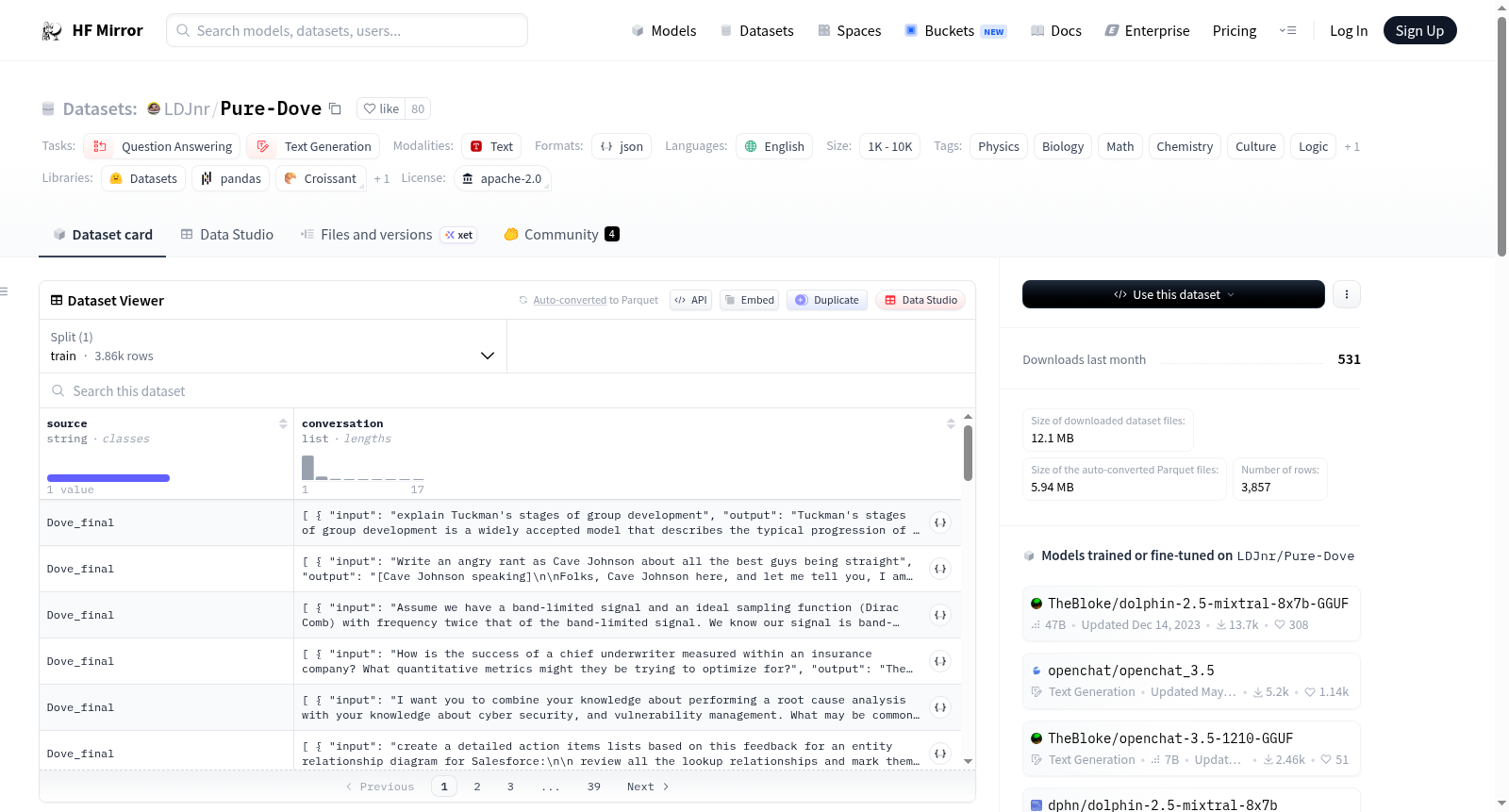
LDJnr/Pure-Dove
收藏Hugging Face2024-06-03 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/LDJnr/Pure-Dove
下载链接
链接失效反馈官方服务:
资源简介:
Pure-Dove数据集是一个包含超过3000个经过高度筛选的多轮对话的数据集,主要来源于GPT-4与真实人类的对话。该数据集的目的不是单独用于训练,而是作为多轮对话数据集的补充。数据集的清理过程包括去除AI道德化行为和异常语言分布。未来计划包括利用领域专家志愿者消除数学/可验证错误答案。
The Pure-Dove Dataset is a corpus containing over 3,000 highly filtered multi-turn conversations, primarily sourced from dialogues between GPT-4 and real human participants. This dataset is not intended for standalone training, but rather serves as a supplementary resource for multi-turn conversation datasets. The dataset cleaning workflow involves removing AI moralization behaviors and abnormal language distributions. Future plans include leveraging domain expert volunteers to rectify mathematical and verifiably incorrect responses.
提供机构:
LDJnr
原始信息汇总
数据集概述
基本信息
- 许可证: Apache-2.0
- 任务类别:
- 对话
- 问答
- 文本生成
- 语言: 英语
- 标签:
- 物理学
- 生物学
- 数学
- 化学
- 文化
- 逻辑
- 角色扮演
- 数据集名称: Pure-Dove
- 数据规模: 1K<n<10K
数据集描述
- 内容: 包含超过3000个经过高度筛选的多轮对话,涉及GPT-4与真实人类的交互。
- 平均对话长度: 每个对话平均超过800个令牌。
数据集目的
- 用途: 该数据集主要作为补充数据集,适用于任何支持多轮对话的数据集训练。
数据质量与清洗
- 来源: 数据来源于公开数据集如ShareGPT和ChatBotArena。
- 清洗过程: 进行了广泛的清洗,过滤掉了AI道德化或相关行为(如“作为AI语言模型”和“2021年9月”)的实例,不仅限于英语,还包括其他语言。
未来计划与贡献
- 未来计划: 计划利用领域专家志愿者来消除训练数据集中数学或可验证的错误答案。
- 如何贡献: 拥有数学、物理、生物或化学学士学位的人士,可以通过联系LDJ在Discord上贡献30分钟的专业时间。
搜集汇总
数据集介绍
构建方式
在构建Pure-Dove数据集的过程中,研究团队从公开数据源如ShareGPT和LMSYS的ChatBot Arena中采集了多轮对话样本。为确保数据质量,团队实施了严格的筛选机制,仅保留那些在比较中被明确评为优于其他GPT-4实例的对话,同时剔除了包含幻觉、多语言分布异常或AI道德化表述的样本。这一过程涉及对超过3000条对话的深度清洗,平均每轮对话的上下文长度超过800个标记,从而形成了高质量的多轮对话集群。
特点
Pure-Dove数据集以其高度的专业性和纯净性脱颖而出,涵盖了物理学、生物学、数学、化学、文化、逻辑推理及角色扮演等多个领域。该数据集的核心特点在于其经过精细过滤的对话内容,避免了常见的AI语言模型缺陷,如幻觉或道德化表述,确保了对话的自然性与真实性。此外,数据规模虽适中,但每个对话样本均具有较长的上下文,为多轮对话任务提供了丰富的语义环境。
使用方法
该数据集主要作为补充资源,用于增强其他多轮兼容数据集的训练效果。用户可通过HuggingFace平台直接访问数据集,将其整合到自然语言处理模型的训练流程中,以提升模型在复杂对话场景下的表现。在使用时,建议遵循Apache 2.0许可协议,并适当引用原始研究,以尊重数据贡献者的工作。未来,数据集计划引入领域专家进行进一步验证,以消除科学内容中的错误,增强其可靠性。
背景与挑战
背景概述
在大型语言模型(LLM)训练领域,高质量多轮对话数据的稀缺性一直是制约模型性能提升的关键瓶颈。为应对这一挑战,研究人员LDJnr与NousResearch团队于2023年共同构建了Pure-Dove数据集。该数据集旨在通过精心筛选来自ShareGPT和ChatBot Arena等开源平台的真实人机对话,构建一个规模超过3000条、平均上下文长度逾800词符的高质量多轮对话语料库。其核心研究问题聚焦于如何从海量对话中提取出逻辑连贯、知识准确且避免道德说教的纯净样本,以增强LLM在物理、生物、数学、化学等多学科领域的推理与对话能力。该数据集的发布为LLM的指令微调与对话生成研究提供了重要的补充资源,推动了开放领域对话系统向更精准、更可靠的方向演进。
当前挑战
Pure-Dove数据集致力于解决多轮对话生成中常见的语义连贯性不足与事实性错误频发的问题,其构建过程面临双重挑战。在领域问题层面,需确保对话内容在跨学科知识(如物理、化学)上的准确性,同时避免模型产生‘作为AI语言模型’等模式化回应或涉及过时信息(如‘2021年9月’)的幻觉现象。在构建过程中,研究者需从混杂多语言、质量参差的原始对话中过滤出优质样本,这一过程依赖复杂的人工与自动清洗流程,例如排除GPT-4响应中被评级为‘同等优劣’或‘双劣’的实例,仅保留明确优于对比样本的对话。此外,未来计划引入领域专家志愿者进行事实核查,以消除数学或科学类错误,这进一步凸显了高质量数据标注对专业知识与人力投入的高度依赖。
常用场景
经典使用场景
在自然语言处理领域,高质量的多轮对话数据对于提升大型语言模型的交互能力至关重要。Pure-Dove数据集以其超过3000条经过严格筛选的GPT-4与人类多轮对话实例,成为模型微调与评估的宝贵资源。该数据集平均每轮对话上下文长度超过800个词元,涵盖了物理学、生物学、数学、化学、文化与逻辑推理等多个学科主题,为研究者提供了丰富而真实的对话场景,特别适用于训练模型在复杂、连贯的对话中保持上下文一致性与知识准确性。
衍生相关工作
基于Pure-Dove数据集,研究者已开展多项经典工作,特别是在高效LLM训练与对话质量优化方面。例如,相关研究如《Amplify-Instruct》利用合成生成的多轮对话提升模型训练效率,而NousResearch等团队在数据过滤与质量增强方法上做出了贡献。这些工作借鉴了Pure-Dove的严格筛选机制,推动了多轮对话数据集的标准化建设,并为后续在跨学科对话生成、对抗性测试等领域的研究提供了重要参考。
数据集最近研究
最新研究方向
在人工智能对话系统领域,Pure-Dove数据集以其高质量的多轮对话样本,正成为推动大型语言模型精细化训练的关键资源。该数据集通过严格筛选GPT-4与人类交互的对话,剔除了幻觉内容及道德说教等异常模式,确保了数据的纯净性与逻辑连贯性。前沿研究聚焦于利用此类数据增强模型的推理能力与跨学科知识整合,尤其在物理、生物等科学领域,结合专家验证机制,旨在减少模型的事实性错误。这一方向不仅呼应了当前对可解释、可靠AI系统的迫切需求,也为多轮对话任务的性能提升提供了实证基础,促进了人机交互的自然化与专业化发展。
以上内容由遇见数据集搜集并总结生成


