SimpleQA-Bench
收藏Hugging Face2024-12-17 更新2024-12-18 收录
下载链接:
https://huggingface.co/datasets/alibaba-pai/SimpleQA-Bench
下载链接
链接失效反馈官方服务:
资源简介:
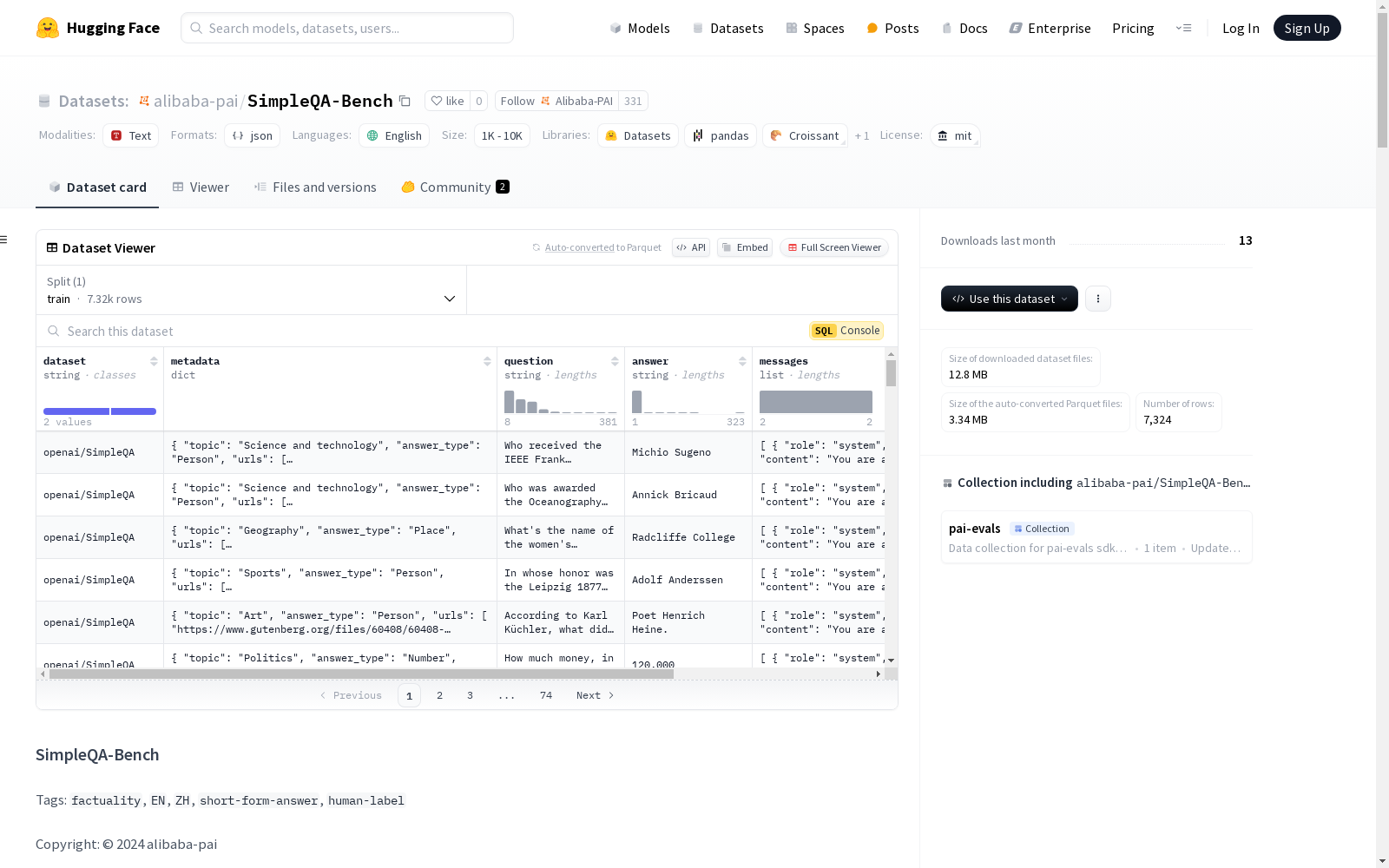
SimpleQA-Bench是一个结合了SimpleQA和Chinese-SimpleQA数据集的多选题(MCQ)格式数据集。原始数据集包含大量长尾和细分领域的知识,直接回答的准确率较低。为了提高事实性评估的可行性,使用GPT-4o生成三个看似合理但不正确的选项,将原始的问答数据转换为多选题格式。总共转换了7,324个样本。数据集的字段包括数据集名称、元数据、问题、答案、消息、选项和正确选项ID。
SimpleQA-Bench is a multiple-choice question (MCQ) format dataset that integrates the SimpleQA and Chinese-SimpleQA datasets. The original dataset contains a large volume of knowledge from long-tail and niche domains, with low direct answering accuracy. To enhance the feasibility of factual evaluation, GPT-4o was employed to generate three plausible but incorrect distractors, transforming the original question-answer pairs into MCQ format. A total of 7,324 samples were converted. The fields of this dataset include dataset name, metadata, question, answer, message, options, and correct option ID.
创建时间:
2024-12-06
原始信息汇总
SimpleQA-Bench
基本信息
- 语言: 英语 (en)
- 许可证: MIT
- 标签:
factuality,EN,ZH,short-form-answer,human-label - 版权: © 2024 alibaba-pai
数据来源
- SimpleQA: Blog & Paper / Data & simple-evals Project
- Chinese-SimpleQA: Blog & Paper, Data@HF
数据集描述
- 数据格式: 多选题 (MCQ) 格式
- 数据处理: 将 SimpleQA 和 Chinese-SimpleQA 数据集合并,并转换为多选题格式。通过 GPT-4o 生成 3 个合理的错误选项,将原始 QA 数据转换为 MCQ 格式。
- 样本数量: 4,326 (SimpleQA) + 2,998 (Chinese-SimpleQA) = 7,324 样本
数据字段
| 字段 | 描述 | SimpleQA 示例 | Chinese-SimpleQA 示例 |
|---|---|---|---|
dataset (str) |
数据集名称 | openai/SimpleQA | OpenStellarTeam/Chinese-SimpleQA |
metadata (str) |
数据元信息,包括主题、来源 URL 等 | {"topic": "Science and technology", "answer_type": "Person", "urls": ["https://en.wikipedia.org/wiki/IEEE_Frank_Rosenblatt_Award", "https://ieeexplore.ieee.org/author/37271220500", "https://en.wikipedia.org/wiki/IEEE_Frank_Rosenblatt_Award", "https://www.nxtbook.com/nxtbooks/ieee/awards_2010/index.php?startid=21#/p/20"]} | {"id": "6fd2645ad3994c89a01acae98cf04f90", "primary_category": "自然与自然科学", "secondary_category": "资讯科学", "urls": ["https://zh.wikipedia.org/wiki/%E8%92%99%E7%89%B9%E5%8D%A1%E6%B4%9B%E6%A0%91%E6%90%9C%E7%B4%A2"]} |
question (str) |
问题 | Who received the IEEE Frank Rosenblatt Award in 2010? | 蒙特卡洛树搜索最初由哪位研究人员在1987年的博士论文中探索,并首次提出了其关键特性? |
answer (str) |
人工验证的简短答案 | Michio Sugeno | 布鲁斯·艾布拉姆森(Bruce Abramson) |
messages (List[Dict]) |
用于回答 MCQ 的 openai 标准消息 | [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "# Objective ... Answers: "}] | 相同 |
options (List[str]) |
所有选项,带 ID A/B/C/D | ["Lotfi Zadeh", "Michio Sugeno", "John McCarthy", "Stephen Grossberg"] | ["布鲁斯·艾布拉姆森(Bruce Abramson)", "勒努瓦·波维尔(Lennart Batsch-Fischer)", "克里斯·沃特森(Chris Watkins)", "马丁·汉森(Martin Hansen)"] |
answer_option (str) |
正确选项 ID:A/B/C/D | B | A |
提示词
- GEN_WA_RROMPT: 用于生成多选题的提示词,要求生成三个合理的错误答案。
- ANSWER_MCQ_PROMPT: 用于回答多选题的提示词,要求直接选择正确选项。
性能比较
| LLM | SimpleQA (4326) | SimpleQA-MCQ | Chinese-SimpleQA (2998) | Chinese-SimpleQA-MCQ |
|---|---|---|---|---|
| gpt-4o-mini-2024-07-18 | 9.5 | 41.2 (1781/4326) | 37.6 | 52.9 (1586/2997) |
| qwen-max | / | 52.5 (2256/4300) | 54.1 | 72.7 (2177/2996) |
搜集汇总
数据集介绍
构建方式
SimpleQA-Bench数据集的构建基于两个原始数据集:OpenAI的SimpleQA和OpenStellarTeam的中文SimpleQA。这两个数据集包含了大量长尾和专业知识领域的问题与答案。为了提高语言模型在事实性评估中的表现,研究团队将这两个数据集整合,并通过GPT-4o生成三个看似合理但错误的候选答案,将原始的问答数据转换为多选题(MCQ)格式。最终,数据集包含了7,324个样本,每个样本包含一个问题、一个正确答案和三个错误选项。
特点
SimpleQA-Bench数据集的主要特点在于其多选题格式,这种格式不仅简化了事实性评估的复杂性,还增强了模型区分正确与错误答案的能力。数据集涵盖了广泛的知识领域,包括科学、技术、自然科学等,且每个问题都附有详细的元数据,如主题和来源URL,便于进一步分析和验证。此外,数据集的构建过程中使用了GPT-4o生成的错误选项,确保了选项的合理性和多样性。
使用方法
SimpleQA-Bench数据集适用于评估语言模型在事实性任务中的表现,尤其是在多选题格式下的准确性。用户可以通过提供的提示模板(如GEN_WA_RROMPT和ANSWER_MCQ_PROMPT)来生成和回答多选题。数据集的结构清晰,包含问题、正确答案、错误选项以及相关的元数据,便于模型训练和评估。此外,数据集还提供了性能比较的基准,帮助用户了解不同语言模型在该数据集上的表现。
背景与挑战
背景概述
SimpleQA-Bench数据集由阿里巴巴PAI团队于2024年创建,旨在解决大规模语言模型在事实性问题上的准确性评估难题。该数据集结合了OpenAI的SimpleQA和OpenStellarTeam的中文SimpleQA数据,经过处理转化为多选题(MCQ)格式,以提高事实性评估的可操作性。其核心研究问题聚焦于如何有效评估语言模型在短小、事实性查询中的表现,尤其是在区分候选答案正确性方面的能力。该数据集的推出对自然语言处理领域具有重要意义,为事实性评估提供了新的基准。
当前挑战
SimpleQA-Bench数据集在构建过程中面临多项挑战。首先,原始数据涉及大量长尾和冷门知识,导致直接问答的准确率较低。其次,将问答数据转化为多选题格式需要生成三个看似合理但错误的选项,这对生成模型的语义理解和创造力提出了高要求。此外,评估语言模型在多选题中的表现时,还需考虑模型对候选答案正确性的辨别能力,而非仅提供正确答案。这些挑战使得SimpleQA-Bench在事实性评估领域具有独特的研究价值。
常用场景
经典使用场景
SimpleQA-Bench数据集的经典使用场景主要集中在自然语言处理领域,特别是针对事实性问答任务的评估。该数据集通过将原始的问答数据转换为多选题(MCQ)格式,使得评估语言模型在处理短小、事实性查询时的准确性和事实性变得更加可行。这种格式不仅简化了评估过程,还提高了模型在区分正确与错误答案时的能力,从而为研究人员提供了一个更为精确的基准。
实际应用
在实际应用中,SimpleQA-Bench数据集可广泛用于构建和评估智能问答系统,特别是在需要高事实性保证的场景中,如教育、医疗和法律咨询等领域。通过该数据集的训练和评估,开发者可以构建出更为准确和可靠的问答模型,从而提升用户体验和服务质量。此外,该数据集还可用于语言模型的持续改进和优化,确保其在处理复杂查询时的稳定性和准确性。
衍生相关工作
SimpleQA-Bench数据集的推出激发了大量相关研究工作,特别是在事实性问答和多选题生成领域。研究者们基于该数据集开发了多种改进模型,旨在提高语言模型在处理事实性查询时的准确性和鲁棒性。此外,该数据集还促进了跨语言问答系统的研究,特别是在中英文问答系统的对比和优化方面,推动了多语言问答技术的发展。
以上内容由遇见数据集搜集并总结生成


