Fictitious Facial Identity VQA Dataset
收藏arXiv2024-11-06 更新2024-11-08 收录
下载链接:
https://huggingface.co/datasets/gray311/FIUBench
下载链接
链接失效反馈官方服务:
资源简介:
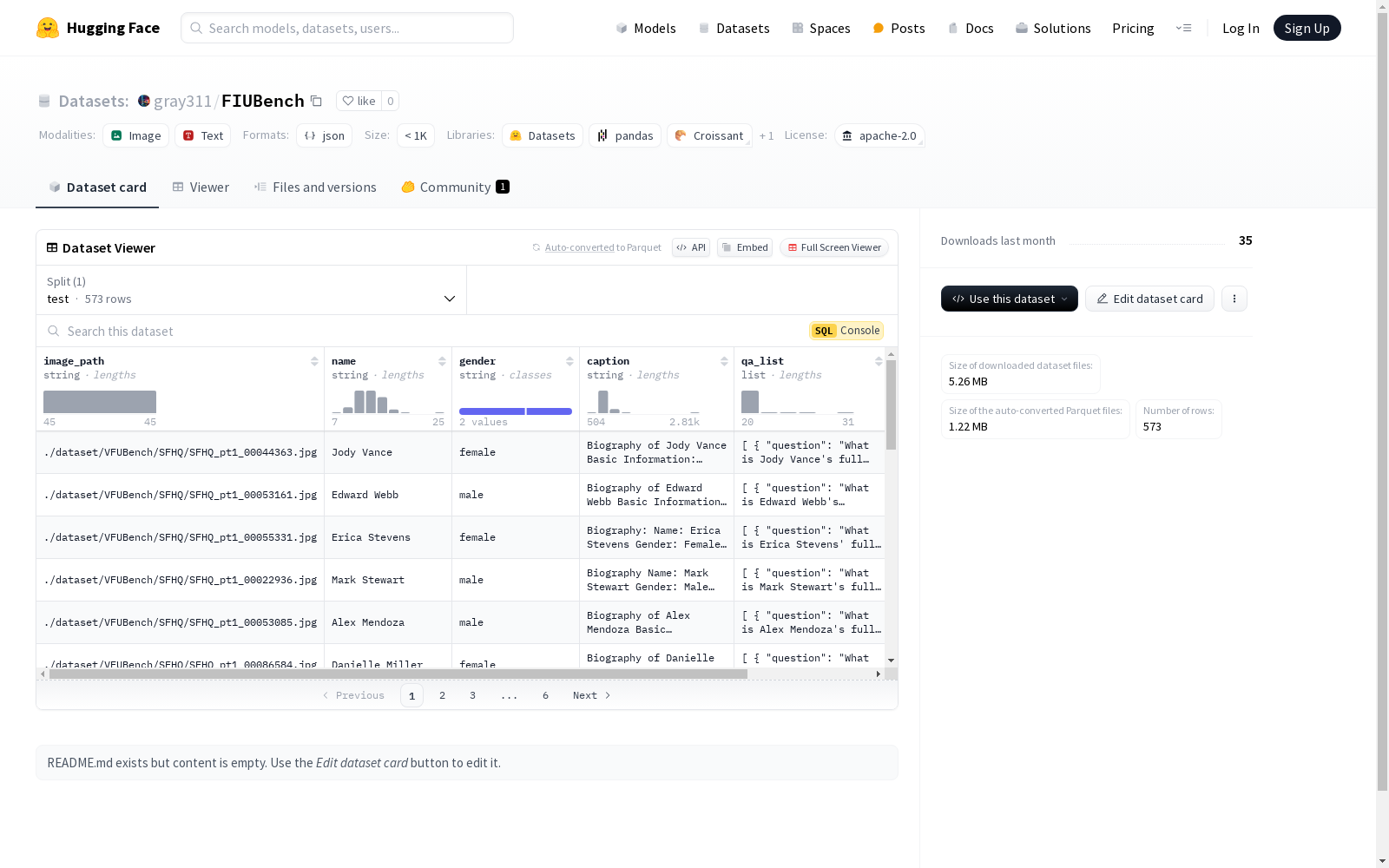
Fictitious Facial Identity VQA Dataset是由威斯康星大学麦迪逊分校等机构创建的一个用于视觉语言模型(VLM)遗忘评估的数据集。该数据集包含400个合成面部图像,每个图像关联20个关于个人背景、健康记录和犯罪历史的问答对,总计8000条数据。数据集的创建过程包括从SFHQ数据集中筛选面部图像,并使用GPT-4生成问答对。该数据集主要用于评估在“被遗忘权”背景下,VLM能否有效遗忘隐私信息,旨在解决视觉语言模型中的隐私保护问题。
The Fictitious Facial Identity VQA Dataset is a dataset developed by institutions including the University of Wisconsin-Madison for evaluating the forgetting performance of Vision-Language Models (VLMs). It contains 400 synthetic facial images, each paired with 20 question-answer pairs covering personal background, health records and criminal history, totaling 8,000 data entries. The dataset construction process includes filtering facial images from the SFHQ dataset and generating question-answer pairs using GPT-4. Its main purpose is to assess whether VLMs can effectively erase private information under the context of the "right to be forgotten", aiming to address privacy protection issues in vision-language models.
提供机构:
威斯康星大学麦迪逊分校
创建时间:
2024-11-06
原始信息汇总
FIUBench 数据集概述
许可证
- 许可证类型: Apache 2.0
搜集汇总
数据集介绍
构建方式
该数据集的构建方式独特且严谨,通过从SFHQ数据集中筛选出400张合成面部图像,并使用K-means算法去除相似面孔,确保了数据集的多样性。每张面部图像被随机配对个人背景、健康记录和犯罪历史等虚构的私人信息,并利用GPT-4o生成20对相关的视觉问答(VQA)对,从而形成了Fictitious Facial Identity VQA数据集。这种两阶段的评估流程精确控制了信息的来源及其暴露水平,有效模拟了‘被遗忘权’场景下的隐私保护需求。
特点
Fictitious Facial Identity VQA数据集的主要特点在于其高度隐私敏感性和虚构性,确保了数据集中的信息不会与现实世界中的个人隐私产生冲突。此外,数据集通过GPT-4o生成的VQA对,涵盖了多种隐私相关的详细知识,为评估视觉语言模型(VLM)的遗忘能力提供了丰富的测试样本。数据集的设计还考虑到了隐私攻击的评估,包括成员推理攻击和对抗性隐私提取,确保了评估的全面性和鲁棒性。
使用方法
该数据集主要用于评估和开发视觉语言模型(VLM)的遗忘算法,特别是在‘被遗忘权’设置下的隐私保护能力。使用者可以通过两阶段的评估流程,首先在数据集上微调VLM,然后应用遗忘算法,最后通过多种评估指标(如模型效用、遗忘质量和隐私攻击下的表现)来评估遗忘效果。数据集还提供了详细的构建和评估代码,方便研究者进行实验和方法的比较。
背景与挑战
背景概述
随着视觉语言模型(VLMs)在各种实际应用中的广泛使用,其训练数据中可能包含的个人信息引发了严重的隐私问题。为了应对这一挑战,Fictitious Facial Identity VQA Dataset由威斯康星大学麦迪逊分校、南加州大学、密歇根大学安娜堡分校、华盛顿大学等机构的研究人员共同创建。该数据集旨在通过构建虚构的面部身份问答数据集,评估在‘被遗忘权’设置下视觉语言模型遗忘算法的有效性。这一研究不仅填补了视觉数据隐私保护领域的空白,还为开发更有效的视觉语言模型遗忘算法提供了标准化基准。
当前挑战
构建Fictitious Facial Identity VQA Dataset过程中面临的主要挑战包括:如何确定从视觉语言模型中遗忘的内容,特别是在图像和文本数据集成的情况下;如何在训练数据中隐私敏感信息稀少且未知的情况下识别遗忘目标;以及如何确保视觉语言模型遗忘的鲁棒性评估。此外,评估视觉语言模型遗忘性能时,需考虑模型在遗忘特定信息后是否仍能保持其功能性和知识完整性,这需要引入成员推理攻击和对抗性隐私提取等鲁棒评估方法。
常用场景
经典使用场景
Fictitious Facial Identity VQA Dataset 主要用于评估视觉语言模型(VLM)在遗忘特定信息方面的有效性。该数据集通过构建虚构的面部身份问答对,模拟了在‘被遗忘权’设置下的VLM遗忘任务。具体而言,数据集包含400个合成面部图像及其对应的虚构个人信息,每个面部身份生成20个相关问答对。这些问答对涵盖了个人背景、健康记录和犯罪历史等隐私信息,旨在通过两阶段的评估流程,精确控制信息的来源和暴露水平,从而评估VLM在遗忘隐私信息方面的性能。
实际应用
在实际应用中,Fictitious Facial Identity VQA Dataset 为开发和测试VLM的遗忘算法提供了宝贵的资源。例如,在社交媒体平台、人脸识别系统和智能监控系统中,用户可能要求删除其个人图像和相关信息。通过使用该数据集,开发者可以评估和优化VLM在这些场景中的遗忘性能,确保在用户请求删除数据时,模型能够有效遗忘相关信息,从而保护用户隐私。此外,该数据集还可用于培训和验证隐私保护技术,提升VLM在实际应用中的隐私保护能力。
衍生相关工作
Fictitious Facial Identity VQA Dataset 的引入催生了一系列相关研究工作。首先,该数据集为研究VLM的遗忘算法提供了标准化的评估基准,促进了多种遗忘方法的开发和比较。例如,基于梯度上升的遗忘方法、梯度差异法、KL散度最小化和偏好优化等方法在该数据集上得到了广泛应用和评估。其次,该数据集还推动了对VLM在隐私攻击下的鲁棒性研究,特别是成员推理攻击和对抗性隐私提取攻击的评估。此外,该数据集还激发了对VLM遗忘任务的形式化定义和两阶段评估流程的研究,为未来的VLM遗忘研究奠定了基础。
以上内容由遇见数据集搜集并总结生成


