benchang1110/WildChat-Chinese
收藏Hugging Face2024-05-11 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/benchang1110/WildChat-Chinese
下载链接
链接失效反馈官方服务:
资源简介:
WildChat是一个包含100万条人类用户与ChatGPT对话的数据集,涵盖了多种语言,特别是中文。数据集还包括用户的地理位置信息、IP地址哈希值、请求头等。数据集可用于指令微调和用户行为研究。数据经过去标识化处理,确保用户隐私。数据集包含有毒和无毒的用户输入和ChatGPT响应。
WildChat是一个包含100万条人类用户与ChatGPT对话的数据集,涵盖了多种语言,特别是中文。数据集还包括用户的地理位置信息、IP地址哈希值、请求头等。数据集可用于指令微调和用户行为研究。数据经过去标识化处理,确保用户隐私。数据集包含有毒和无毒的用户输入和ChatGPT响应。
提供机构:
benchang1110
原始信息汇总
数据集概述
名称: WildChat
描述: WildChat是一个包含100万次人类用户与ChatGPT对话的数据集,涵盖了多种用户-聊天机器人交互,如模糊用户请求、代码切换、话题切换、政治讨论等。该数据集可用于指令微调和用户行为研究。本版本中,25.53%的对话来自GPT-4聊天机器人,其余来自GPT-3.5聊天机器人。
语言: 中文
数据处理: 数据已通过Microsoft Presidio和作者手写的规则进行去标识化处理。
数据字段
conversation_hash(字符串): 对话内容的哈希值。model(字符串): 底层OpenAI模型,如gpt-3.5-turbo或gpt-4。timestamp(时间戳): 对话中最后一轮交互的UTC时间戳。conversation(列表): 用户/助手发言的列表,每个发言包含说话者角色、发言内容、检测到的语言、内容是否被视为有毒以及是否检测到并匿名化个人识别信息。turn(整数): 对话中的轮数。language(字符串): 对话中最频繁检测到的语言。openai_moderation(列表): OpenAI Moderation结果列表。detoxify_moderation(列表): Detoxify结果列表。toxic(布尔值): 对话是否包含任何被视为有毒的发言。redacted(布尔值): 对话是否包含任何检测到并匿名化的个人识别信息。state(字符串): 从对话中最常见的IP地址推断出的州。country(字符串): 从对话中最常见的IP地址推断出的国家。hashed_ip(字符串): 对话中最常见的哈希IP地址。header(字符串): 请求头,包含操作系统、浏览器版本和接受语言的信息。
许可证
许可证: AI2 ImpACT License - Low Risk Artifacts ("LR Agreement")
引用信息
@inproceedings{ zhao2024wildchat, title={WildChat: 1M Chat{GPT} Interaction Logs in the Wild}, author={Wenting Zhao and Xiang Ren and Jack Hessel and Claire Cardie and Yejin Choi and Yuntian Deng}, booktitle={The Twelfth International Conference on Learning Representations}, year={2024}, url={https://openreview.net/forum?id=Bl8u7ZRlbM} }
搜集汇总
数据集介绍
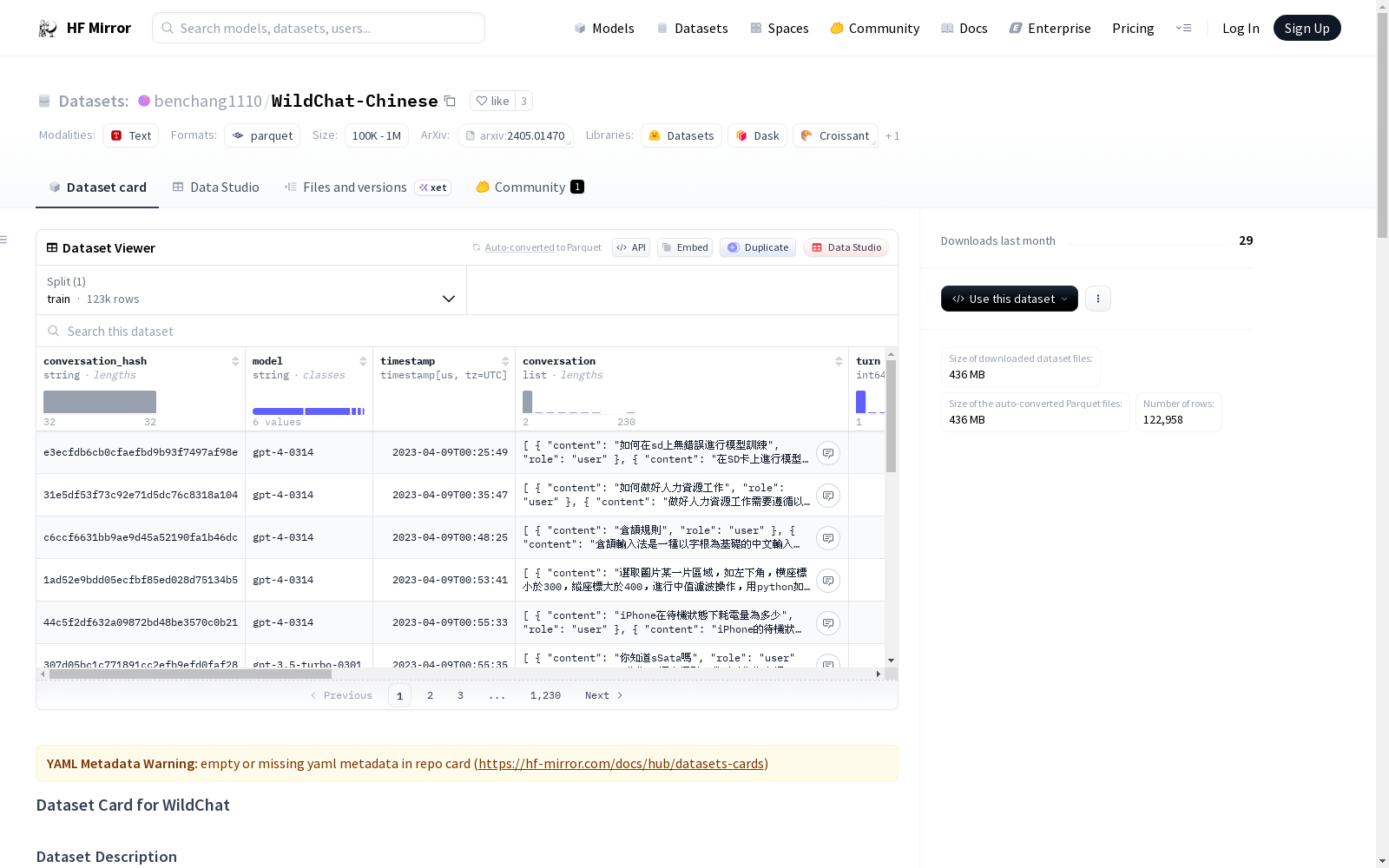
构建方式
在自然语言处理领域,大规模对话数据集的构建对于模型训练与用户行为研究至关重要。WildChat-Chinese数据集的构建依托于开放获取策略,通过向在线用户免费提供OpenAI的GPT-3.5与GPT-4模型访问权限,系统性地收集了用户与ChatGPT之间的真实交互对话。数据采集过程中,涵盖了多轮对话、跨语言切换及多样化话题,同时运用Microsoft Presidio工具与人工规则对个人敏感信息进行去标识化处理,确保数据隐私安全。该数据集特别筛选了中文对话内容,并利用Opencc进行转换,最终形成包含百万级对话的语料库,其中GPT-4生成内容占比约25.53%,为研究提供了丰富的语言交互样本。
特点
WildChat-Chinese数据集展现出多维度特征,其核心在于捕捉了真实场景下用户与大型语言模型之间的复杂互动模式。数据集不仅覆盖常规指令微调任务,还囊括了模糊用户请求、代码转换、话题跳跃及政治讨论等以往数据集中较少涉及的内容类型。每条数据记录均包含对话哈希值、模型类型、时间戳、多轮对话内容及语言检测结果,并辅以地理信息与请求头部数据,支持用户行为关联分析。此外,数据集通过OpenAI Moderation与Detoxify工具标注了毒性内容与个人身份信息匿名化状态,为研究对话安全性与伦理问题提供了结构化标注。
使用方法
该数据集在应用层面兼具实用性与研究价值,主要服务于指令微调与用户行为分析两大方向。研究人员可依据对话内容与元数据字段,如模型类型、毒性标签及地理信息,构建定制化的训练或评估任务。对于模型开发,可利用多轮对话序列进行端到端的微调,以提升模型在中文语境下的响应质量与安全性;对于行为学研究,则可结合哈希IP地址与请求头部数据,分析用户交互模式与跨对话关联性。使用过程中需遵循AI2 ImpACT低风险许可协议,严禁用于有害目的,并建议引用相关论文以保障学术规范性。
背景与挑战
背景概述
随着大型语言模型在自然语言处理领域的广泛应用,对高质量、多样化对话数据的需求日益迫切。WildChat-Chinese数据集由Allen AI研究所的Wenting Zhao、Yuntian Deng等研究人员于2024年创建,旨在收集真实世界中用户与ChatGPT的交互日志,以弥补现有指令微调数据在覆盖范围上的不足。该数据集聚焦于捕捉多语言环境下的复杂对话模式,如话题转换、代码切换及政治讨论等,为研究用户行为与模型优化提供了宝贵资源。其发布不仅推动了对话系统在真实场景下的适应性研究,也为跨文化语境下的语言理解奠定了数据基础。
当前挑战
WildChat-Chinese数据集致力于解决开放域对话系统中用户意图模糊性、多语言混合及内容安全性等核心挑战。在构建过程中,研究人员面临数据去标识化的技术难题,需通过Microsoft Presidio工具与人工规则结合,以平衡隐私保护与数据效用。此外,数据收集环节存在用户提交空输入导致的模型幻觉响应,这反映了真实交互中噪声控制的复杂性。数据集的多样性与规模虽提升了代表性,但也引入了内容毒性检测与地理信息推断的准确性考验,这些因素共同构成了该数据集在应用与研究中的关键挑战。
常用场景
经典使用场景
在自然语言处理领域,大规模对话数据集对于模型训练与评估至关重要。WildChat-Chinese作为真实用户与ChatGPT交互的中文对话集合,其经典使用场景在于为指令微调提供丰富语料。该数据集涵盖了多样化的用户请求,包括模糊指令、代码转换、话题切换及政治讨论等复杂情境,能够有效模拟现实世界中的对话复杂性,为模型适应真实交互环境奠定基础。
衍生相关工作
围绕WildChat-Chinese衍生的经典工作主要集中在对话安全性与多语言适应性研究。例如,基于该数据集开展的毒性内容检测算法优化、用户行为模式分析模型构建,以及跨语言指令微调方法的探索。这些工作不仅深化了对大型语言模型交互机制的理解,也为后续数据集如WildChat的多语言扩展提供了方法论基础。
数据集最近研究
最新研究方向
在自然语言处理领域,大规模对话数据集已成为推动模型优化与行为分析的关键资源。WildChat-Chinese作为多语言交互日志的子集,聚焦于中文语境下用户与ChatGPT的真实对话,其蕴含的模糊请求、语码转换及政治讨论等复杂场景,为指令微调与用户行为研究开辟了新路径。前沿探索集中于利用该数据集剖析大语言模型在跨文化沟通中的适应性,以及通过毒性内容与个人身份信息脱敏机制,评估模型的安全性与伦理边界。相关研究不仅助力于提升对话系统的鲁棒性,也为全球人工智能治理提供了实证基础,彰显了开放科学在促进技术透明化方面的重要意义。
以上内容由遇见数据集搜集并总结生成


