omniproact-bench-neurips26/omniproact-bench
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/omniproact-bench-neurips26/omniproact-bench
下载链接
链接失效反馈官方服务:
资源简介:
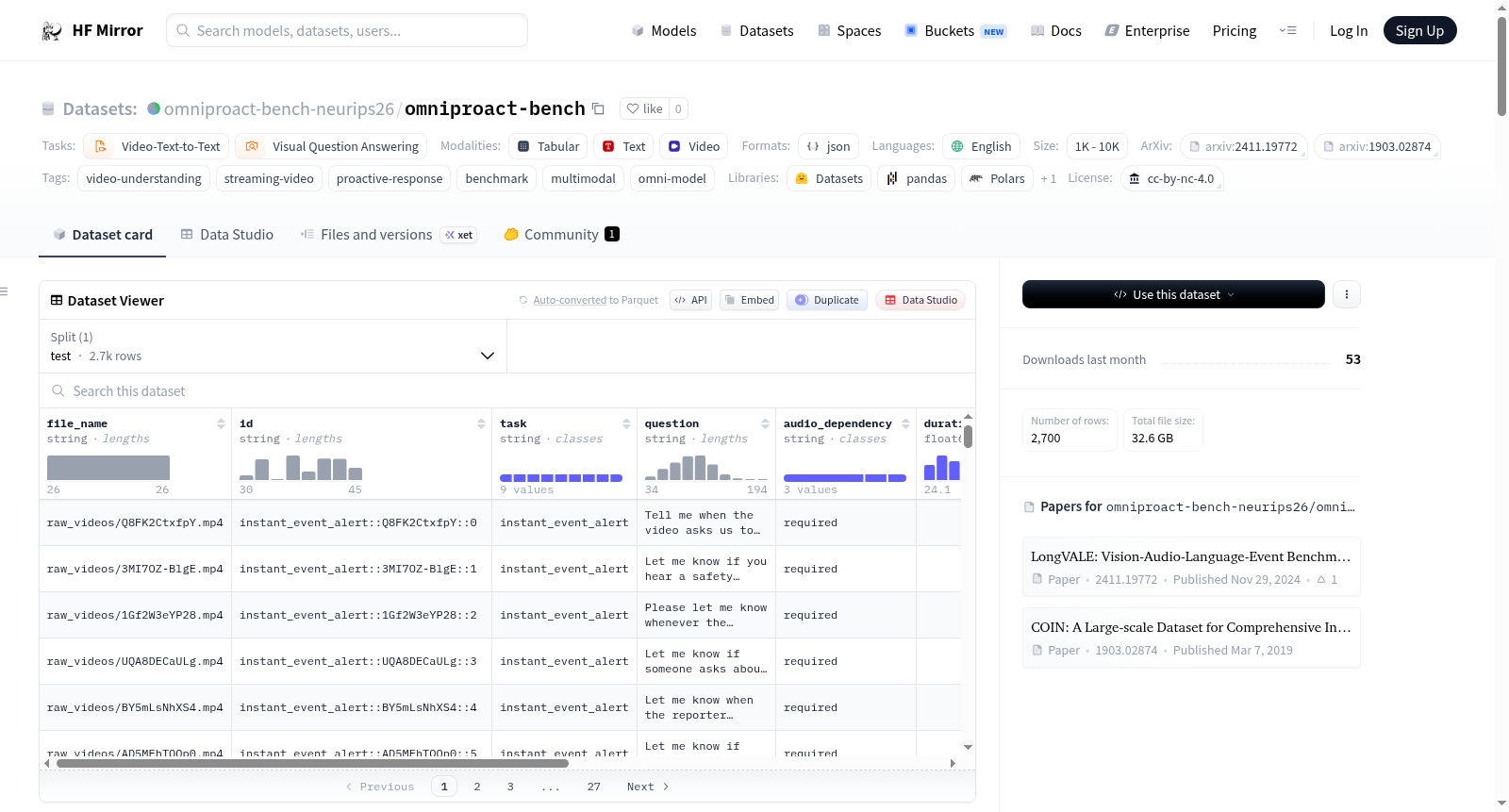
OmniProact-Bench是一个全面的基准测试,用于评估全能多模态大型语言模型(MLLMs)的主动视频理解能力。与传统的反应式问答基准不同,OmniProact-Bench评估模型是否能够在视频流中主动监控并在特定条件满足时在正确时刻做出响应。该基准围绕三个核心能力设计:1)多模态感知——理解视频中的视觉、语音和非语音声音信号;2)主动时机——在视频流中自主决定何时说话和何时保持沉默;3)全面的视频理解——涵盖六种基本能力:警报、监控、定位、计数、叙述和预测。数据集包含2,700个样本,涵盖9种任务类型,强调多模态触发器,特别是音频理解。
OmniProact-Bench is a comprehensive benchmark for evaluating proactive video understanding capabilities of omni multimodal large language models (MLLMs). Unlike traditional reactive QA benchmarks where models respond to explicit questions after watching a video, OmniProact-Bench evaluates whether models can proactively monitor video streams and respond at the right moment when specific conditions are met. The benchmark is designed around three core capabilities: 1) Multimodal Perception — understanding visual, speech, and non-speech sound signals in video; 2) Proactive Timing — autonomously deciding when to speak and when to remain silent in a video stream; 3) Comprehensive Video Understanding — covering six fundamental capabilities: alerting, monitoring, grounding, counting, narration, and prediction. The dataset includes 2,700 samples across 9 task types, with a focus on multimodal triggers, especially audio understanding.
提供机构:
omniproact-bench-neurips26
搜集汇总
数据集介绍
构建方式
OmniProact-Bench的构建基于公开研究数据集LongVALE与COIN中涵盖多样化真实场景与日常任务的教学视频。数据标注采用两阶段流程:首先利用Gemini 2.5 Flash模型结合视频完整内容(含音频)与任务特定提示,自动生成包含问题、触发时间戳、响应及模态标签的候选标注;随后由九名人类标注员按任务类型逐项审核,验证触发时间戳的准确性、响应质量及问题合理性,并对时序敏感任务进行二次模型校正与人工复核,最终生成高质量基准测试集。
特点
该基准测试的核心特色在于评估全模态大语言模型的主动视频理解能力,而非传统被动问答。数据集覆盖九种任务类型,横跨警报、监控、定位、计数、叙述与预测六项基础能力。百分之八十四的样本依赖或受益于音频理解,每个触发事件均标注了视觉、语音、声音及其组合的模态类型,支持模态隔离分析以揭示感知差距。平均每段189秒的视频包含3.4个触发点,展现了长视频流中主动响应时机的复杂性。
使用方法
数据集支持两种评估协议:探针模式下,评估器在每个真实触发点前后进行探测,以成对准确率为核心指标;在线模式下,模型需逐帧处理视频流并自主决定响应时机,采用时序F1分数与GPT评估的开放响应内容准确性作为评价标准。用户可通过加载benchmark.json文件获取完整的样本结构与元数据,并根据任务类型字段筛选对应子集进行针对性测试。评估代码将另行发布,确保结果可复现与比较。
背景与挑战
背景概述
在人工智能领域,多模态大语言模型的发展正从被动响应向主动感知迈进。为此,OmniProact-Bench于2026年由相关研究团队构建,旨在系统评估模型在流式视频中的主动理解能力。该基准涵盖2700个样本,涉及9类任务,强调多模态感知、主动时机判断与全面视频理解三大核心能力。通过整合视觉、语音与非语音声音信号,它推动了模型从传统问答向实时自主响应的范式转变,对多模态与主动智能领域具有重要影响。
当前挑战
该基准首先解决了视频理解中主动响应而非被动问答的领域难题,要求模型自主决策响应时刻。构建过程中,面临三重挑战:一是多模态触发事件的精确标注,需融合视觉、语音与声音信号;二是确保84%的样本依赖音频理解,以支持模态隔离分析;三是通过自动化生成与人工审核相结合的方式,在大规模多样化视频上保障时序对齐与响应质量的一致性。
常用场景
经典使用场景
OmniProact-Bench 作为一个专为评估多模态大语言模型(MLLMs)主动视频理解能力而设计的综合性基准,其经典使用场景是模拟智能体在持续的视频流中自主监测并实时响应的交互范式。与传统的反应式问答不同,该基准要求模型在观看视频时,无需显式提示,便能够自主判断何时应当做出回应,即不仅回答‘是什么’,更要感知‘何时回应’。评测覆盖了即时事件告警、语义条件触发、显式目标定位、快照与累积计数、实时状态监控、事件叙述及顺序步骤指令等九类任务,全面检验模型对多模态信号(视觉、语音、非语音声学事件)的融合感知能力以及时间敏感性的自主决策能力。
实际应用
在实际应用中,OmniProact-Bench的设计理念与场景高度契合当前以及未来人机共融环境中智能系统的关键需求。例如在智能监控与安防场景中,模型需实时识别异常事件(如特定动作或声音)并主动告警;在工业流程监控或智能家居环境中,系统可以自动感知设备状态的渐进变化或完成周期的阈值条件,并发出指令或通知。此外,在辅助导盲、实时赛事解说、以及面向老年人或认知障碍患者的智能陪护中,模型能够根据视频流中不断变化的情景,主动提供目标定位、计数更新或操作步骤指引。这些场景都要求系统具备超越被动提问的主动性、多元感知的集约性,以及时间精准响应的可靠性。OmniProact-Bench所建立的评测范式为上述应用提供了可量化、可复现的性能验证框架。
衍生相关工作
围绕OmniProact-Bench衍生的相关工作主要集中于主动性机制与多模态时序决策的算法创新与模型改进。该基准发布后,催生了对“何时说话与何时沉默”这一主动性旋钮(proactivity knob)的建模研究,推动了门控循环更新机制、时序注意力沙漏网络等新型架构的探索。此外,适配该基准的评测方式催生了若干针对在线式(帧级自主响应)与探针式(锚定真实标签)双模态评估协议的优化策略,如基于GPT判决的开放式回答质量自动评估框架。同时,研究人员也开始借此基准探究不同模态(视觉、语音、声音)组合下的感知衰减或增益效应,进而衍生出多模态预训练与对齐学习上的新范式,为最终构建端到端的、具备时空主动感知能力的全能模型奠定了基础。
以上内容由遇见数据集搜集并总结生成


