wmt/wmt20_mlqe_task1
收藏Hugging Face2024-04-04 更新2024-04-20 收录
下载链接:
https://hf-mirror.com/datasets/wmt/wmt20_mlqe_task1
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是WMT20多语言质量估计任务(MLQE)的一部分,主要用于评估神经机器翻译输出的质量。数据集包含多种语言对的翻译数据,包括英语-德语、英语-中文等,数据来源于维基百科和Reddit。每个句子由专业翻译人员使用直接评估(DA)评分进行标注,评分范围为0-100。数据集的结构包括训练集、验证集和测试集,每个配置包含7000个训练样本、1000个验证样本和1000个测试样本。数据集的创建目的是为了进一步研究自动评估神经机器翻译质量的方法,特别是在没有参考翻译的情况下。
This dataset is part of the WMT20 Multilingual Quality Estimation (MLQE) task, and is primarily designed to evaluate the quality of neural machine translation outputs. It includes translation data across multiple language pairs such as English-German, English-Chinese and others, with data sourced from Wikipedia and Reddit. Each sentence is annotated with a Direct Assessment (DA) score by professional translators, with the score ranging from 0 to 100. The dataset is structured into training, validation and test sets, with each configuration containing 7000 training samples, 1000 validation samples and 1000 test samples. The dataset was created to advance research on automatic quality assessment methods for neural machine translation, particularly in scenarios where no reference translations are available.
提供机构:
wmt
原始信息汇总
数据集概述
数据集名称
- 名称: WMT20 - MultiLingual Quality Estimation (MLQE) Task1
- 别名: MLQE-Task1
数据集概要
- 目的: 评估神经机器翻译输出的质量,无需依赖参考翻译。
- 内容: 包含多种语言对的翻译数据,主要来自Wikipedia文章,部分来自Reddit。
- 语言: 包含德语、英语、爱沙尼亚语、尼泊尔语、罗马尼亚语、俄语、僧伽罗语、中文。
数据集结构
- 配置: 支持多种语言对,如en-de, en-zh等。
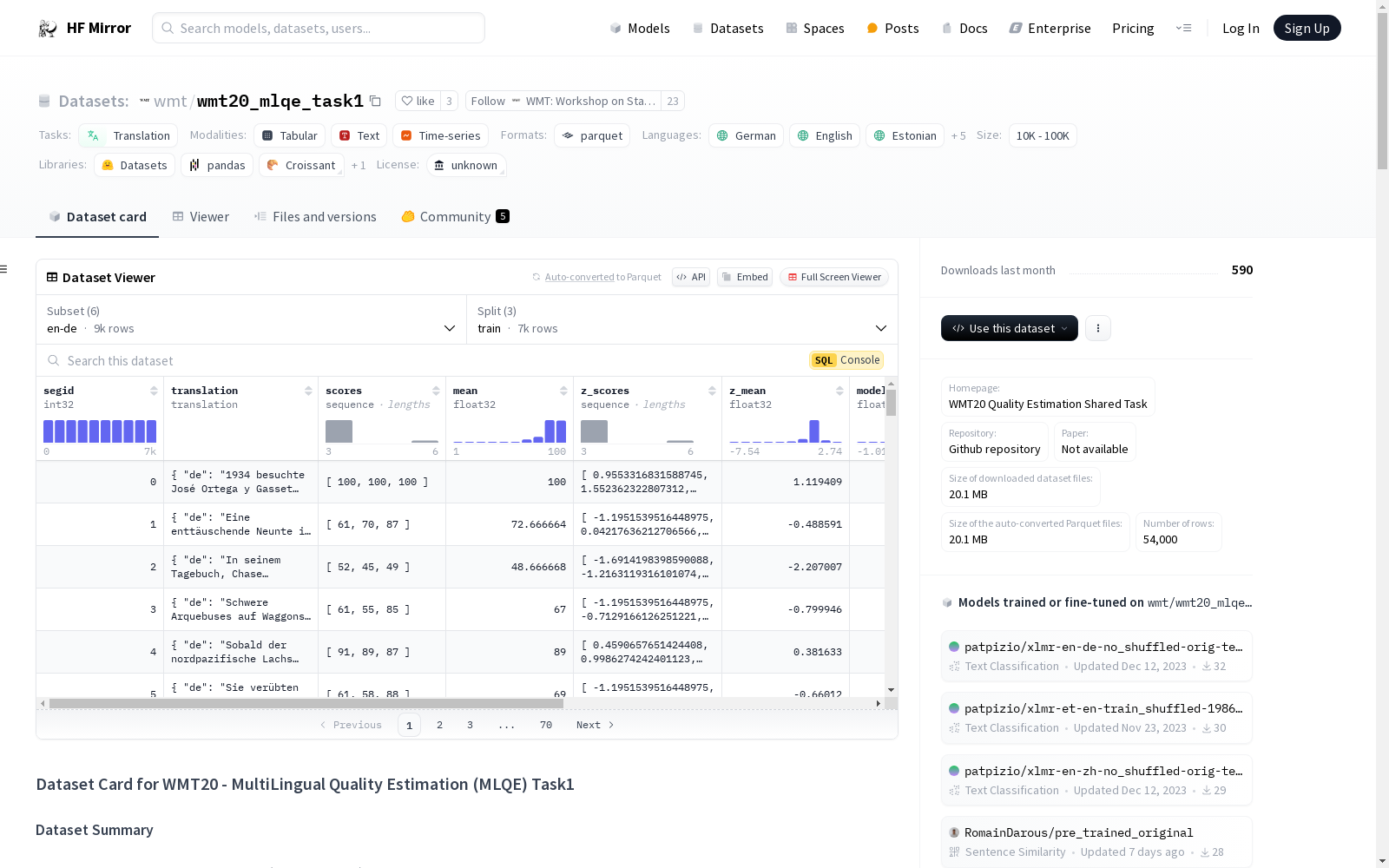
- 特征: 每个数据实例包括segid, translation, scores, mean, z_scores, z_mean, model_score, doc_id, nmt_output, word_probas。
- 分割: 数据集分为训练集、测试集和验证集,每部分包含1000至7000个实例。
数据集创建
- 来源: 数据源自Wikipedia和Reddit,通过fairseq工具包的NMT模型翻译并由专业翻译者评分。
- 评分方法: 使用Direct Assessment (DA) 评分,每个句子至少由三位专业翻译者评分,范围0-100。
使用考虑
- 许可证: 未知。
- 评估指标: 使用Pearsons correlation metric评估DA预测与人类DA的一致性。
附加信息
- 贡献者: 感谢@VictorSanh添加此数据集。
数据集详细信息
配置和数据文件
- 配置:
- en-de, en-zh, et-en, ne-en, ro-en, ru-en, si-en
- 数据文件:
- 每个配置包含train, test, validation三个分割的数据文件。
数据集大小和下载大小
- 大小:
- en-de: 4539012字节
- en-zh: 4269820字节
- et-en: 4542456字节
- ne-en: 6865534字节
- ro-en: 4368760字节
- ru-en: 4498908字节
- si-en: 6656994字节
- 下载大小:
- en-de: 3293699字节
- en-zh: 3325683字节
- et-en: 3109847字节
- ne-en: 3740258字节
- ro-en: 2938820字节
- ru-en: 2123684字节
- si-en: 3661522字节
数据集特征
- segid: 段ID,数据类型为int32。
- translation: 翻译文本,包含源语言和目标语言。
- scores: 评分序列,数据类型为float32。
- mean: 平均评分,数据类型为float32。
- z_scores: z标准化评分序列,数据类型为float32。
- z_mean: z标准化平均评分,数据类型为float32。
- model_score: 模型评分,数据类型为float32。
- doc_id: 文档ID,数据类型为string。
- nmt_output: NMT模型输出,数据类型为string。
- word_probas: 单词概率序列,数据类型为float32。
搜集汇总
数据集介绍
构建方式
WMT20 - MultiLingual Quality Estimation (MLQE) Task1 数据集的构建基于多语言翻译质量评估的需求,主要从维基百科和Reddit等来源提取原始文本。这些文本通过使用fairseq工具包构建的先进神经机器翻译(NMT)模型进行翻译,并由专业翻译人员进行直接评估(DA)评分。每个句子至少由三位专业翻译人员根据翻译质量进行评分,评分范围从0到100。数据集涵盖了高资源语言对(如英语-德语、英语-中文)、中等资源语言对(如罗马尼亚语-英语、爱沙尼亚语-英语)以及低资源语言对(如僧伽罗语-英语、尼泊尔语-英语)。
特点
该数据集的特点在于其多语言覆盖范围广泛,涵盖了从高资源到低资源的多种语言对。每个数据实例包含原始句子、翻译句子、直接评估评分、标准化评分以及NMT模型的输出和词级概率。数据集的结构清晰,分为训练集、验证集和测试集,每个语言对的配置均包含7000个训练样本、1000个验证样本和1000个测试样本。此外,数据集的评分经过标准化处理,确保了评分的可比性和一致性。
使用方法
WMT20 - MultiLingual Quality Estimation (MLQE) Task1 数据集主要用于多语言翻译质量评估任务。研究人员可以使用该数据集训练和评估翻译质量估计模型,特别是那些能够处理多种语言的系统。数据集中的标准化评分(z_mean)是评估模型性能的关键指标,通常使用皮尔逊相关系数来衡量模型预测与人类评分之间的相关性。此外,数据集还可以用于探索NMT模型内部信息对翻译质量估计的影响,以及在不同语言对上的表现差异。
背景与挑战
背景概述
WMT20 - MultiLingual Quality Estimation (MLQE) Task1 数据集是2020年世界机器翻译大会(WMT)的一部分,专注于多语言质量估计任务。该数据集由Facebook Research等机构的研究人员创建,旨在评估神经机器翻译(NMT)输出的质量,而无需依赖参考翻译。数据集涵盖了多种语言对,包括高资源语言对(如英语-德语、英语-中文)、中等资源语言对(如罗马尼亚语-英语、爱沙尼亚语-英语)以及低资源语言对(如僧伽罗语-英语、尼泊尔语-英语)。数据集的构建基于从维基百科和Reddit等来源提取的文本,并通过专业翻译人员进行直接评估(DA)评分。该数据集为多语言质量估计领域的研究提供了重要的基准,推动了机器翻译质量评估技术的发展。
当前挑战
WMT20 - MultiLingual Quality Estimation (MLQE) Task1 数据集面临的主要挑战包括:首先,多语言质量估计任务需要处理不同语言之间的复杂性和多样性,尤其是在低资源语言对中,数据稀缺性和语言结构的差异增加了模型的训练难度。其次,数据集的构建依赖于专业翻译人员的直接评估评分,这一过程不仅耗时且成本高昂,还可能引入主观偏差。此外,数据集中部分语言对的样本量相对较少,可能导致模型在这些语言对上的泛化能力不足。最后,尽管数据集提供了NMT模型的内部信息(如词级概率),但如何有效利用这些信息以提高质量估计的准确性仍是一个开放的研究问题。
常用场景
经典使用场景
WMT20 - MultiLingual Quality Estimation (MLQE) Task1 数据集在机器翻译质量评估领域具有重要应用。该数据集通过提供多语言对的翻译句子及其直接评估(DA)分数,为研究者提供了一个标准化的平台,用于开发和测试质量评估模型。经典的使用场景包括训练和验证自动翻译质量预测模型,特别是在没有参考翻译的情况下,评估神经机器翻译(NMT)输出的质量。
实际应用
在实际应用中,WMT20 - MultiLingual Quality Estimation (MLQE) Task1 数据集被广泛应用于翻译系统的质量监控和优化。例如,翻译服务提供商可以利用该数据集训练的质量评估模型,实时检测翻译输出的质量,并根据评估结果进行系统调整。此外,该数据集还可用于教育领域,帮助语言学习者理解翻译质量的评估标准,提升翻译技能。
衍生相关工作
基于 WMT20 - MultiLingual Quality Estimation (MLQE) Task1 数据集,研究者们开发了多种先进的翻译质量评估模型。例如,一些工作利用深度学习技术,结合数据集提供的直接评估分数,构建了更为精确的质量预测模型。此外,该数据集还促进了多语言翻译质量评估方法的研究,推动了跨语言翻译质量评估技术的发展。这些衍生工作不仅提升了翻译质量评估的准确性,还为机器翻译系统的优化提供了有力支持。
以上内容由遇见数据集搜集并总结生成


