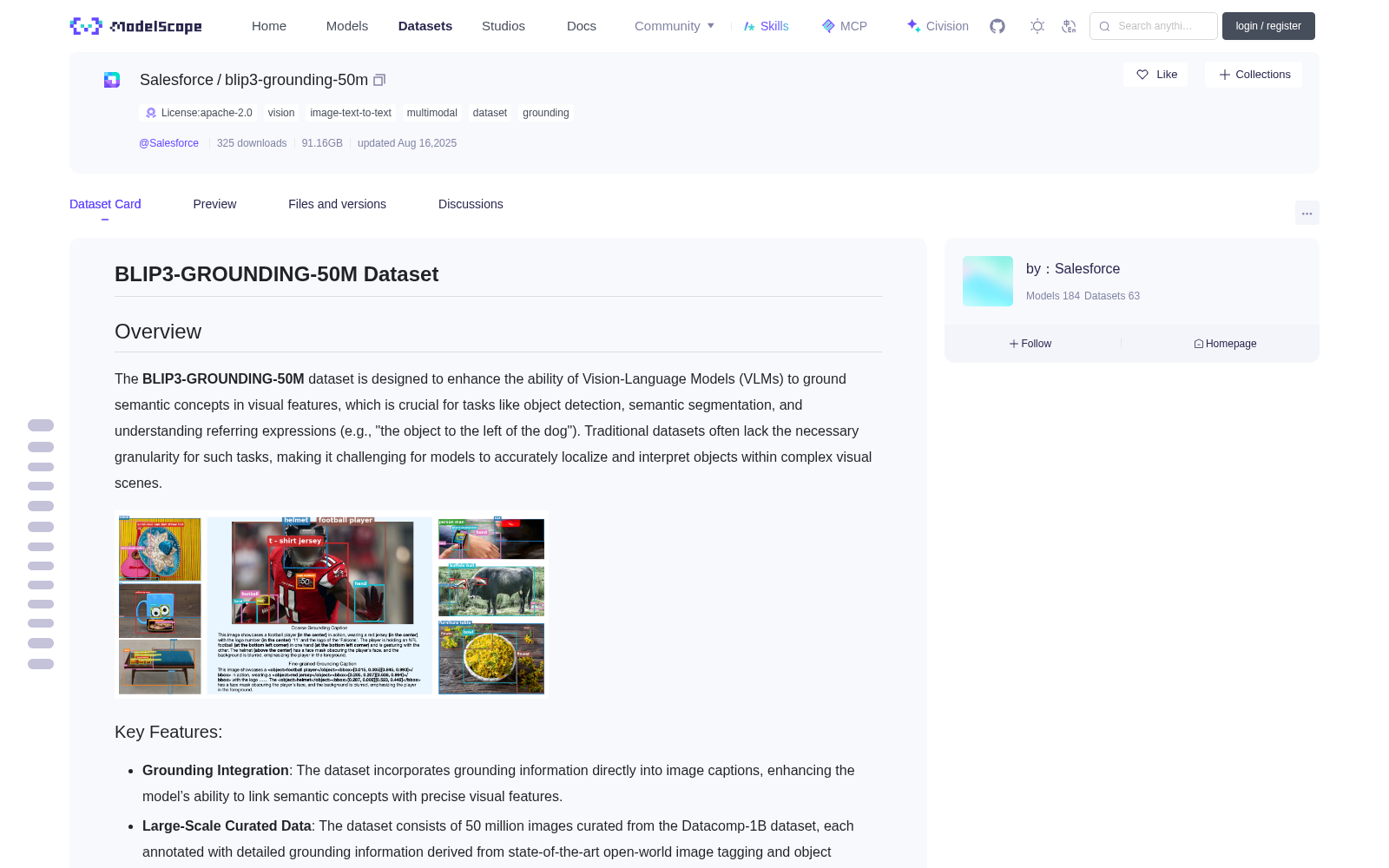
The **BLIP3-GROUNDING-50M** dataset is designed to enhance the ability of Vision-Language Models (VLMs) to ground semantic concepts in visual features, which is crucial for tasks like object detection, semantic segmentation, and understanding referring expressions (e.g., "the object to the left of the dog"). Traditional datasets often lack the necessary granularity for such tasks, making it challenging for models to accurately localize and interpret objects within complex visual scenes.
<img src="blip3_grounding_50m.png" alt="Art" width=500>
### Key Features:
- **Grounding Integration**: The dataset incorporates grounding information directly into image captions, enhancing the model’s ability to link semantic concepts with precise visual features.
- **Large-Scale Curated Data**: The dataset consists of 50 million images curated from the Datacomp-1B dataset, each annotated with detailed grounding information derived from state-of-the-art open-world image tagging and object detection models.
- **Multi-Granularity Bounding Boxes**: Grounding information is provided in three different formats, each capturing varying levels of localization detail:
1. **Bounding Box Coordinates**: `<bbox>x1, y1, x2, y2</bbox>`.
2. **Textual Description**: "Starts at (x1, y1) and extends up to (x2, y2)".
3. **Positional Context**: "Top-left corner of the image".
### Purpose:
The primary goal of the BLIP3-GROUNDING-50M dataset is to improve the cross-modality reasoning capabilities of VLMs by providing them with enriched visual and grounding data. This dataset is aimed at advancing the performance of VLMs on tasks that require precise object localization and semantic understanding within complex images.
## Key Statistics:
- **Total Shards**: 50 parquet files (each approximately 1.5GB).
- **Data Format**: Parquet files containing URLs of images and metadata.
- **Sample Count**: Approximately 50M images.
- **Purpose**: This dataset is intended for training and evaluating VLMs on grounding tasks and enhancing object detection and semantic segmentation performance.
## Download and Usage
You can load and use this dataset in your projects by following the example below:
### Loading the Dataset
```python
from datasets import load_dataset
# Load the dataset from Hugging Face
dataset = load_dataset("Salesforce/blip3-grounding-50m")
# Print a specific sample
print(yaml.dump(dataset['train'][0]))
```
### Accessing Specific Shards
If you want to work with specific shards, you can download them separately and process them manually. You can also clone this dataset by following instructions detailed [here](https://huggingface.co/docs/hub/en/repositories-getting-started).
```python
import pandas as pd
# Path to the Parquet file you want to read
file_path = 'data/combined_part_01.parquet'
# Read the Parquet file into a DataFrame
df = pd.read_parquet(file_path)
# Display the first few rows of the DataFrame
print(df.head())
```
### File Structure
The dataset is split into several parquet files:
```
data
├── combined_part_01.parquet
├── combined_part_02.parquet
├── combined_part_03.parquet
├── combined_part_04.parquet
├── combined_part_05.parquet
├── combined_part_06.parquet
├── combined_part_07.parquet
├── combined_part_08.parquet
├── combined_part_09.parquet
├── combined_part_10.parquet
├── combined_part_11.parquet
├── combined_part_12.parquet
├── combined_part_13.parquet
├── combined_part_14.parquet
├── combined_part_15.parquet
├── combined_part_16.parquet
├── combined_part_17.parquet
├── combined_part_18.parquet
├── combined_part_19.parquet
├── combined_part_20.parquet
├── combined_part_21.parquet
├── combined_part_22.parquet
├── combined_part_23.parquet
├── combined_part_24.parquet
├── combined_part_25.parquet
├── combined_part_26.parquet
├── combined_part_27.parquet
├── combined_part_28.parquet
├── combined_part_29.parquet
├── combined_part_30.parquet
├── combined_part_31.parquet
├── combined_part_32.parquet
├── combined_part_33.parquet
├── combined_part_34.parquet
├── combined_part_35.parquet
├── combined_part_36.parquet
├── combined_part_37.parquet
├── combined_part_38.parquet
├── combined_part_39.parquet
├── combined_part_40.parquet
├── combined_part_41.parquet
├── combined_part_42.parquet
├── combined_part_43.parquet
├── combined_part_44.parquet
├── combined_part_45.parquet
├── combined_part_46.parquet
├── combined_part_47.parquet
├── combined_part_48.parquet
├── combined_part_49.parquet
└── combined_part_50.parquet
```
### Metadata Fields
Each sample in the dataset has the following fields:
- **uid**: A unique identifier for the sample.
- **url**: URL for downloading the image
- **captions**: A list of caption entries with varying levels of detail, including:
- **text**: Descriptions of the objects and their locations within the image.
- **granularity**: The level of detail in the caption, ranging from general descriptions to precise bounding box details.
- **cogvlm_caption**: The caption of the image (without any bounding box information).
- **metadata**:
- **entries**: A list of detected objects within the image, with each entry containing:
- **category**: The label or type of the detected object (e.g., "flower", "star").
- **bbox**: Normalized Bounding box coordinates `[x1, y1, x2, y2]` representing the object's location in the image.
- **confidence**: The confidence score of the detection, indicating the likelihood that the object belongs to the specified category.
- **format**: The format of the bounding box coordinates, typically `x1y1x2y2`.
- **length**: The number of detected objects or entries in the metadata.
### Sample Metadata:
Here is a YAML dump of one of the samples
```yaml
captions: '[["This image is a chalk drawing on a blackboard. The word ''ALOHA'' is
written in white chalk in the center, with a blue underline beneath it. Surrounding
the word ''ALOHA'' are various colorful drawings of flowers and stars. The flowers
are in different colors such as purple, yellow, and blue, and the stars are in colors
like red, yellow, and green. The image contains chalk blackboard (in the center),
writing (in the center)", 0, True], ["This image is a chalk drawing on a blackboard.
The word ''ALOHA'' is written in white chalk in the center, with a blue underline
beneath it. Surrounding the word ''ALOHA'' are various colorful drawings of flowers
and stars. The flowers are in different colors such as purple, yellow, and blue,
and the stars are in colors like red, yellow, and green. The image contains chalk
blackboard (starts at [-0.0, 0.0] and extends upto [1.0, 1.0]), writing (starts
at [-0.0, 0.279] and extends upto [0.941, 0.582])", 1, True], ["This image is a
chalk drawing on a blackboard. The word ''ALOHA'' is written in white chalk in the
center, with a blue underline beneath it. Surrounding the word ''ALOHA'' are various
colorful drawings of flowers and stars. The flowers are in different colors such
as purple, yellow, and blue, and the stars are in colors like red, yellow, and green.
The image contains <object>chalk blackboard</object><bbox>[-0.0, 0.0][1.0, 1.0]</bbox>,
<object>writing</object><bbox>[-0.0, 0.279][0.941, 0.582]</bbox>", 2, True]]'
cogvlm_caption: This image is a chalk drawing on a blackboard. The word 'ALOHA' is
written in white chalk in the center, with a blue underline beneath it. Surrounding
the word 'ALOHA' are various colorful drawings of flowers and stars. The flowers
are in different colors such as purple, yellow, and blue, and the stars are in colors
like red, yellow, and green.
data_type: detection_datacomp
metadata:
entries:
- bbox:
- -5.147297997609712e-05
- 9.50622561504133e-05
- 0.9999485015869141
- 1.0000863075256348
category: chalk blackboard
confidence: 0.3905350863933563
- bbox:
- 0.06830675899982452
- 0.18154683709144592
- 0.1917947381734848
- 0.30393147468566895
category: star
confidence: 0.3830861747264862
- bbox:
- 0.2539200186729431
- 0.15452484786510468
- 0.4078095853328705
- 0.3057566285133362
category: purple
confidence: 0.3823974132537842
- bbox:
- -0.0001940409274538979
- 0.2789899706840515
- 0.9411562085151672
- 0.5815576910972595
category: writing
confidence: 0.3642055094242096
- bbox:
- 0.5318483114242554
- 0.17996633052825928
- 0.6387724876403809
- 0.2852957248687744
category: star
confidence: 0.34707701206207275
- bbox:
- 0.8897764086723328
- 0.1982300877571106
- 0.9999181032180786
- 0.31441783905029297
category: flower
confidence: 0.2976141571998596
- bbox:
- 0.7027402520179749
- 0.16081181168556213
- 0.8440917730331421
- 0.28861796855926514
category: flower
confidence: 0.28454938530921936
- bbox:
- 0.19280104339122772
- 0.6314448118209839
- 0.3406122922897339
- 0.7835787534713745
category: star
confidence: 0.2739691734313965
- bbox:
- 0.6864601373672485
- 0.6489977240562439
- 0.8106556534767151
- 0.7741038203239441
category: star
confidence: 0.2596995532512665
- bbox:
- 0.8889400959014893
- 0.6385979652404785
- 0.9999745488166809
- 0.7874608039855957
category: flower
confidence: 0.2528996169567108
format: x1y1x2y2
length: 10
uid: 000000010038
url: http://st.depositphotos.com/1034557/2143/i/110/depositphotos_21434659-Aloha-Hawaii-Chalk-Drawing.jpg
```
## Ethical Considerations
This release is for research purposes only in support of an academic paper. Our models, datasets, and code are not specifically designed or evaluated for all downstream purposes. We strongly recommend users evaluate and address potential concerns related to accuracy, safety, and fairness before deploying this model. We encourage users to consider the common limitations of AI, comply with applicable laws, and leverage best practices when selecting use cases, particularly for high-risk scenarios where errors or misuse could significantly impact people’s lives, rights, or safety. For further guidance on use cases, refer to our AUP and AI AUP.
## Licensing and Acknowledgements
- **License**: Apache2.0. This is being released for research purposes only. This repo includes the extracted original text in the underlying images. It is the responsibility of the user to check and/or obtain the proper copyrights to use any of the images of the original dataset.
- **Citation**: If you use this dataset, please cite xGen-MM(BLIP-3).
```
@article{blip3-xgenmm,
author = {Le Xue, Manli Shu, Anas Awadalla, Jun Wang, An Yan, Senthil Purushwalkam, Honglu Zhou, Viraj Prabhu, Yutong Dai, Michael S Ryoo, Shrikant Kendre, Jieyu Zhang, Can Qin, Shu Zhang, Chia-Chih Chen, Ning Yu, Juntao Tan, Tulika Manoj Awalgaonkar, Shelby Heinecke, Huan Wang, Yejin Choi, Ludwig Schmidt, Zeyuan Chen, Silvio Savarese, Juan Carlos Niebles, Caiming Xiong, Ran Xu},
title = {xGen-MM(BLIP-3): A Family of Open Large Multimodal Models},
journal = {arXiv preprint},
month = {August},
year = {2024},
}
```
# BLIP3-GROUNDING-50M 数据集
## 概述
**BLIP3-GROUNDING-50M** 数据集旨在提升视觉语言模型(Vision-Language Models, VLMs)将语义概念锚定至视觉特征的能力,这对于目标检测、语义分割以及指代表达式理解(例如"狗左侧的物体")等任务至关重要。传统数据集往往缺乏此类任务所需的细粒度标注,导致模型难以在复杂视觉场景中精准定位并解读物体。
<img src="blip3_grounding_50m.png" alt="Art" width=500>
### 核心特性:
- **锚定信息集成**:数据集将锚定信息直接整合至图像标题中,增强模型关联语义概念与精准视觉特征的能力。
- **大规模精选数据**:数据集包含从Datacomp-1B数据集中精选的5000万张图像,每张图像均配有由当前最先进的开放世界图像标注与目标检测模型生成的详细锚定信息。
- **多粒度边界框(bounding box)**:锚定信息以三种不同格式提供,分别覆盖不同层级的定位细节:
1. **边界框坐标**:`<bbox>x1, y1, x2, y2</bbox>`。
2. **文本描述**:"以(x1, y1)为起点,延伸至(x2, y2)"。
3. **位置上下文**:"图像左上角区域"。
### 设计目标:
BLIP3-GROUNDING-50M数据集的核心目标是通过提供丰富的视觉与锚定数据,提升视觉语言模型的跨模态推理能力,旨在推动视觉语言模型在需精准目标定位与语义理解的复杂图像任务上的性能表现。
## 核心统计数据:
- **总分片数**:50个Parquet文件(单个文件大小约1.5GB)。
- **数据格式**:包含图像URL与元数据的Parquet文件。
- **样本总量**:约5000万张图像。
- **用途**:本数据集旨在用于训练与评估视觉语言模型的锚定任务,同时提升目标检测与语义分割的性能。
## 下载与使用
你可以通过以下示例在项目中加载并使用本数据集:
### 加载数据集
python
from datasets import load_dataset
# 从Hugging Face加载数据集
dataset = load_dataset("Salesforce/blip3-grounding-50m")
# 打印特定样本
print(yaml.dump(dataset['train'][0]))
### 访问指定分片
若需处理特定分片,你可以单独下载并手动处理。你也可以按照[此处](https://huggingface.co/docs/hub/en/repositories-getting-started)的详细说明克隆本数据集。
python
import pandas as pd
# 目标Parquet文件路径
file_path = 'data/combined_part_01.parquet'
# 读取Parquet文件至DataFrame
df = pd.read_parquet(file_path)
# 展示DataFrame的前几行
print(df.head())
### 文件结构
数据集被拆分为多个Parquet文件:
data
├── combined_part_01.parquet
├── combined_part_02.parquet
├── combined_part_03.parquet
├── combined_part_04.parquet
├── combined_part_05.parquet
├── combined_part_06.parquet
├── combined_part_07.parquet
├── combined_part_08.parquet
├── combined_part_09.parquet
├── combined_part_10.parquet
├── combined_part_11.parquet
├── combined_part_12.parquet
├── combined_part_13.parquet
├── combined_part_14.parquet
├── combined_part_15.parquet
├── combined_part_16.parquet
├── combined_part_17.parquet
├── combined_part_18.parquet
├── combined_part_19.parquet
├── combined_part_20.parquet
├── combined_part_21.parquet
├── combined_part_22.parquet
├── combined_part_23.parquet
├── combined_part_24.parquet
├── combined_part_25.parquet
├── combined_part_26.parquet
├── combined_part_27.parquet
├── combined_part_28.parquet
├── combined_part_29.parquet
├── combined_part_30.parquet
├── combined_part_31.parquet
├── combined_part_32.parquet
├── combined_part_33.parquet
├── combined_part_34.parquet
├── combined_part_35.parquet
├── combined_part_36.parquet
├── combined_part_37.parquet
├── combined_part_38.parquet
├── combined_part_39.parquet
├── combined_part_40.parquet
├── combined_part_41.parquet
├── combined_part_42.parquet
├── combined_part_43.parquet
├── combined_part_44.parquet
├── combined_part_45.parquet
├── combined_part_46.parquet
├── combined_part_47.parquet
├── combined_part_48.parquet
├── combined_part_49.parquet
└── combined_part_50.parquet
### 元数据字段
数据集中的每个样本包含以下字段:
- **uid**:样本的唯一标识符。
- **url**:图像下载链接
- **captions**:包含不同细节层级的标题条目列表,其中包含:
- **text**:对图像中物体及其位置的描述。
- **granularity**:标题的细节等级,范围从通用描述到精准边界框信息。
- **cogvlm_caption**:图像标题(不含任何边界框信息)。
- **metadata**:
- **entries**:图像中检测到的物体列表,每个条目包含:
- **category**:检测到的物体的类别标签(例如"花朵""星星")。
- **bbox**:归一化的边界框坐标 `[x1, y1, x2, y2]`,表示物体在图像中的位置。
- **confidence**:检测置信度分数,表示该物体属于指定类别的可能性。
- **format**:边界框坐标的格式,通常为 `x1y1x2y2`。
- **length**:元数据中检测到的物体或条目的数量。
### 样本元数据示例
以下为单个样本的YAML导出内容
yaml
captions: '[["This image is a chalk drawing on a blackboard. The word ''ALOHA'' is
written in white chalk in the center, with a blue underline beneath it. Surrounding
the word ''ALOHA'' are various colorful drawings of flowers and stars. The flowers
are in different colors such as purple, yellow, and blue, and the stars are in colors
like red, yellow, and green. The image contains chalk blackboard (in the center),
writing (in the center)", 0, True], ["This image is a chalk drawing on a blackboard.
The word ''ALOHA'' is written in white chalk in the center, with a blue underline
beneath it. Surrounding the word ''ALOHA'' are various colorful drawings of flowers
and stars. The flowers are in different colors such as purple, yellow, and blue,
and the stars are in colors like red, yellow, and green. The image contains chalk
blackboard (starts at [-0.0, 0.0] and extends upto [1.0, 1.0]), writing (starts
at [-0.0, 0.279] and extends upto [0.941, 0.582])", 1, True], ["This image is a
chalk drawing on a blackboard. The word ''ALOHA'' is written in white chalk in the
center, with a blue underline beneath it. Surrounding the word ''ALOHA'' are various
colorful drawings of flowers and stars. The flowers are in different colors such
as purple, yellow, and blue, and the stars are in colors like red, yellow, and green.
The image contains <object>chalk blackboard</object><bbox>[-0.0, 0.0][1.0, 1.0]</bbox>,
<object>writing</object><bbox>[-0.0, 0.279][0.941, 0.582]</bbox>", 2, True]]'
cogvlm_caption: This image is a chalk drawing on a blackboard. The word 'ALOHA' is
written in white chalk in the center, with a blue underline beneath it. Surrounding
the word 'ALOHA' are various colorful drawings of flowers and stars. The flowers
are in different colors such as purple, yellow, and blue, and the stars are in colors
like red, yellow, and green.
data_type: detection_datacomp
metadata:
entries:
- bbox:
- -5.147297997609712e-05
- 9.50622561504133e-05
- 0.9999485015869141
- 1.0000863075256348
category: chalk blackboard
confidence: 0.3905350863933563
- bbox:
- 0.06830675899982452
- 0.18154683709144592
- 0.1917947381734848
- 0.30393147468566895
category: star
confidence: 0.3830861747264862
- bbox:
- 0.2539200186729431
- 0.15452484786510468
- 0.4078095853328705
- 0.3057566285133362
category: purple
confidence: 0.3823974132537842
- bbox:
- -0.0001940409274538979
- 0.2789899706840515
- 0.9411562085151672
- 0.5815576910972595
category: writing
confidence: 0.3642055094242096
- bbox:
- 0.5318483114242554
- 0.17996633052825928
- 0.6387724876403809
- 0.2852957248687744
category: star
confidence: 0.34707701206207275
- bbox:
- 0.8897764086723328
- 0.1982300877571106
- 0.9999181032180786
- 0.31441783905029297
category: flower
confidence: 0.2976141571998596
- bbox:
- 0.7027402520179749
- 0.16081181168556213
- 0.8440917730331421
- 0.28861796855926514
category: flower
confidence: 0.28454938530921936
- bbox:
- 0.19280104339122772
- 0.6314448118209839
- 0.3406122922897339
- 0.7835787534713745
category: star
confidence: 0.2739691734313965
- bbox:
- 0.6864601373672485
- 0.6489977240562439
- 0.8106556534767151
- 0.7741038203239441
category: star
confidence: 0.2596995532512665
- bbox:
- 0.8889400959014893
- 0.6385979652404785
- 0.9999745488166809
- 0.7874608039855957
category: flower
confidence: 0.2528996169567108
format: x1y1x2y2
length: 10
uid: 000000010038
url: http://st.depositphotos.com/1034557/2143/i/110/depositphotos_21434659-Aloha-Hawaii-Chalk-Drawing.jpg
## 伦理考量
本发布仅用于支持学术论文的研究用途。我们的模型、数据集与代码并未针对所有下游场景进行专门设计与评估。强烈建议用户在部署本模型前,针对准确性、安全性与公平性等潜在问题开展评估与优化。我们鼓励用户考虑人工智能的通用局限性,遵守适用法律法规,并在选择应用场景时采用最佳实践,尤其在错误或不当使用可能显著影响人类生活、权利或安全的高风险场景中。如需了解更多应用场景指导,请参阅我们的AUP与AI AUP。
## 许可与致谢
- **许可证**:Apache2.0。本资源仅用于研究目的。本仓库包含从原始图像中提取的文本内容。用户需自行检查并/或获取使用原始数据集中所有图像的合法版权。
- **引用要求**:若使用本数据集,请引用xGen-MM(BLIP-3)。
@article{blip3-xgenmm,
author = {Le Xue, Manli Shu, Anas Awadalla, Jun Wang, An Yan, Senthil Purushwalkam, Honglu Zhou, Viraj Prabhu, Yutong Dai, Michael S Ryoo, Shrikant Kendre, Jieyu Zhang, Can Qin, Shu Zhang, Chia-Chih Chen, Ning Yu, Juntao Tan, Tulika Manoj Awalgaonkar, Shelby Heinecke, Huan Wang, Yejin Choi, Ludwig Schmidt, Zeyuan Chen, Silvio Savarese, Juan Carlos Niebles, Caiming Xiong, Ran Xu},
title = {xGen-MM(BLIP-3): A Family of Open Large Multimodal Models},
journal = {arXiv preprint},
month = {August},
year = {2024},
}
提供机构:
maas创建时间:
2025-08-16
搜集汇总
数据集介绍
背景与挑战
背景概述
BLIP3-GROUNDING-50M数据集是一个包含5000万张图像的大规模多模态数据集,旨在增强视觉语言模型在复杂场景中定位和解释语义概念的能力。它提供三种不同粒度的边界框标注信息,用于提升对象检测、语义分割等任务的性能,以促进跨模态推理能力的发展。
以上内容由遇见数据集搜集并总结生成


