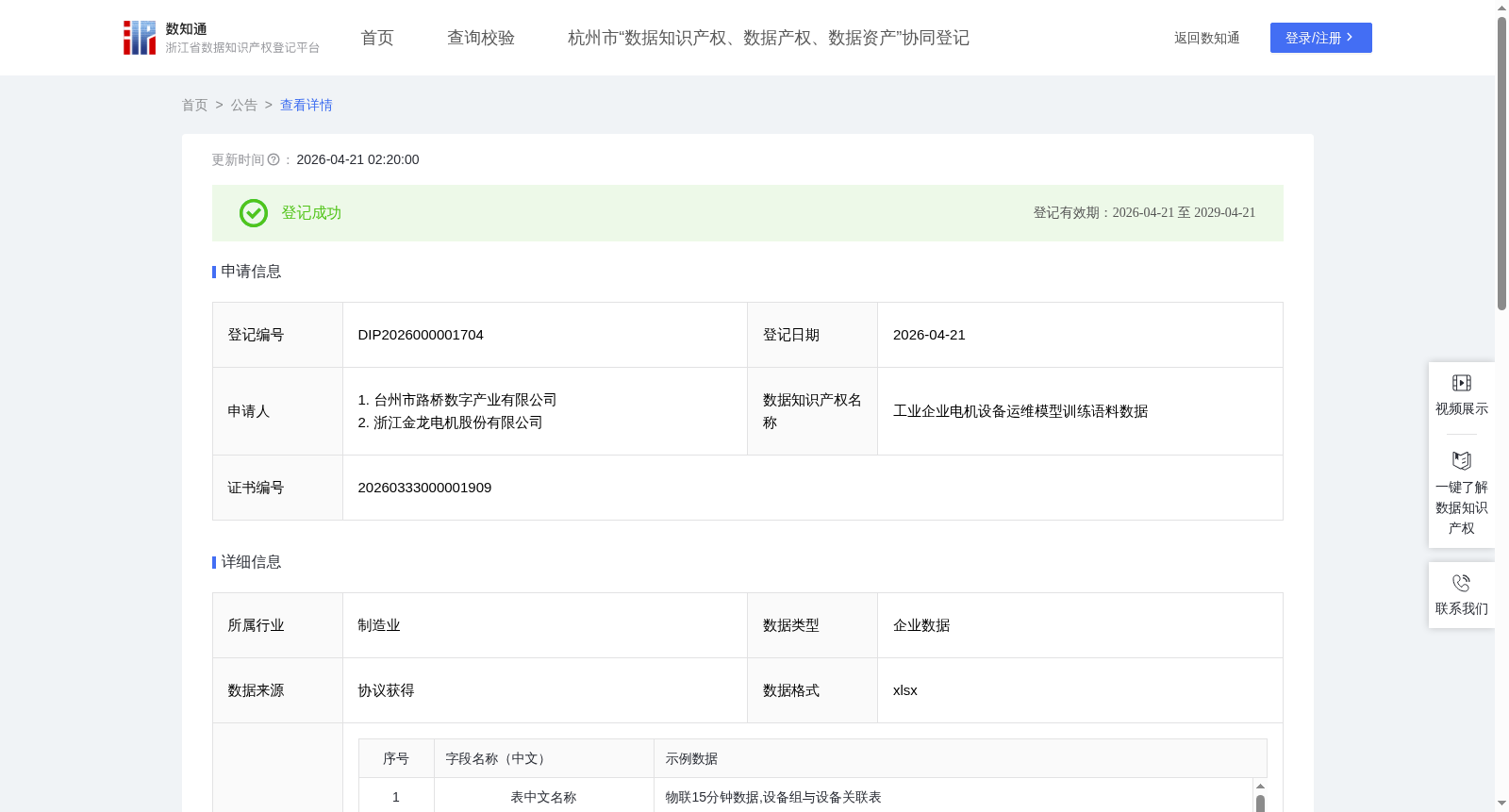
工业企业电机设备运维模型训练语料数据
收藏浙江省数据知识产权登记平台2026-04-21 更新2026-04-22 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8438298
下载链接
链接失效反馈官方服务:
资源简介:
本数据产品专为训练工业企业设备运维垂类大语言模型而构建,旨在让模型能够深度理解企业日常设备管理与运维场景中的自然语言问题,并精准转化为可执行的SQL查询语句,从而实现设备运行数据的即时、高效查询与分析。依托企业真实经营数据构建标准化语料体系,模型经训练后可精准理解“合格率计算”“不良品追溯”等工业质检特有需求,工业企业可基于本语料数据的分类如“指标名称”“问题查询”等字段内容,适配自身数据表结构(如替换建表语句中的表名、字段名),快速启用文字转SQL功能进行复用。本数据为工业企业提供了稀缺的、高质量的垂直领域语料,有力支撑了设备运维领域的自然语言处理技术研发、模型训练与评测,对推动工业企业设备数据价值的深度挖掘和智能运维技术的发展具有重要意义。1.数据清洗与标准化:
数据清洗:对从设备管理系统(如MES、SCADA)收集的原始问答对进行清洗,剔除重复、无效或存在明显逻辑矛盾的样本。例如,表格中“结果输出”为“无匹配数据”的样本,作为查询无返回结果的标准语料被保留,增强了模型对数据缺失场景的理解能力。
格式统一:统一问题表述中的时间格式(如“11月01日”)、指标名称(如“稼动率”)和SQL语法风格,确保语料的规范性和一致性。对建表语句进行格式化,统一字段类型和注释风格。
2.问题分类与结构化:
按照设备运维的特定场景对问题进行归类,主要包括趋势分析(如“每日稼动率”)、排名查询(如“能耗前三的部门”)、阈值查询(如“待机时长前20的设备”)、单点查询(如“数控车床-B1187稼动率”)等,确保语料对设备运维核心场景的全面覆盖。
3.核心算法建模:
(1)语义解析与要素提取:采用基于规则和词典的文本分析方法,对自然语言问题进行解析,精准提取关键要素,如时间(“10月20日”)、对象(“数控车床-B1187”)、指标(“稼动率”)和约束条件(“前3”)。
(2)SQL语句生成:基于预定义的“指标-字段”映射规则和“对象-过滤条件”映射规则,自动生成标准化的SQL查询语句。
(3)异常值检测:对生成的SQL及其执行结果进行双重校验。一方面,利用IsolationForest等算法检测SQL语句的逻辑异常(如缺失必要的关联条件);另一方面,结合数据统计特征,识别结果中可能存在的异常值(如产量或能耗为0的极端情况),并打标或过滤,确保语料质量。
(4)逻辑核验与业务对齐:由资深设备运维人员对生成的问题-SQL-结果三元组进行最终核验。运维人员结合现场业务知识,判断SQL逻辑是否正确(如使用left join而不是inner join)、结果是否合理(如待机时长的计算结果是否符合设备实际运行日志),确保语料不仅语法正确,更具备高度的业务适用性和准确性。
4.语料库的持续迭代:
构建语料库的闭环迭代机制。新产生的业务问题及其经核验的SQL语句会定期注入语料库。同时,通过分析大语言模型在实际应用中的反馈(如查询失败、语义理解错误),定位语料库的薄弱环节并进行针对性补充,形成“应用-反馈-优化”的良性循环,持续提升语料库的覆盖度和质量。
提供机构:
台州市路桥数字产业有限公司,浙江金龙电机股份有限公司
创建时间:
2026-03-20
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个专门用于训练工业企业设备运维垂类大语言模型的语料集合,包含1993条结构化数据,以xlsx格式提供。它基于真实企业设备运维场景构建,覆盖趋势分析、排名查询等核心需求,通过标准化清洗和算法建模,确保自然语言问题能精准转换为可执行的SQL查询,助力企业实现设备数据的智能分析与价值挖掘。
以上内容由遇见数据集搜集并总结生成


