V-STaR
收藏arXiv2025-03-14 更新2025-03-18 收录
下载链接:
https://V-STaR-Bench.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
V-STaR数据集是由伦敦玛丽女王大学、南京大学和南洋理工大学的研究人员构建的,旨在评估视频大型语言模型在视频时空推理方面的能力。该数据集包含由半自动化GPT-4驱动的管道生成的粗到细的CoT问题,模仿人类的认知过程,嵌入明确的推理链。数据集通过分解视频理解任务为逆时空推理任务,同时评估模型在识别对象、事件发生时间和对象位置方面的能力,以及模型构建CoT逻辑的过程。
V-STaR dataset was constructed by researchers from Queen Mary University of London, Nanjing University and Nanyang Technological University, with the aim of evaluating the capabilities of video large language models (LLMs) in video spatio-temporal reasoning. The dataset comprises coarse-to-fine Chain-of-Thought (CoT) questions generated via a semi-automated GPT-4-driven pipeline, which mimics human cognitive processes and embeds explicit reasoning chains. Furthermore, the dataset decomposes video understanding tasks into reverse spatio-temporal reasoning tasks, while simultaneously assessing the model's abilities in object recognition, event timing detection, object localization, as well as the process through which the model constructs CoT reasoning logic.
提供机构:
伦敦玛丽女王大学, 南京大学, 南洋理工大学
创建时间:
2025-03-14
搜集汇总
数据集介绍
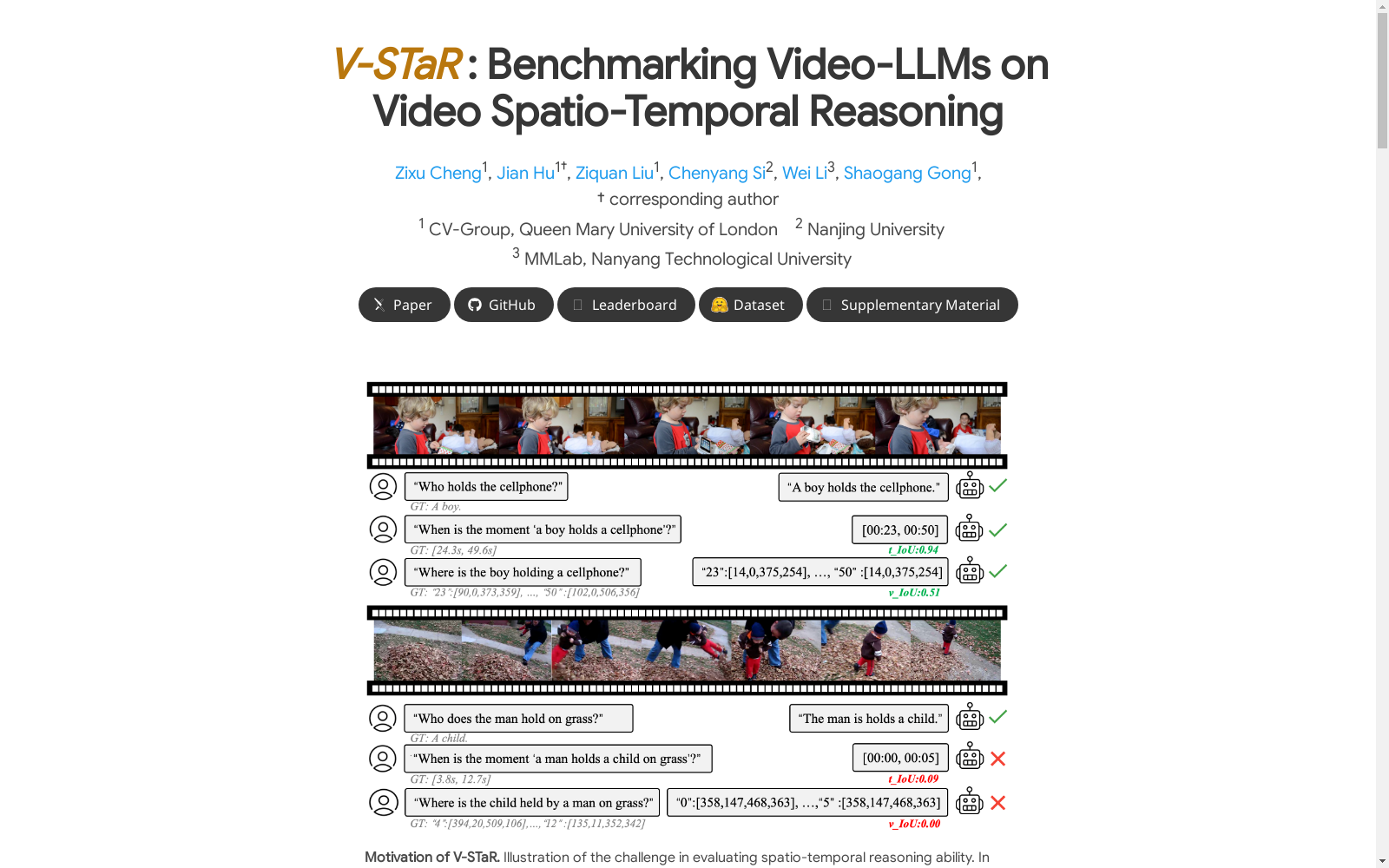
构建方式
V-STaR数据集的构建采用了半自动化的GPT-4驱动流程,结合了人工检查和过滤机制。首先,从现有数据集中收集带有时空标注的视频,并通过GPT-4生成粗到细的推理链问题。这些问题旨在模拟人类的认知过程,嵌入显式的推理链以评估视频大语言模型(Video-LLMs)的时空推理能力。随后,通过人工验证生成的推理链和问题,确保其逻辑一致性和准确性。最终,数据集包含从多个视频源中提取的时空推理问题,涵盖了广泛的视频内容和时长。
特点
V-STaR数据集的特点在于其专注于评估视频大语言模型的时空推理能力。数据集通过分解视频理解任务为“什么”、“何时”和“何处”三个子任务,构建了反向时空推理(RSTR)任务链。每个问题链都包含显式的推理步骤,能够独立评估模型在时空推理中的表现。此外,数据集还引入了对数几何平均(LGM)指标,综合评估模型在时空推理中的整体表现。这种设计使得V-STaR能够更全面地揭示模型在时空推理中的局限性。
使用方法
V-STaR数据集的使用方法主要围绕反向时空推理(RSTR)任务展开。用户可以通过数据集中的问题链,评估视频大语言模型在“什么”、“何时”和“何处”三个维度上的表现。每个问题链都包含从粗到细的推理步骤,用户可以根据模型的回答,逐步验证其在时空推理中的准确性。此外,数据集还提供了对数几何平均(LGM)和算术平均(AM)等指标,帮助用户综合评估模型的推理能力。通过这种方式,V-STaR能够为视频大语言模型的时空推理能力提供系统化的评估框架。
背景与挑战
背景概述
V-STaR(Video Spatio-Temporal Reasoning)数据集由伦敦玛丽女王大学、南京大学和南洋理工大学的研究团队于2025年提出,旨在评估视频大语言模型(Video-LLMs)在视频时空推理任务中的表现。该数据集的核心研究问题在于如何量化模型在视频理解中对空间、时间和因果关系的整合能力。传统的视频理解基准主要关注对象识别,而忽视了模型是否真正理解对象之间的时空交互。V-STaR通过引入逆向时空推理任务(RSTR),将视频理解分解为“何时”、“何地”和“什么”三个子任务,并结合链式思维(CoT)逻辑,填补了这一领域的空白。该数据集的提出为视频理解领域提供了新的评估框架,推动了模型在复杂时空推理任务中的发展。
当前挑战
V-STaR数据集面临的挑战主要体现在两个方面。首先,在领域问题上,现有视频大语言模型在回答“何时”和“何地”问题时表现不稳定,往往依赖于预训练中的共现偏差而非真正的时空推理能力。这种不一致性使得模型在复杂视频理解任务中的可靠性受到质疑。其次,在数据构建过程中,生成精确的时空推理链和问题对是一项艰巨的任务。研究团队采用半自动化的GPT-4驱动流程生成问题,但仍需大量人工验证以确保推理链的逻辑正确性。此外,视频的多样性和长度差异也增加了数据标注的复杂性,尤其是在长视频中保持时空一致性尤为困难。这些挑战凸显了视频时空推理任务的复杂性,也为未来研究提供了改进方向。
常用场景
经典使用场景
V-STaR数据集主要用于评估视频大语言模型(Video-LLMs)在视频时空推理任务中的表现。通过分解视频理解任务为逆向时空推理(RSTR)任务,V-STaR能够同时评估模型在识别对象(‘what’)、事件发生时间(‘when’)以及对象位置(‘where’)方面的能力。该数据集通过半自动化的GPT-4驱动流程生成从粗到细的推理链问题,模拟人类的认知过程,从而为模型提供结构化的评估框架。
衍生相关工作
V-STaR数据集的推出催生了一系列相关研究工作,特别是在视频大语言模型的时空推理能力评估方面。例如,基于V-STaR的评估框架,研究者开发了多种改进模型,如TimeChat和VTimeLLM,专注于视频时间定位任务;Qwen2.5-VL和VideoLlama3则在时空推理任务中表现出色。此外,V-STaR的逆向时空推理任务设计也启发了其他基准的改进,如TVQA+和VidSTG,进一步推动了视频理解领域的研究进展。
数据集最近研究
最新研究方向
近年来,视频时空推理(Video Spatio-Temporal Reasoning)领域的研究逐渐成为人工智能的热点之一,尤其是在视频大语言模型(Video-LLMs)的应用中。V-STaR数据集的提出填补了现有基准测试在评估模型时空推理能力方面的空白。该数据集通过分解视频理解任务为逆向时空推理(RSTR)任务,评估模型在‘何时’、‘何地’和‘什么’三个维度上的表现,并引入了链式思维(CoT)推理逻辑,模拟人类的认知过程。V-STaR的独特之处在于其通过半自动化的GPT-4生成管道,构建了从粗到细的CoT问题,从而更系统地评估模型的时空推理能力。实验结果表明,尽管现有模型在对象识别(‘什么’)上表现良好,但在时间和空间推理(‘何时’和‘何地’)上仍存在显著差距,揭示了当前模型在时空因果关系理解上的不足。这一发现为未来提升视频大语言模型的时空推理能力提供了重要方向。
相关研究论文
- 1V-STaR: Benchmarking Video-LLMs on Video Spatio-Temporal Reasoning伦敦玛丽女王大学, 南京大学, 南洋理工大学 · 2025年
以上内容由遇见数据集搜集并总结生成


