david-thrower/HelixLM-tiny-400.0Mt-730000pt-57143it-20260430
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/david-thrower/HelixLM-tiny-400.0Mt-730000pt-57143it-20260430
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个经过缩放的子集,从三个高质量来源中精选而来,推荐比例为:FineWeb-Edu(约85%)、OpenWebMath(约10%)和OpenHermes-2.5(约5%)。数据集分为预训练和指令调优两部分:预训练部分包括pretrain_train和pretrain_val(来自FineWeb-Edu和OpenWebMath),指令调优部分包括instruct_train和instruct_val(来自OpenHermes-2.5,格式化为包含系统、用户、助手和结束标记的对话形式)。数据准备包括流式加载、10,000的随机缓冲区、2%的验证集保留以及鲁棒的指令格式检测。
This dataset is a scaled subset curated from three high-quality sources in the recommended ratios: FineWeb-Edu (~85%), OpenWebMath (~10%), and OpenHermes-2.5 (~5%). The dataset is split into pretraining and instruction tuning portions: the pretraining portion includes pretrain_train and pretrain_val (from FineWeb-Edu and OpenWebMath), and the instruction tuning portion includes instruct_train and instruct_val (from OpenHermes-2.5, formatted with system, user, assistant, and end-of-text markers). Data preparation involves streaming load with a shuffle buffer of 10,000, a 2% validation holdout per split, and robust schema detection for instruction formatting.
提供机构:
david-thrower
搜集汇总
数据集介绍
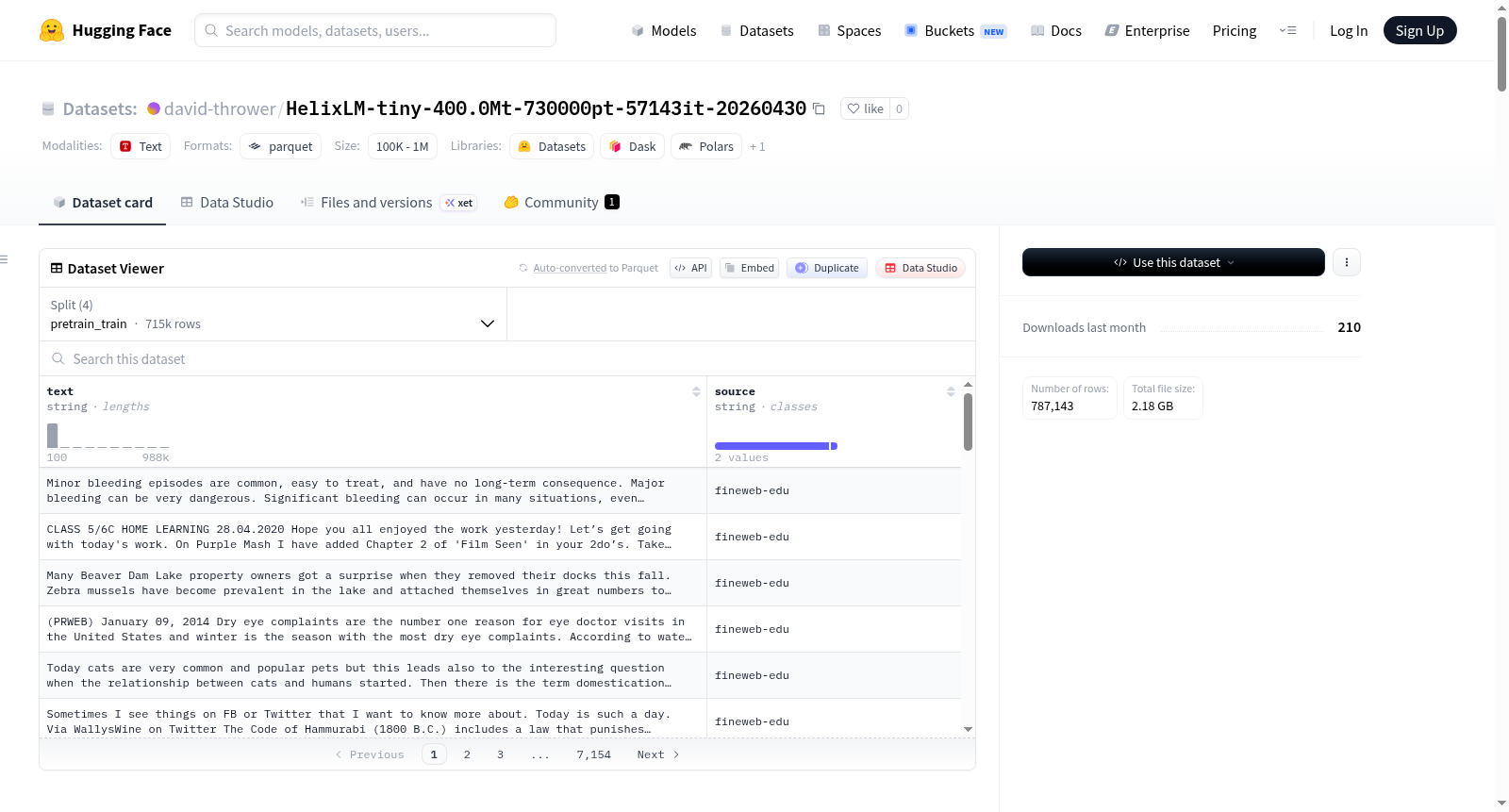
构建方式
HelixLM-tiny-400.0Mt-730000pt-57143it-20260430 数据集是为 HelixLM 模型精心构建的混合语料库,由三部分高质量数据按特定比例融合而成。其中,FineWeb-Edu 的 sample-10BT 子集占比约 85%,提供优质教育类网络文本用于预训练;OpenWebMath 的训练集占比约 10%,贡献数学推理与 STEM 内容;OpenHermes-2.5 的训练集占比约 5%,提供指令遵循与对话数据。数据集划分为预训练和指令微调两大分支,每一分支均包含训练与验证子集。预训练数据由 FineWeb-Edu 与 OpenWebMath 组成,指令微调数据则采用 <|system|>、<|user|>、<|assistant|>、<|endoftext|> 等特殊标记进行格式化。数据加载采用流式方式,配合容量为 10,000 的洗牌缓冲区,避免完整下载语料库。每个分支均保留 2% 作为验证集,并具备鲁棒的指令格式模式检测能力,可自动识别 conversations、messages、instruction/response 等多种常见对话结构。
特点
该数据集最显著的特点在于其精心设计的规模与结构适配性。总数据量约 400M token,包含 730,000 条预训练样本和 57,143 条指令样本,为 HelixLM tiny 配置(20M 参数)提供恰到好处的训练素材。预训练集和指令集均独立划分验证子集,确保训练过程的监控与评估。数据集以流式加载设计为核心,大幅降低内存占用,使得在消费级硬件上即可完成完整训练流程。另外,数据来源的多样性兼顾语言理解、数学推理与对话能力,为模型注入均衡的知识结构。指令数据采用标准化标记格式,支持多轮对话,可直接用于监督微调。数据集文件的组织方式支持按前缀模式加载,便于分布式训练与灵活的子集选择。
使用方法
使用该数据集时,推荐通过 HuggingFace Datasets 库以流式方式加载,指定相应 split 名称即可获取所需子集。对于预训练阶段,应使用 pretrain_train 与 pretrain_val 进行训练与验证,指令微调则调用 instruct_train 与 instruct_val。数据处理时,可直接利用数据集自带的 text 字段进行分词与序列化,source 字段可留作溯源分析。建议训练时采用滚动分块策略,对长文档施加步进与注意力掩码处理,对短文档进行填充。指令微调阶段建议采用标准对话模板,将每条样本中的 system、user、assistant 角色依次拼接后输入模型。由于数据集体积适中且支持流式加载,用户无需下载全部内容即可开始训练,尤其适合在单 GPU 或 CPU 环境下的超个性化模型定制与快速实验迭代。
背景与挑战
背景概述
HelixLM数据集由David Thrower及其团队于2026年创建,旨在推动小规模语言模型的超个性化和设备端AI部署。该数据集整合了FineWeb-Edu、OpenWebMath和OpenHermes-2.5三大高质量语料库,形成约400Mt的预训练指令微调数据,为HelixLM循环异构图神经语言模型提供训练基础。HelixLM架构模仿生物皮层柱,采用异质节点、横向短连接和递归反馈机制,打破传统Transformer固定深度堆叠的限制。该数据集与模型的设计理念在于通过参数高效的方式实现个性化适应,而非追逐通用前沿模型的广博知识,这一思路在小模型生态中构建了独特的研究路径,为资源受限场景下的语言建模开辟了新方向。
当前挑战
该数据集所解决的领域挑战聚焦于小模型在超个性化和设备端推理中的效率与适应性瓶颈。传统语言模型往往依赖大规模参数与海量数据以实现通用性能,难以在低算力环境下针对个体用户进行快速微调。此外,HelixLM递归图架构中随机初始化的图连接引入了确定性复现的难点,需要固定随机种子以确保实验可比性。在构建过程中,团队面临多源异构数据(教育文本、数学推理、对话格式)的统一与对齐挑战,需设计灵活的架构指令方案以兼容多种消息格式。同时,开源社区对前沿无监督数据进行了大量人工筛选与配比(85%、10%、5%),以平衡预训练阶段的通识教育价值与指令微调阶段的任务导向能力,这种精细化的混合策略本身就是一项数据工程上的重要挑战。
常用场景
经典使用场景
HelixLM-tiny-400.0Mt-730000pt-57143it-20260430 数据集作为 HelixLM 小规模语言模型的核心训练语料,其经典使用场景在于支撑基于循环异构图神经架构的语言模型预训练与指令微调。该数据集融合了高质量教育网页文本 FineWeb-Edu、数学推理语料 OpenWebMath 以及指令遵循对话数据 OpenHermes-2.5,以约 85%、10%、5% 的比例精心配比,分别用于预训练和指令微调。研究者可利用该数据集从零训练 HelixLM 的 tiny 预设模型(约 20M 参数),或在其上进行领域适配微调。数据以流式加载和自然分句处理为特色,支持变长序列与滚动分块策略,特别适合探索循环深度、异构节点和自适应计算时间等前沿语言建模课题。
实际应用
在现实部署中,该数据集驱动的 HelixLM 模型展现出了卓越的实用价值。由于其参数量精巧(tiny 预设仅约 20M),模型能够轻松运行于消费级 GPU 乃至 CPU 之上,特别适合部署在桌面电脑、平板和移动设备中,实现真正的端侧人工智能。数据集中包含的高质量指令数据使模型具备了基础的对话与任务理解能力,因此可被用于构建隐私敏感场景下的本地化智能助手,例如个人笔记整理、邮件草稿生成或离线知识问答。此外,数学语料的融入赋予了模型一定的逻辑推理能力,能够辅助教育应用中的题目解析与概念阐释。数据集的超个性化设计初衷尤为可贵,支持用户基于自身数据进行快速微调,从而打造专精于个人知识图谱的专属模型。
衍生相关工作
围绕该数据集及其依托的 HelixLM 架构,已经衍生出一系列引人深思的学术与实践探索。基于其循环图神经网络的设计理念,研究者进一步对比分析了 OpenMythos 的递归机制与 Cerebros 的图状态管理,明确了异构节点(如线性注意力、Mamba-2 状态空间模型和门控网络)在计算效率与表示能力上的协同优势。相关工作还包括对自适应计算时间(ACT)机制的深入剖析,揭示了该机制如何在不增加参数量的前提下,依据令牌复杂度动态分配循环深度,从而提升推理效率。此外,混合注意力策略的研究——即在高效线性注意力中稀疏插入精确软注意力层——为长序列处理提供了新的优化视角。这些衍生工作共同勾勒出一条从生物学启发架构到实际高效语言模型的清晰演进路径。
以上内容由遇见数据集搜集并总结生成


