aisc-team-b1/PMC-CaseReport
收藏Hugging Face2024-03-12 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/aisc-team-b1/PMC-CaseReport
下载链接
链接失效反馈官方服务:
资源简介:
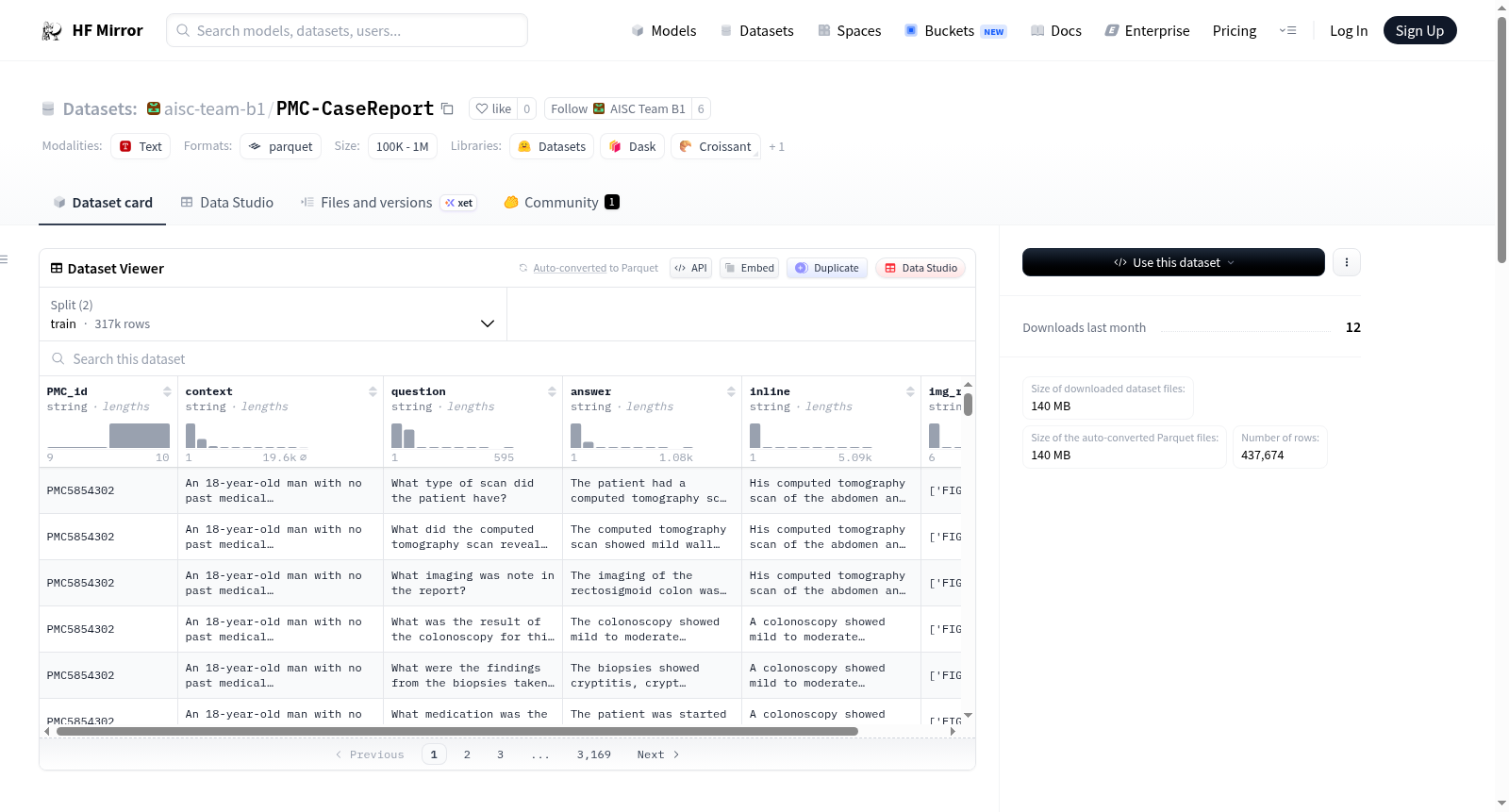
PMC-CaseReport数据集是一个用于视觉问答(VQA)任务的医学案例报告数据集,包含训练集和测试集,分别有316,838和120,836个样本。每个样本包含PMC_id、context、question、answer、inline和img_ref等特征。数据集中的文本部分和图像部分可以分别下载,图像部分以PMCxxxxxxx_figid.jpg的格式命名。数据集中的context字段包含案例报告中的上下文信息,question字段是生成的问题,answer字段是正确答案,img_ref字段是与图像相关的ID列表。需要注意的是,部分案例中的答案可能会在context中泄露,且由于数据收集时间窗口的原因,部分图像可能缺失。
The PMC-CaseReport dataset is a medical case report dataset designed for visual question answering (VQA) tasks. It comprises a training set and a test set, containing 316,838 and 120,836 samples respectively. Each sample includes features such as PMC_id, context, question, answer, inline, and img_ref. The textual and image components of the dataset can be downloaded separately, with image files named in the format PMCxxxxxxx_figid.jpg. Specifically, the context field holds the contextual information from the case report, the question field contains a generated question, the answer field holds the correct answer, and the img_ref field is a list of IDs associated with relevant images. It is worth noting that the answers to some cases may be inadvertently leaked in the context, and some images may be missing due to the data collection time window.
提供机构:
aisc-team-b1
原始信息汇总
PMC-CaseReport Dataset 概述
数据集结构
-
特征字段:
- PMC_id: 字符串类型,对应的PMC论文ID。
- context: 字符串类型,病例报告讨论图像前的上下文。
- question: 字符串类型,生成的问题。
- answer: 字符串类型,正确答案。
- inline: 字符串类型,原文中的内联句子,不应输入网络。
- img_ref: 字符串类型,相关图像ID的列表。
-
数据集划分:
- 训练集:316838个样本,占用634222398字节。
- 测试集:120836个样本,占用253538916字节。
-
数据集大小:总下载大小为139781550字节,总数据集大小为887761314字节。
样本示例
| PMC_id | PMC9052276 |
|---|---|
| context | We report the case of a 73-year-old female who presented to the ER with left-sided body weakness of unclear duration.She had an ischemic stroke four years prior with no residual neurologic deficits, a myocardial infarction requiring coronary artery bypass grafting (CABG) two years prior, hypertension, and dementia. Her vital signs were blood pressure (BP) 117/78 mmHg, pulse 121 beats per minute, temperature 98.9 F, respiratory rate (RR) 18 cycles/minute, and oxygen saturation (SpO2) of 97% on ambient air.She was disoriented to place and time with a Glasgow Coma Score (GCS) of 14 (E4V4M6).Her speech was slurred, cranial nerves (CN) 2-12 were grossly intact, motor strength on the left upper and lower extremities was 0/5 and on the right upper and lower extremities was 4/5, and the sensation was preserved in all extremities.The patient had a National Institutes of Health Stroke Scale (NIHSS) score of 16 and a Modified Rankin Score (mRS) of 5 points.A non-contrast head CT scan revealed evidence of old lacuna infarcts in the basal ganglia and thalamus.No intracranial hemorrhage or acute infarct was found.CT perfusion was not done as our center lacks the resources needed to perform that. |
| inline | A brain MRI scan showed an acute pontine stroke (Figures and old infarcts |
| question | What did the brain MRI scan reveal? |
| answer | The brain MRI scan showed an acute pontine stroke and old infarcts. |
| img_ref | "[FIG1, FIG3, FIG4]" |
注意事项
- 上下文未严格过滤,少数情况下答案可能泄露在上下文中。
- 由于论文更新,部分图像可能不在图像库中。
搜集汇总
数据集介绍
构建方式
在医学文献挖掘领域,PMC-CaseReport数据集的构建体现了对临床病例报告资源的系统性整合。该数据集源自PubMed Central(PMC)开放获取文献库,通过自动化流程从病例报告中提取文本与图像信息。构建过程中,研究团队首先筛选出包含丰富视觉材料的病例报告文献,随后利用自然语言处理技术,从文本上下文中生成与图像内容相关的问题与答案对。数据清洗环节移除了部分存在信息泄露的样本,并统一了图像命名规范,最终形成了包含训练集与测试集的标准化视觉问答数据集。
使用方法
在医学人工智能研究实践中,PMC-CaseReport数据集为训练和评估视觉问答模型提供了标准化的基准。使用者可通过Hugging Face的`datasets`库直接加载数据,按照训练集与测试集的划分进行模型开发。典型应用流程包括:利用`context`、`question`字段及对应的图像文件作为模型输入,以`answer`字段作为监督信号进行训练。需要注意的是,关联的图像文件需从指定资源库另行下载,并依据`img_ref`字段提供的标识符进行匹配。研究人员应留意数据说明中提及的少量上下文信息泄露及图像可能缺失的情况,并在实验设计时予以考虑。
背景与挑战
背景概述
PMC-CaseReport数据集由哈佛医学院AISC课程团队于近年构建,旨在推进医学视觉问答领域的研究。该数据集源自PubMed Central的病例报告文献,通过提取文本与图像关联信息,构建了超过43万对视觉问答样本。其核心研究问题聚焦于如何让机器学习模型理解复杂的医学影像与临床文本之间的深层语义关联,从而辅助医疗诊断与教育。该数据集的发布为医学人工智能领域提供了宝贵的多模态资源,显著促进了临床决策支持系统的发展,并在医学图像理解与自然语言处理的交叉研究中产生了广泛影响力。
当前挑战
该数据集致力于解决医学视觉问答中的核心挑战,即模型需同时解析临床文本的细微语义并准确关联医学影像的视觉特征,这对模型的跨模态理解能力提出了极高要求。在构建过程中,研究人员面临数据对齐的复杂性,病例报告中的文本与图像引用往往存在模糊或间接关联,需精确匹配。此外,数据质量控制亦为难点,部分上下文可能泄露答案,且因文献更新导致图像缺失,影响了数据集的完整性与一致性。这些挑战共同凸显了医学多模态数据整合的固有难度。
常用场景
经典使用场景
在医学人工智能领域,PMC-CaseReport数据集以其丰富的病例报告视觉问答对,为多模态医学理解任务提供了关键资源。该数据集经典地应用于训练和评估视觉语言模型,特别是针对医学图像与文本的联合推理能力。模型通过结合上下文描述、医学图像及对应问题,学习从复杂临床场景中提取精准答案,从而模拟医生诊断时的信息整合过程。这种应用不仅提升了模型在医学视觉问答任务上的性能,还为自动化辅助诊断系统的开发奠定了数据基础。
解决学术问题
该数据集有效解决了医学人工智能研究中多模态信息融合的挑战,尤其是针对病例报告中图像与文本关联性理解不足的问题。通过提供大规模、结构化的视觉问答对,它支持研究者探索如何从医学文献中自动提取临床知识,并建立图像与诊断描述之间的语义联系。这促进了跨模态表示学习、医学视觉问答以及临床决策支持等方向的发展,显著推动了医学自然语言处理与计算机视觉的交叉研究。
实际应用
在实际医疗场景中,PMC-CaseReport数据集可赋能智能临床辅助系统,帮助医生快速检索和分析类似病例。例如,系统能够根据输入的医学图像自动生成相关诊断问题,或基于历史病例提供参考解答,从而缩短诊断时间并减少人为误差。此外,该数据集还可用于医学教育工具的开发,通过模拟真实病例的视觉问答,辅助医学生和住院医师提升影像解读与临床推理能力。
数据集最近研究
最新研究方向
在医学人工智能领域,PMC-CaseReport数据集以其丰富的病例报告视觉问答对,正推动多模态医学理解的前沿探索。当前研究聚焦于结合文本与医学影像的跨模态推理,旨在提升模型对复杂临床情境的解析能力,例如急性卒中诊断的自动化辅助。热点事件如生成式人工智能在医疗决策中的集成,进一步凸显了该数据集在训练可解释、高精度医学问答系统方面的关键价值。其影响深远,不仅加速了临床知识提取的技术革新,也为个性化医疗与远程诊断提供了可靠的数据基石,促进了医学人工智能向更安全、更可信的方向演进。
以上内容由遇见数据集搜集并总结生成


