Infographics-650K
收藏arXiv2025-03-27 更新2025-03-28 收录
下载链接:
https://bizgen-msra.github.io
下载链接
链接失效反馈官方服务:
资源简介:
Infographics-650K是一个包含超过65万张高质量、高分辨率 infographic 样本的数据集,由清华大学、布朗大学等机构创建。该数据集涵盖了10种不同的语言,并具备详细的全球标题和图像以及超密集布局和区域特定标题。数据集通过分层检索增强的 infographic 生成方案构建,解决了商业内容生成中的数据稀缺问题。
Infographics-650K is a dataset consisting of over 650,000 high-quality, high-resolution infographic samples, developed by institutions including Tsinghua University, Brown University, and others. This dataset covers 10 distinct languages, and features detailed global titles and images, as well as ultra-dense layouts and region-specific captions. Constructed via a hierarchical retrieval-augmented infographic generation framework, the dataset addresses the data scarcity issue in commercial content generation.
提供机构:
清华大学, 布朗大学, 利物浦大学, 微软亚洲研究院, 微软
创建时间:
2025-03-27
原始信息汇总
BizGen 数据集概述
基本信息
- 标题: BizGen: Advancing Article-level Visual Text Rendering for Infographics Generation
- 作者:
- Yuyang Peng
- Shishi Xiao
- Keming Wu
- Qisheng Liao
- Bohan CHEN
- Kevin Lin
- Danqing Huang
- Ji Li
- Yuhui Yuan
- 机构:
- Tsinghua University
- Brown University
- University of Liverpool
- Microsoft Research Asia
- Microsoft
相关资源
- arXiv论文: https://arxiv.org/pdf/2503.20672
- 代码仓库: https://github.com/1230young/bizgen.git
- HuggingFace: https://huggingface.co/PYY2001/BizGen
数据集描述
- 主要用途: 用于生成信息图表(Infographics)的文章级视觉文本渲染
- 技术特点: 基于Glyph-ByT5-v3模型
搜集汇总
数据集介绍
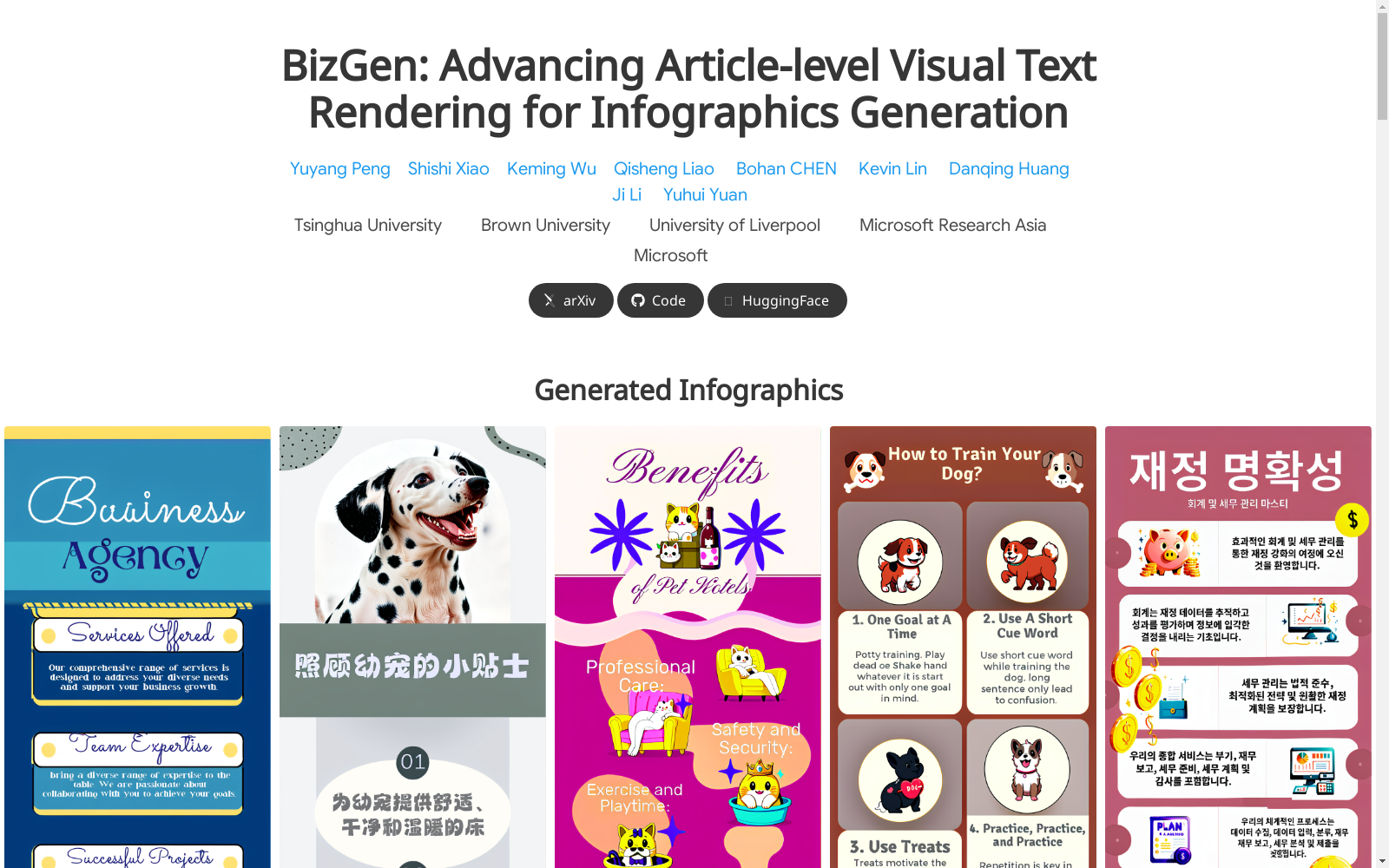
构建方式
Infographics-650K数据集的构建采用了分层检索增强的信息图生成方案,通过创新的数据引擎实现了高质量商业内容的大规模合成。研究团队首先收集了5000余张原始信息图及其分层布局数据,随后构建了包含100万+透明图层的数据库,并利用GPT-4o进行主导层识别和CLIP相似度检索,通过层替换策略生成65万张多语言、多风格的高分辨率信息图。该过程特别注重保持2240×896的高清分辨率,并通过LLaVA-1.6-34B模型生成细粒度的分层描述文本,有效解决了商业内容数据稀缺的核心挑战。
特点
该数据集最显著的特点是具备超密集布局特性,平均每张信息图包含约30个分层元素,支持十种语言的视觉文本渲染。不同于传统图文数据集,Infographics-650K不仅提供全局描述,还包含精确的区域级提示和边界框标注,支持对标题、副标题、正文等文章级长文本(500+字符)的精准控制。数据集样本在字符级OCR准确率方面表现优异,在737字符的长文本测试中达到97%的识别率,为视觉文本生成研究提供了前所未有的细粒度控制能力。
使用方法
使用该数据集时,建议采用论文提出的布局引导交叉注意力机制,将超长上下文建模任务分解为多个区域级生成任务。具体操作需先将输入潜特征根据布局先验裁剪为区域视觉标记,再与CLIP/Glyph-ByT5编码的文本标记进行分组注意力计算。推理阶段可采用布局条件CFG策略,通过动态调整不同分层的引导权重来消除伪影。该数据集特别适用于训练支持超密集布局的商业内容生成模型,如信息图、幻灯片等多元素复合媒体的生成任务。
背景与挑战
背景概述
Infographics-650K是由清华大学、布朗大学、利物浦大学及微软亚洲研究院等机构的研究团队于2025年推出的高质量商业内容生成数据集,专注于解决信息图表与幻灯片等复杂商业设计内容的生成问题。该数据集包含65万样本,覆盖10种语言,每个样本均配备超密集布局和区域级描述文本,旨在突破现有文本生成图像模型在长上下文处理与商业数据稀缺性方面的局限。其创新性的分层检索增强生成方案,显著提升了模型对超密集布局的遵循能力,为商业内容生成领域建立了新的技术基准。
当前挑战
Infographics-650K面临的核心挑战体现在两个维度:在领域问题层面,需解决传统文本生成图像模型在文章级视觉文本渲染中的拼写准确率骤降问题(如SD3模型在737字符场景下OCR准确率仅46%),同时应对信息图表特有的高密度元素空间排布与语义关联难题;在构建过程中,需克服商业设计数据获取成本高、标注复杂度指数级增长(单图平均30个图层)以及多语言视觉文本对齐等技术瓶颈。此外,2240×896超高分辨率要求与区域级细粒度控制的需求,进一步增加了数据引擎构建与模型训练的复杂度。
常用场景
经典使用场景
Infographics-650K数据集在信息图表生成领域具有广泛的应用场景,特别是在需要处理长文本和复杂布局的商业内容生成任务中。该数据集通过提供超密集布局和区域特定的提示,使得生成的信息图表能够精确地遵循设计要求,适用于商业报告、幻灯片设计、市场营销材料等多种场景。其高质量的数据和多样化的风格使其成为研究和开发信息图表生成模型的理想选择。
衍生相关工作
Infographics-650K数据集衍生了一系列相关研究和工作,特别是在布局引导的图像生成和多语言文本渲染领域。基于该数据集,研究人员开发了BizGen框架,该框架在信息图表生成任务中显著优于现有方法。此外,该数据集还被用于训练多层透明信息图表生成模型,进一步扩展了其在图形设计生成领域的应用范围。这些工作共同推动了商业内容生成技术的进步。
数据集最近研究
最新研究方向
近年来,Infographics-650K数据集在信息图表生成领域引起了广泛关注,特别是在文章级视觉文本渲染方面。该数据集通过超密集布局和区域特定提示,为高质量商业内容(如信息图表和幻灯片)的生成提供了重要支持。前沿研究方向主要集中在如何利用该数据集解决长上下文长度和数据稀缺性两大挑战。通过创新的层间检索增强信息图表生成方案和布局引导的交叉注意力机制,研究者能够更精确地控制生成内容,从而在视觉文本拼写准确性和区域控制方面显著优于现有技术。这一进展不仅推动了商业内容生成的发展,也为多语言、多风格信息图表的生成开辟了新的可能性。
相关研究论文
- 1BizGen: Advancing Article-level Visual Text Rendering for Infographics Generation清华大学, 布朗大学, 利物浦大学, 微软亚洲研究院, 微软 · 2025年
以上内容由遇见数据集搜集并总结生成


