NanoCodeSearchNet
收藏Hugging Face2026-01-25 更新2026-01-26 收录
下载链接:
https://huggingface.co/datasets/hotchpotch/NanoCodeSearchNet
下载链接
链接失效反馈官方服务:
资源简介:
NanoCodeSearchNet是一个小型、评估就绪的数据集,源自CodeSearchNet的测试集,旨在快速迭代和基准测试。数据集包含6种编程语言的子集(Go、Java、JavaScript、PHP、Python、Ruby),每个子集包含50个测试查询和最多10,000个代码片段。查询是函数文档字符串,正例是来自同一源行的相应函数体。数据集设计用于与Sentence Transformer的评估模块(InformationRetrievalEvaluator)集成,支持快速评估循环。
创建时间:
2026-01-13
原始信息汇总
NanoCodeSearchNet 数据集概述
数据集简介
NanoCodeSearchNet 是一个用于代码搜索评估的小型数据集,它提取自 CodeSearchNet 数据集的测试集。该数据集旨在提供一个轻量级、评估就绪的基准,以便在几分钟内完成迭代和基准测试,其设计灵感来源于 NanoBEIR。
数据集构成
数据集包含三种配置,分别对应代码搜索任务的不同组成部分:
- corpus (语料库): 包含代码片段。
- queries (查询): 包含函数文档字符串作为查询。
- qrels (相关性判断): 包含查询与相关文档的对应关系。
数据子集与规模
数据集按编程语言划分为6个子集,每个子集包含 corpus、queries 和 qrels 三部分。
语料库 (corpus) 规模
- NanoCodeSearchNetGo: 10,000 个示例,5,866,161 字节。
- NanoCodeSearchNetJava: 10,000 个示例,8,383,266 字节。
- NanoCodeSearchNetJavaScript: 6,483 个示例,6,817,497 字节。
- NanoCodeSearchNetPHP: 10,000 个示例,8,308,232 字节。
- NanoCodeSearchNetPython: 10,000 个示例,12,057,318 字节。
- NanoCodeSearchNetRuby: 2,279 个示例,1,456,896 字节。
- 总下载大小: 17,919,374 字节。
- 总数据集大小: 42,889,370 字节。
查询 (queries) 规模
每个语言子集均包含 50 个查询示例。
- NanoCodeSearchNetGo: 11,803 字节。
- NanoCodeSearchNetJava: 19,923 字节。
- NanoCodeSearchNetJavaScript: 15,444 字节。
- NanoCodeSearchNetPHP: 19,306 字节。
- NanoCodeSearchNetPython: 22,227 字节。
- NanoCodeSearchNetRuby: 30,739 字节。
- 总下载大小: 82,419 字节。
- 总数据集大小: 119,442 字节。
相关性判断 (qrels) 规模
每个语言子集均包含 50 个示例。
- NanoCodeSearchNetGo: 11,666 字节。
- NanoCodeSearchNetJava: 17,154 字节。
- NanoCodeSearchNetJavaScript: 12,376 字节。
- NanoCodeSearchNetPHP: 13,456 字节。
- NanoCodeSearchNetPython: 13,454 字节。
- NanoCodeSearchNetRuby: 12,948 字节。
- 总下载大小: 61,488 字节。
- 总数据集大小: 81,054 字节。
数据特征
- corpus 特征:
_id(字符串),text(字符串)。 - queries 特征:
_id(字符串),text(字符串)。 - qrels 特征:
query-id(字符串),corpus-id(字符串)。
评估基准
数据集提供了多个模型在 NDCG@10 指标下的评估结果,涵盖 Go、Java、JavaScript、PHP、Python 和 Ruby 语言子集及平均分。评估使用的脚本为:https://huggingface.co/datasets/hotchpotch/NanoCodeSearchNet/blob/main/nano_code_search_net_eval.py。
数据来源与构建
- 上游数据源: CodeSearchNet 数据集(测试集)。
- 采样方法: 确定性采样(种子为42)。
- 查询与正例关系: 查询是函数文档字符串,正例是来自同一源代码行的对应函数体。
- 查询ID格式:
q-<docid>,其中docid为可用的func_code_url。
许可证
- 许可证类型: Other。
- 说明: 本数据集衍生自 CodeSearchNet,并最终来源于开源 GitHub 仓库。请尊重原始仓库的许可证和署名要求。
作者
Yuichi Tateno
搜集汇总
数据集介绍
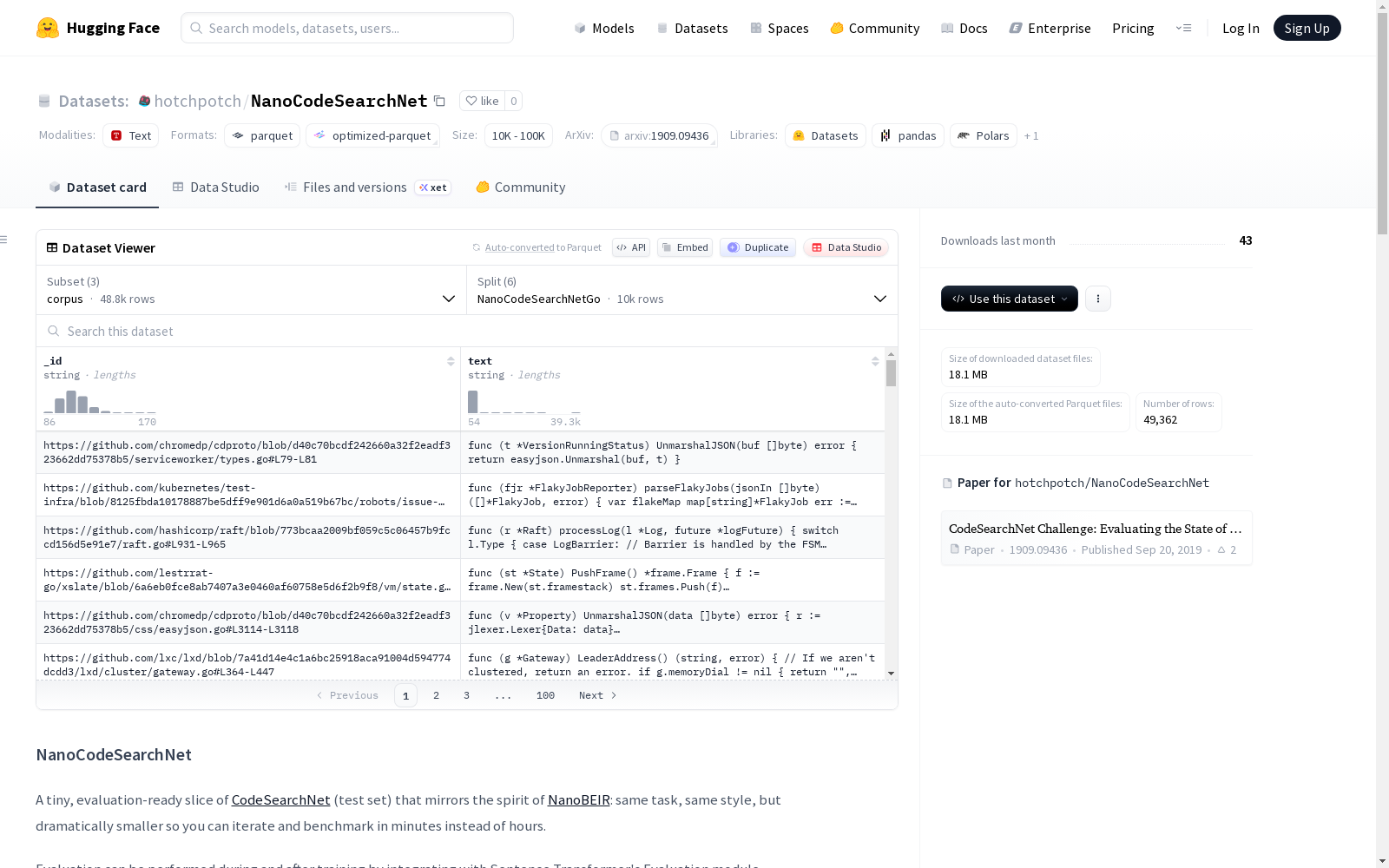
构建方式
在代码语义搜索领域,NanoCodeSearchNet的构建体现了高效评估的核心理念。该数据集源自CodeSearchNet的测试集,通过确定性采样方法(种子为42)提取出六个编程语言子集,每个子集包含50个查询和最多一万个代码片段。查询与代码片段之间的对应关系基于函数文档字符串与函数体的原始配对,确保了数据的内在一致性。这种构建方式不仅保留了原始数据集的任务特性,还通过精简规模实现了快速迭代评估的目标。
特点
NanoCodeSearchNet的显著特征在于其精巧的设计与多语言覆盖。数据集涵盖Go、Java、JavaScript、PHP、Python和Ruby六种编程语言,每个语言子集均包含查询、语料库和相关性标注三个标准组件。查询采用函数文档字符串形式,正例样本则对应原始代码函数体,这种设计精准模拟了真实代码搜索场景。数据集的轻量化特性使其能够在单GPU环境下快速完成评估循环,同时保持与BEIR评估框架的兼容性,为代码语义搜索模型提供了高效可靠的基准测试平台。
使用方法
使用该数据集时,研究人员可通过Hugging Face数据集库直接加载特定编程语言子集。标准流程包括分别加载查询、语料库和相关性标注三个配置,随后可集成Sentence Transformers的评估模块进行信息检索性能测试。数据集提供了专门的评估脚本,支持多种嵌入模型的标准评估,用户可通过指定模型路径和提示模板快速获得标准化评估结果。这种即插即用的设计使得模型对比和性能基准测试变得异常便捷,大幅提升了代码搜索领域的研究效率。
背景与挑战
背景概述
在软件工程与人工智能交叉领域,代码语义搜索旨在通过自然语言查询精准匹配相关代码片段,从而提升开发效率。NanoCodeSearchNet数据集由研究者Yuichi Tateno构建,灵感来源于NanoBEIR的轻量化评估理念,作为CodeSearchNet测试集的一个微型切片,于近年发布。该数据集聚焦于多编程语言环境下的代码检索任务,核心研究问题在于如何高效评估嵌入模型在跨语言代码搜索中的性能。其通过提供包含Go、Java、JavaScript、PHP、Python和Ruby六种语言的标准化查询、语料库及相关性标注,为快速模型迭代与基准测试提供了重要支撑,推动了代码智能领域评估方法的发展。
当前挑战
代码语义搜索领域长期面临查询与代码间语义鸿沟的挑战,即自然语言描述与编程语言语法之间的异构性匹配难题。NanoCodeSearchNet所针对的领域问题要求模型能够理解跨多种编程语言的复杂语义,并实现高精度检索,这需要克服语言特性差异及代码上下文稀疏性带来的表征困难。在数据集构建过程中,挑战主要源于从大规模原始CodeSearchNet数据中提取代表性样本,需通过确定性采样确保评估的可靠性与可复现性,同时维持各语言子集规模平衡以反映真实分布,并妥善处理上游开源代码的许可与归属问题,保障数据合规性。
常用场景
经典使用场景
在软件工程与人工智能交叉领域,代码语义搜索是提升开发者效率的关键技术。NanoCodeSearchNet作为CodeSearchNet的精简版本,其经典使用场景聚焦于评估信息检索模型在跨编程语言代码搜索任务上的性能。该数据集通过提供标准化的查询、文档库及相关性标注,支持研究者快速测试嵌入模型在自然语言查询与代码片段匹配任务中的表现,尤其适用于多语言代码检索基准测试,为模型迭代与比较提供了高效平台。
衍生相关工作
围绕NanoCodeSearchNet,已衍生出一系列专注于代码嵌入与检索的经典研究工作。例如,基于Sentence Transformers框架的评估模块被广泛用于该数据集的模型性能测评;同时,诸如multilingual-e5、bge-m3等先进嵌入模型均以此数据集作为关键基准,验证其在代码语义搜索任务上的有效性。这些工作进一步推动了轻量级评估范式在代码智能领域的发展与应用。
数据集最近研究
最新研究方向
在代码搜索领域,NanoCodeSearchNet作为轻量级评估数据集,正推动着多语言代码语义检索模型的高效迭代与优化。该数据集聚焦于前沿的代码智能研究方向,特别是结合大语言模型的代码理解与生成任务,成为评估模型跨编程语言泛化能力的关键基准。随着开源代码库的指数级增长,快速精准的代码检索技术日益重要,NanoCodeSearchNet通过提供标准化的多语言测试切片,促进了检索模型在真实开发场景中的性能验证,为自动化编程助手和智能开发工具的演进提供了坚实的实验基础。
以上内容由遇见数据集搜集并总结生成


