SaSLaW
收藏arXiv2024-08-13 更新2024-08-15 收录
下载链接:
https://github.com/sarulab-speech/SaSLaW
下载链接
链接失效反馈官方服务:
资源简介:
SaSLaW是由东京大学等机构创建的自发性对话语音语料库,包含同步记录的说话者、听者和观看者的音频-视觉信息。该数据集旨在模拟真实环境中的语音通信,通过记录两位参与者在模拟嘈杂环境中的对话来收集数据。数据集的创建过程包括使用高采样率的麦克风和头戴式摄像机进行同步记录,以及对环境噪音的模拟。SaSLaW主要用于开发和评估环境适应性文本到语音合成模型,以实现更自然和无缝的对话通信。
提供机构:
东京大学, 庆应大学, 国立先进工业科学技术研究所
创建时间:
2024-08-13
搜集汇总
数据集介绍
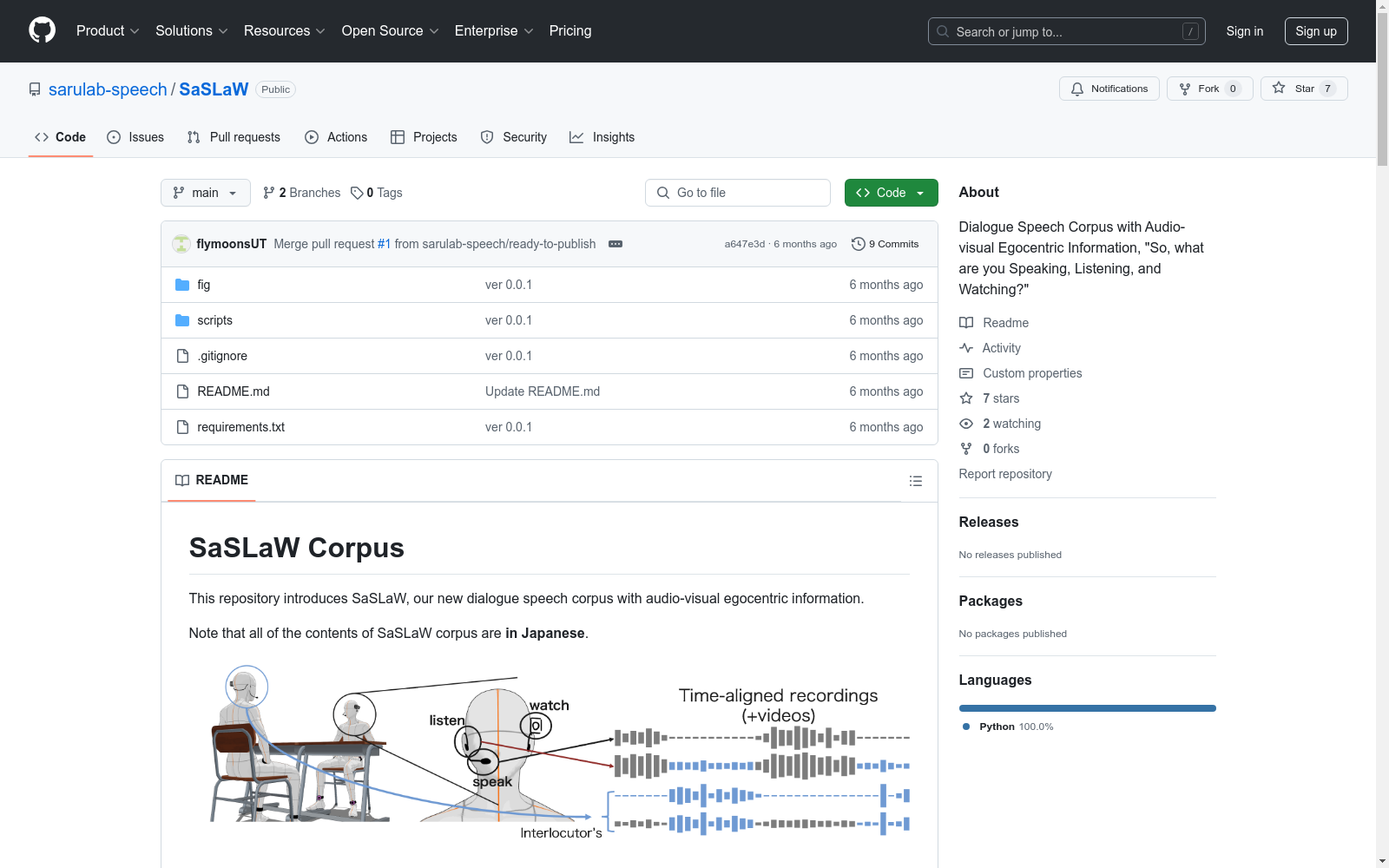
构建方式
SaSLaW数据集的构建旨在捕捉人类在面对面交流中对音频环境的适应。该数据集通过同步录制说话者所说的、听到的和看到的内容来实现这一目标。为了模拟真实世界的环境,数据集在模拟的嘈杂环境中录制了两名参与者面对面的自然对话。参与者配备了佩戴式麦克风和头戴式摄像头,分别用于录制说话者的声音、听到的声音和看到的视觉信息。此外,为了模拟不同类型的噪声环境,数据集使用了八个扬声器播放不同的环境噪声片段。最后,数据集还包括了说话者之间的声音脉冲响应和听众位置的背景噪声,以便进行可重复的评价。
特点
SaSLaW数据集具有以下特点:1. 包含同步录制的说话者所说的、听到的和看到的内容,提供了丰富的多模态信息;2. 在模拟的嘈杂环境中录制,模拟真实世界的音频环境;3. 包括说话者之间的声音脉冲响应和听众位置的背景噪声,用于可重复的评价。
使用方法
使用SaSLaW数据集的方法包括:1. 构建环境自适应TTS模型,通过使用说话者的听觉感知作为输入,生成适应不同音频环境的自然语音;2. 进行主观和客观评价,评估合成语音在不同音频环境中的自然度和可懂度。
背景与挑战
背景概述
随着语音合成技术在对话系统中的应用日益广泛,环境适应性对话语音合成(EA-TTS)成为了研究的热点。SaSLaW数据集,由东京大学、庆应大学和日本国立先进工业科学技术研究所(AIST)的研究人员开发,旨在通过第一人称音频-视觉感知来模拟人类在自然对话中对音频环境的适应。该数据集包含同步记录的说话者所说的、听到的和看到的内容,为EA-TTS模型提供了必要的音频环境输入。通过使用SaSLaW数据集,研究人员能够构建出能够适应不同音频环境的自然且流畅的语音合成模型,这对于推动对话系统在现实环境中的应用具有重要意义。
当前挑战
SaSLaW数据集在构建过程中面临的主要挑战包括:1) 环境适应性语音合成的挑战,即如何使语音合成模型能够根据不同的音频环境(如背景噪音、说话者之间的物理距离等)调整语音特征,以实现自然且流畅的语音交流;2) 构建数据集的挑战,包括如何同步记录说话者所说的、听到的和看到的内容,以及如何模拟现实世界中的各种音频环境。此外,由于SaSLaW数据集的规模相对较小,因此在构建EA-TTS模型时,如何有效地利用这些数据进行训练,并避免过拟合问题,也是一个重要的挑战。
常用场景
经典使用场景
SaSLaW数据集最经典的使用场景在于构建环境自适应文本到语音合成模型。通过同步记录说话者所说、所听和所见的内容,该数据集为模拟人类在面对面语音交流中对音频环境的适应性调整提供了基础。这种适应性调整基于人类感知到的听觉和视觉信息,从而使得语音对话系统能够在真实环境中实现自然和无缝的交流。
实际应用
SaSLaW数据集在实际应用中,可以帮助构建更自然、更符合真实环境需求的语音对话系统。例如,在智能家居、智能客服等领域,环境自适应文本到语音合成模型可以根据周围噪音、说话者距离等因素自动调整语音的音量、语速等特征,从而提高语音交流的清晰度和自然度。此外,该数据集还可以用于语音识别、语音合成等方面的研究,为语音技术的进一步发展提供支持。
衍生相关工作
SaSLaW数据集的构建方法和技术为后续的相关研究提供了参考和借鉴。例如,可以进一步研究如何将视觉信息融入到环境自适应文本到语音合成模型中,从而进一步提高语音合成的自然度和真实感。此外,还可以探索如何利用SaSLaW数据集构建更精确的语音识别模型,从而提高语音对话系统的准确率和鲁棒性。
以上内容由遇见数据集搜集并总结生成


