africa-somalia-languages
收藏Hugging Face2026-04-15 更新2026-04-16 收录
下载链接:
https://huggingface.co/datasets/electricsheepafrica/africa-somalia-languages
下载链接
链接失效反馈官方服务:
资源简介:
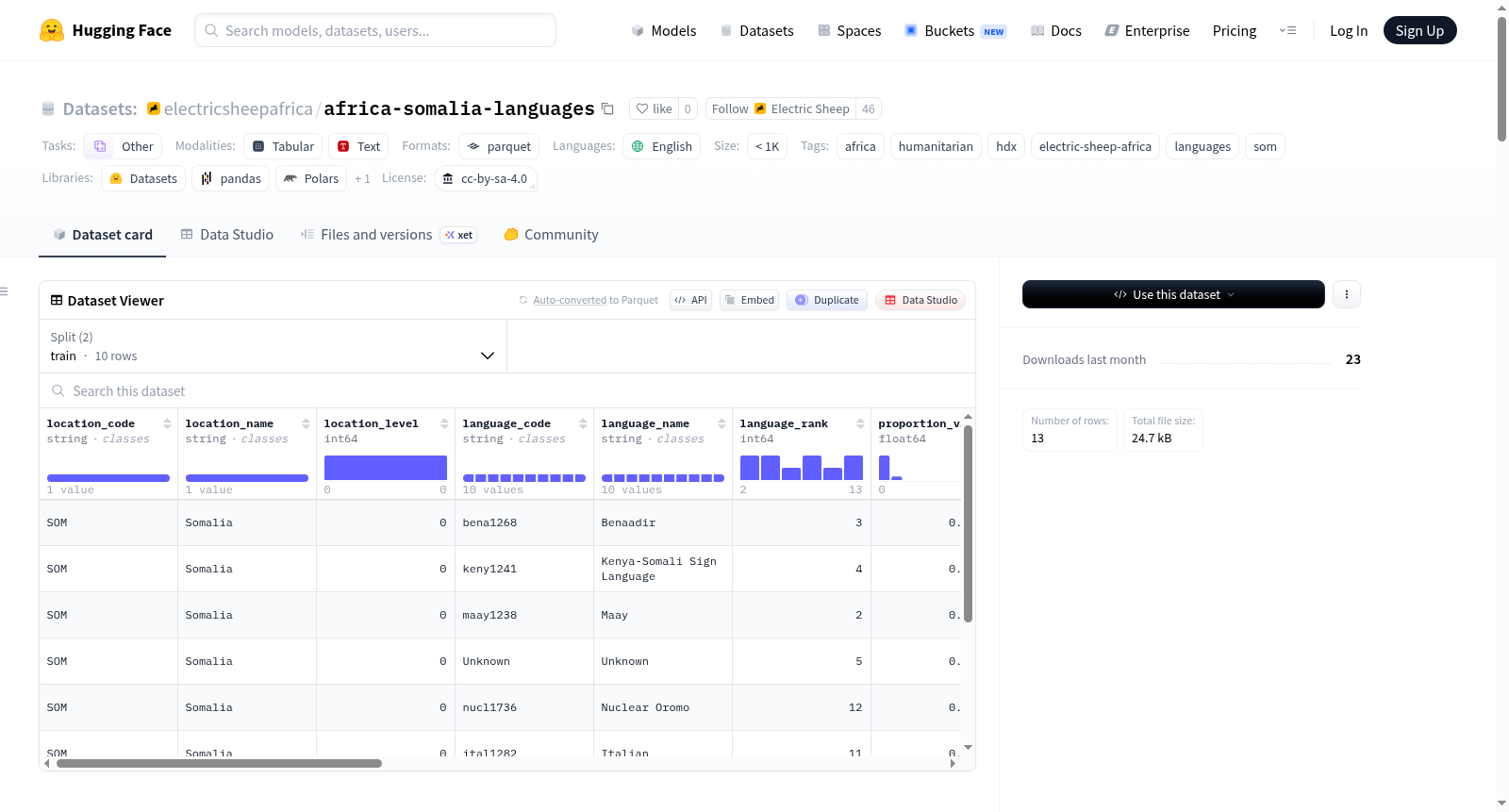
该数据集名为“索马里:语言”,由CLEAR Global(原Translators without Borders)发布,数据来源于HDX平台。数据集记录了索马里家庭主要使用语言的人口比例信息,数据来源于表格形式。数据集包含时间序列观测,涵盖地理、时间、人口统计和测量结果等多个维度。数据集规模较小,共13行数据,分为10行训练集和2行测试集。包含16个字段(4个数值型、10个类别型、2个日期时间型)。地理范围限定为索马里(SOM)。数据集经过Electric Sheep Africa整理为适合机器学习的Parquet格式。数据可用于人口统计和人道主义背景下的语言使用研究。
创建时间:
2026-04-08
原始信息汇总
数据集概述:Somalia: Languages
基本信息
- 数据集名称:Somalia: Languages
- 发布者:CLEAR Global (previously Translators without Borders)
- 数据来源:HDX (https://data.humdata.org/dataset/somalia-languages)
- 许可证:cc-by-sa-4.0
- 语言:英语 (en)
- 多语言性:单语种
- 数据规模:n<1K
- 任务类别:其他
- 标签:africa, humanitarian, hdx, electric-sheep-africa, languages, som
- 最后更新日期:2026-04-08
数据集内容
- 领域:人口统计学
- 观察单位:时间序列观测值
- 总行数:13
- 总列数:16 (4个数值型,10个分类型,2个日期时间型)
- 数据分割:
- 训练集:10行
- 测试集:2行
- 地理范围:索马里 (SOM)
- 数据描述:该数据集包含索马里家庭主要使用语言的人口比例数据。数据来源于表格。
变量说明
- 地理变量:
location_code,location_name,location_level,reliability_score,representivity_rating - 时间变量:
datetime_published,date_creation - 人口统计变量:
language_code,language_name,language_rank - 结果/测量变量:
proportion_value - 标识符/元数据:
dataset_name,source,esa_source,esa_processed - 其他:
url
数据模式与统计摘要
- 关键列示例:
language_code:stan1293, Unknown, maay1238language_name:English, Unknown, Maaydataset_name:SOMALIA JOINT MULTI-CLUSTER NEEDS ASSESSMENT (JMCNA) November 2021
- 数值范围:
language_rank:1.0 – 13.0proportion_value:0.0 – 0.5844reliability_score:0.8165 – 0.8165
数据预处理
- 原始数据获取:通过CKAN API从HDX下载。
- 格式转换:转换为Parquet格式。
- 列名标准化:转换为小写蛇形命名。
- 缺失值处理:统一标记为
NaN。 - 类型转换:基于解析成功率(>85%)将2列从字符串转换为数值或日期时间类型。
- 数据分割:使用固定随机种子(42)按80/20比例分割为训练集和测试集,并保存为Snappy压缩的Parquet文件。
使用方式
python from datasets import load_dataset ds = load_dataset("electricsheepafrica/africa-somalia-languages")
局限性
- 数据来源于CLEAR Global,未经ESA独立验证。
- 自动清洗无法纠正原始数据中的误报值、定义不一致或抽样偏差。
- 详细的方法说明和注意事项请参考原始HDX数据集页面。
引用
bibtex @dataset{hdx_africa_somalia_languages, title = {Somalia: Languages}, author = {CLEAR Global (previously Translators without Borders)}, year = {2026}, url = {https://data.humdata.org/dataset/somalia-languages}, note = {Repackaged for machine learning by Electric Sheep Africa (https://huggingface.co/electricsheepafrica)} }
搜集汇总
数据集介绍
构建方式
在人口统计学与人道主义研究领域,数据集的构建往往依赖于权威机构的原始调查。本数据集源自CLEAR Global(前身为Translators without Borders)通过人道主义数据交换平台(HDX)发布的索马里家庭主要语言使用比例数据。原始数据采集自2021年11月进行的索马里联合多集群需求评估(JMCNA)调查表格,随后由Electric Sheep Africa团队通过CKAN API获取并进行了系统化处理。数据清洗过程统一了缺失值标记,将列名标准化为蛇形命名法,并依据解析成功率将部分字段转换为数值或日期时间类型。最终,数据集被按照80:20的比例划分为训练集与测试集,并以Snappy压缩的Parquet格式存储,确保了数据的机器学习可用性。
使用方法
在应用层面,该数据集为语言分布分析与人道主义资源配置研究提供了结构化基础。研究者可通过Hugging Face的datasets库直接加载数据集,利用Python环境便捷地转换为Pandas DataFrame进行探索。典型工作流程始于调用load_dataset函数获取训练集与测试集,继而可对语言比例、排名等数值变量进行描述性统计或可视化,以揭示索马里语言使用的空间与时间模式。鉴于其小规模特性,数据集尤其适合作为微观实证研究的基准数据,或用于验证人口统计模型在低资源环境下的适用性。使用时应参考原始HDX页面中的方法论说明,并注意数据源自第三方机构,需结合具体研究问题审慎解读其内在局限性。
背景与挑战
背景概述
在人口统计学与人道主义援助领域,语言数据的收集与分析对于理解社区构成、优化服务交付至关重要。Somalia: Languages数据集由CLEAR Global(前身为Translators without Borders)于2026年发布,并由Electric Sheep Africa团队进行机器学习友好化处理。该数据集源自索马里联合多集群需求评估项目,核心研究问题聚焦于索马里家庭主要语言使用的人口比例分布,旨在为语言地图绘制和人道主义背景下的语言资源分配提供量化依据。其发布深化了对索马里语言生态的认知,为跨语言沟通策略的制定奠定了数据基础。
当前挑战
该数据集致力于解决人口语言构成量化分析中的挑战,具体包括如何准确捕捉多语言社区中语言使用的动态变化,以及如何将小规模调查数据有效外推至全国范围。在构建过程中,挑战主要源于数据源的局限性:原始数据依赖于表单收集,可能存在报告偏差或定义不一致问题;自动化清洗流程虽统一了缺失值标记,但难以修正原始采样偏差或方法论差异。此外,数据集规模较小(仅13行观测值),限制了统计推断的稳健性,且未经过独立验证,需谨慎依赖其结论。
常用场景
经典使用场景
在人口统计学与语言资源管理领域,该数据集提供了索马里家庭主要语言使用比例的时序观测数据。其经典应用场景在于支持多语言社会语言分布的量化分析,通过语言代码、比例值等变量,研究者能够追踪不同语言群体在人口中的动态变化,为语言政策制定提供实证基础。数据集的小规模特性使其适用于探索性数据分析或作为更大规模研究的补充材料,尤其在资源受限的人道主义语境下,这类精细化的语言数据显得尤为珍贵。
解决学术问题
该数据集主要解决了语言多样性测量与语言接触研究中的实证数据缺失问题。通过提供索马里地区英语、马亚语等语言的使用比例与排名,它使得学者能够分析语言活力、语言转用趋势以及多语言社区的语言生态结构。其高代表性评分与可靠性指标增强了数据的学术可信度,为跨学科研究如社会语言学、计算社会科学提供了标准化、可复现的数据基础,有助于深化对冲突地区语言动态的理解。
实际应用
在实际应用中,该数据集被用于支持人道主义行动与公共服务规划。例如,在索马里的人道主义评估中,语言数据可指导翻译服务分配、多语言信息传播策略的设计,确保援助资源能够有效覆盖不同语言群体。此外,政府部门或非营利组织可依据语言比例数据优化教育、医疗等公共服务的语言可及性,促进社会包容性发展,体现了数据驱动决策在复杂社会环境中的实践价值。
数据集最近研究
最新研究方向
在人口统计与语言资源管理领域,索马里语言数据集为研究语言多样性在冲突后社会环境中的分布与演变提供了关键数据支撑。当前前沿研究聚焦于利用此类小规模时间序列数据,结合机器学习方法预测语言使用模式的动态变化,以支持人道主义响应中的多语言服务规划。热点事件如索马里持续的人道主义危机,促使学术界与援助机构关注语言数据在提升信息可达性与社区参与度方面的作用,该数据集通过量化家庭主要语言比例,为设计包容性沟通策略和评估语言障碍对援助交付的影响提供了实证基础,推动了数据驱动的人道行动决策。
以上内容由遇见数据集搜集并总结生成


