CaptionEmporium/TextOCR-GPT4o
收藏Hugging Face2024-06-13 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/CaptionEmporium/TextOCR-GPT4o
下载链接
链接失效反馈官方服务:
资源简介:
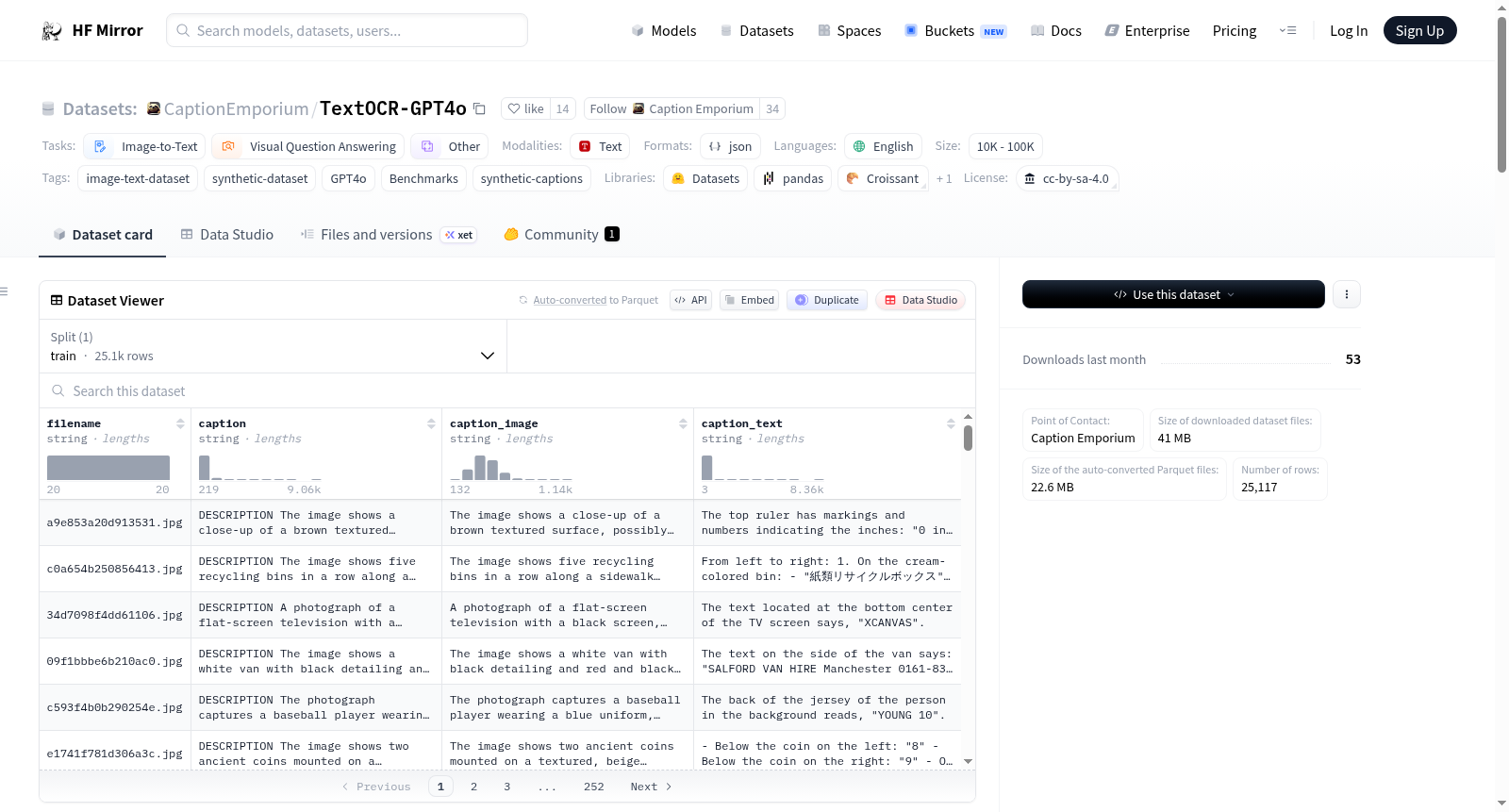
TextOCR-GPT4o是Meta的TextOCR数据集,使用GPT4o生成带有文本OCR重点的标注。该数据集旨在生成基准测试,以比较视觉语言模型与GPT4o的性能。标注语言为英语,而图像中的文本可能包含多种语言,如西班牙语、日语和印地语。数据集的每个实例包含图像文件名、描述图像内容的标注、图像描述部分和图像中文本的转录部分。数据集包含25117个训练实例。
TextOCR-GPT4o is Meta's TextOCR dataset, with annotations focused on text OCR generated using GPT-4o. This dataset is designed to create benchmark tests for comparing the performance of vision-language models against GPT-4o. The annotations are in English, while the text within the images may contain multiple languages such as Spanish, Japanese, and Hindi. Each instance in the dataset includes the image filename, annotations describing the image content, an image description section, and a transcription section for the text within the image. The dataset contains 25,117 training instances.
提供机构:
CaptionEmporium
原始信息汇总
数据集卡片 for TextOCR-GPT4o
数据集描述
- 联系人: Caption Emporium
数据集概述
TextOCR-GPT4o 是 Meta 的 TextOCR 数据集 经过 GPT4o 模型处理,强调文本 OCR 的描述。获取图像需要同意他们的服务条款。
支持的任务
TextOCR-GPT4o 数据集旨在生成用于比较 VLM 与 GPT4o 的基准测试。
语言
描述语言为英语,图像中的文本包含多种语言,如西班牙语、日语和印地语。
原始提示
caption 字段是使用以下提示通过 gpt-4o 模型生成的:
请以以下方式描述这张图片的内容:(1)在标题为“DESCRIPTION”的部分用一到两句话描述(2)在标题为“TEXT”的部分转录图片中的任何文本及其位置。
例如,您可能会描述一张中心有“COCONUT”字样的棕榈树图片为:
DESCRIPTION 海滩上的一棵棕榈树的照片,背景是蓝天,天气晴朗。图像中心有一个蓝色文字标志,带有白色轮廓。
TEXT 图像中心的文字标志写着“COCONUT”。
请确保描述图片中找到的所有文本。
数据实例
"train" 的一个示例如下:
json { "filename": "aabbccddeeff0011.jpg", "caption": "DESCRIPTION 一个香蕉。
TEXT 香蕉上有一个贴纸,上面写着“Fruit Company”。", "caption_image": "一个香蕉。", "caption_text": "香蕉上有一个贴纸,上面写着“Fruit Company”。", }
数据字段
数据字段如下:
filename: 来自原始 TextOCR 数据集 的图像文件名。caption: 包含DESCRIPTION和TEXT部分的描述。caption_image: 描述的DESCRIPTION部分。caption_text: 描述的TEXT部分。
数据分割
| train | |
|---|---|
| TextOCR-GPT4o | 25117 |
数据使用注意事项
数据集的社会影响
[更多信息需要]
偏见讨论
[更多信息需要]
其他已知限制
TextOCR-GPT4o 数据由视觉语言模型 (gpt-4o) 生成,不可避免地包含一些错误或偏见。我们鼓励用户谨慎使用此数据,并提出新的方法来过滤或改进这些不完美之处。
搜集汇总
数据集介绍
构建方式
在计算机视觉与自然语言处理交叉领域,TextOCR-GPT4o数据集的构建体现了前沿技术融合的创新路径。该数据集以Meta的TextOCR原始图像集合为基础,通过GPT-4o这一先进的多模态大模型进行自动化标注。构建过程中,研究者设计了一套结构化的提示模板,要求模型分别生成图像内容的自然语言描述与图像内文本的转录及定位信息。这种方法实现了对图像中视觉元素与嵌入式文本的双重关注,形成了一种半合成式的数据扩充策略,为后续的基准测试提供了统一规范的注释框架。
使用方法
该数据集主要服务于视觉语言模型的基准测试与比较研究,旨在评估模型在图像描述与场景文本识别方面的综合能力。使用者需首先同意原始TextOCR数据集的条款以获取图像文件。在应用时,可分别利用`caption_image`字段进行纯视觉内容理解任务的训练或评估,同时利用`caption_text`字段专注于光学字符识别与文本定位任务的性能测评。研究者亦可将完整`caption`字段用于端到端的多模态理解模型开发,但需谨慎对待其中可能存在的模型生成错误,并建议结合后处理技术以提升数据质量。
背景与挑战
背景概述
在视觉语言模型(VLM)快速发展的背景下,多模态数据集的构建成为推动领域进步的关键。TextOCR-GPT4o数据集由Caption Emporium于2024年创建,其核心研究问题在于利用先进的GPT-4o模型为Meta的TextOCR图像数据集生成结构化描述,特别强调图像中文本的光学字符识别(OCR)。该数据集旨在为视觉语言模型提供基准测试资源,促进模型在图像描述与文本转录任务上的性能评估与比较,对计算机视觉与自然语言处理的交叉领域具有重要的参考价值。
当前挑战
该数据集致力于解决图像中文本识别与描述的复合挑战,即要求模型同时理解视觉场景并准确转录嵌入的文本内容,这对模型的跨模态对齐能力提出了较高要求。在构建过程中,依赖GPT-4o自动生成标注,虽提升了效率,但不可避免地引入了模型固有的错误与偏差,例如文本转录的遗漏或位置描述不精确。此外,数据来源的多样性与语言复杂性(涵盖英语、西班牙语、日语等多语种文本)进一步增加了标注一致性与质量控制的难度,需谨慎使用并辅以后处理方法来优化数据可靠性。
常用场景
经典使用场景
在视觉语言模型(VLM)评估领域,TextOCR-GPT4o数据集为研究者提供了标准化的基准测试平台。该数据集通过GPT-4o模型对原始TextOCR图像进行结构化描述与文本转录,其双重标注机制——即图像内容描述与图像内文本定位——使得它成为衡量模型在复杂场景下图文理解能力的理想工具。经典使用场景包括训练与验证多模态模型在自然图像中识别、转录及理解嵌入文本的效能,尤其适用于评估模型对多语言文本的感知精度。
解决学术问题
该数据集有效应对了视觉语言模型中文本感知能力评估的学术挑战。传统数据集往往缺乏对图像内文本的细粒度标注,而TextOCR-GPT4o通过结构化输出,解决了模型在真实场景下进行端到端文本识别与语义关联的评估难题。其意义在于为跨模态研究提供了可重复的基准,推动了对模型在嘈杂、多语言环境中的稳健性研究,并促进了视觉问答(VQA)与文档分析等方向的算法进步。
实际应用
在实际应用层面,TextOCR-GPT4o能够支持智能文档处理、自动化图像内容审核以及辅助视觉障碍人士的访问技术开发。例如,在电子商务领域,该数据集可训练系统自动提取产品图像中的品牌标签或价格信息;在媒体分析中,则有助于从新闻图片中识别并转录标语或标题,提升内容索引的自动化水平。这些应用凸显了数据集在推动现实世界多模态人工智能解决方案落地方面的价值。
数据集最近研究
最新研究方向
在视觉语言模型领域,TextOCR-GPT4o数据集凭借其由GPT-4o生成的合成标注,正成为评估多模态模型文本理解与生成能力的关键基准。该数据集将图像描述与内部文本转录分离,为研究模型在复杂场景下的光学字符识别与语义融合提供了结构化数据。前沿探索聚焦于利用此类合成标注提升模型在文档分析、广告识别及跨语言环境中的泛化性能,同时关注如何通过后处理技术纠正生成偏差,以推动视觉语言模型在真实世界应用中的鲁棒性与准确性。
以上内容由遇见数据集搜集并总结生成


