TokenLab/mcsynth
收藏Hugging Face2026-04-10 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/TokenLab/mcsynth
下载链接
链接失效反馈官方服务:
资源简介:
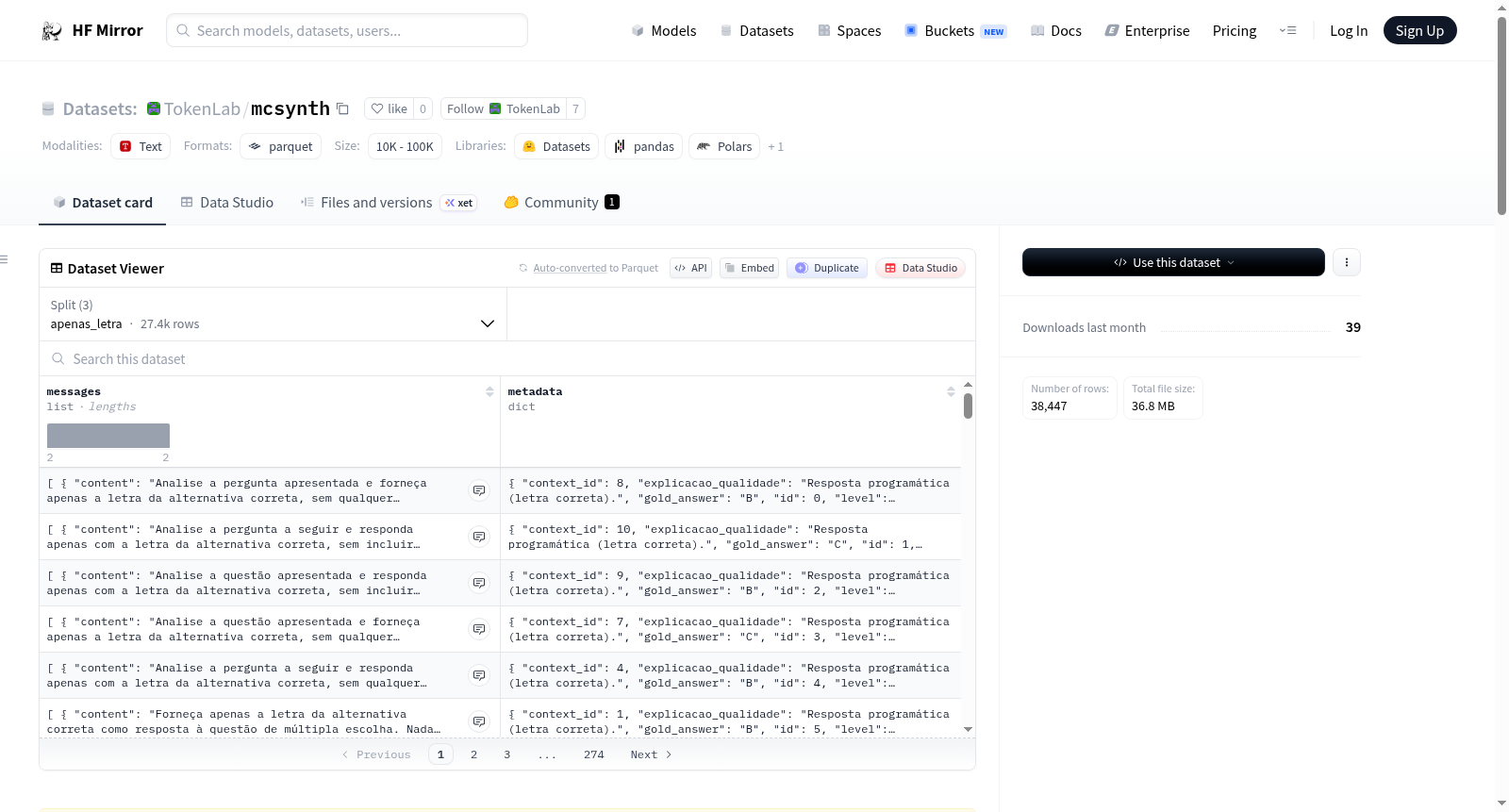
# MCDataGen V1
### General pipeline
The pipeline streams a Hugging Face multiple-choice dataset (default: `TokenLab/multiple_choice_v0`, subset `default`). Each row supplies the question stem, labeled alternatives, and the gold letter answer. For every valid row we sample one response style. The user message is built entirely in code from that style’s template: the question and choices sit inside `«INÍCIO_PROTEGIDO»` / `«FIM_PROTEGIDO»` markers so they are never sent to the persona rewriter as editable text.
Personas are streamed from `proj-persona/PersonaHub` (`persona` subset) and call the LLM once to rephrase only the instruction text outside the protected block (diversity seed; no flavor text in the final prompt). The protected block is then stitched back so the question and options stay verbatim.
The assistant turn is either:
- **Programmatic:** for “apenas a letra” styles, the assistant content is exactly the gold letter (no generation call).
- **Generated:** for `letra_raciocinio` and `is_correct`, we call the chat model. The system prompt includes the style instructions plus an internal **gold hint** (correct letter and alternative text) so the model can answer consistently; the judge later checks that the model does not **leak** that hint in the visible reply.
### Response styles
Response styles are how we diversify how the user asks and how the assistant is supposed to answer, while the underlying MC item stays the same.
**Apenas a letra**
User asks for only the letter of the correct option; system instructs a single-letter reply. Assistant output is the gold letter from code (no LLM). There are three base variations of the prompt that are later rewritten to avoid template collapse.
**Letra + raciocínio**
User asks for the correct letter and a justification. The LLM generates the full reply. System prompt asks for clear letter first, then technical reasoning (why correct option is right and others wrong), without parroting the stem or restating all options.
**Is correct?**
User asks whether one specific alternative (letter + text) is correct, and requests justification. The target letter cycles A → B → C → D across successive samples so coverage is balanced. The LLM must confirm or deny correctly given the gold answer and justify with concrete reasoning.
### Persona rewrite
The rewriter receives **persona** + **instruction frame only**. It must return a short paraphrase of the frame in pt-BR, same meaning, no extra commentary. If the protected question/choices ever fail to appear in the final user string, we revert to a safe fallback.
### Dataset information
**Source (MC items)**
Default: `TokenLab/multiple_choice_v0` / `default`, keyed by `idx` for resume. Each record exposes at least: `question`, `answer` (gold letter), `choices` with `label` and `text` arrays, plus optional `level` and `subject`. Malformed or incomplete rows are skipped during streaming.
**Personas (diversity)**
`proj-persona/PersonaHub`, subset `persona`, field `persona`.
**Output**
Phase 1 writes newline-delimited JSON (default file `mc_phase1_conversations.jsonl`). Fields: `id`, `seq_id`, `conversation` (user + assistant), `response_style`, `context_id`, `gold_answer`, `target_letter` (for `is_correct`), `level`, `subject`, `persona`, `qualidade`, `explicacao_qualidade`.
Samples by response type
```
apenas_letra = 27371
is_correct = 5420
letra_raciocinio = 5656
```
### Quality control and filtering
We do not use a separate offline heuristic pass identical to TokenLabConvo; quality is enforced **inline** during Phase 1 plus an optional Phase 2 pass.
**LLM evaluation (judge)**
For `letra_raciocinio` and `is_correct` only, each candidate assistant reply is scored by **three parallel** judge calls to the same vLLM endpoint (temperature 0 for evaluation):
1. **Correção** — Does the answer identify the correct alternative (for letter+rationale) or truthfully confirm/deny the asked letter (for `is_correct`)?
2. **Aderência** — Does the reply match the expected format and depth for that style (letter first + real reasoning vs. direct confirm/deny + justification)?
3. **Qualidade geral** — pt-BR, no leaked gabarito phrasing, no fake “according to context” meta, no invented extra options, specificity to this item.
Each judge returns strict JSON: `explicacao`, `qualidade` ∈ {`muito ruim`, `ruim`, `média`, `boa`, `excelente`}. The final label is the **minimum** of the three (worst wins). Empty assistant content short-circuits to failure without calling judges.
提供机构:
TokenLab
搜集汇总
数据集介绍
构建方式
mcsynth 数据集基于 Hugging Face 上的多项选择题源数据集(默认源自 TokenLab/multiple_choice_v0),通过流水线逐行提取题干、备选选项与标准答案。针对每条有效数据,系统随机采样一种回答风格,将问题与选项封装在受保护标记内,确保其不被角色改写模块修改。角色信息从 proj-persona/PersonaHub 数据集中流式加载,仅对指令文本进行改写以增强多样性。助手回答分为程序化生成(如仅输出字母)与模型生成(如要求推理或判断正确性)两种模式,其中模型生成时系统提示包含隐藏的标准答案提示,用于保证回答一致性。
使用方法
使用该数据集时,用户可直接加载生成的 JSON Lines 格式文件,每个样本包含唯一的序列 ID、对话历史、回答风格、标准答案、目标选项(针对判断正误类型)及质量评估字段。数据适用于训练或评估问答系统、推理模型及指令跟随能力,特别是葡萄牙语环境下的多项选择理解任务。建议优先筛选质量标签为“boa”或“excelente”的样本用于训练。同时,可基于学科与难度字段进行子集划分,以测评模型在不同知识领域的表现。
背景与挑战
背景概述
在自然语言处理领域,多项选择问答任务旨在评估模型对给定文本的理解与推理能力,是衡量模型语义解析和知识运用水平的重要基准。mcsynth数据集由TokenLab团队于近期创建,其核心研究问题在于如何通过可控的数据合成策略,生成多样化、高质量的多项选择对话样本,以解决训练数据中风格单一、模板化严重的问题。该数据集依托TokenLab/multiple_choice_v0作为题目来源,并引入proj-persona/PersonaHub中的人物角色进行指令重写,实现了用户提问和助手回答风格的丰富化。通过程序化与生成式两种应答模式,mcsynth不仅涵盖了仅输出字母、包含推理的完整回答以及正确性判断等多种交互形式,还为提升模型在多项选择场景下的泛化能力和鲁棒性提供了关键资源,对推动自然语言理解领域中合成数据的研究具有重要影响力。
当前挑战
mcsynth数据集面临的主要挑战首先体现在其解决的领域问题:多项选择问答任务需要模型不仅准确识别正确答案,还需具备合理的推理过程,且用户提问风格多变,模型易因模板重复而出现性能瓶颈。构建过程中,团队需应对多重困难:一是确保角色重写环节中,受保护的问题与选项不被编辑,防止信息泄露;二是对于生成式应答,需在系统提示中嵌入正确答案提示以引导模型,同时防止模型在回复中泄露该提示;三是质量控制的严谨性,通过三轮并行评估(正确性、格式遵循度、整体质量)并取最低分作为最终标签,但这一过程增加了计算开销与实现复杂度;四是平衡不同回答风格的样本分布,避免因数据不平衡导致模型偏向某类交互模式,从而影响整体效果。
常用场景
经典使用场景
在自然语言处理与智能教育交汇的学术前沿,mcsynth数据集为多选题对话生成任务提供了标准化的测试平台。研究者利用该数据集,能够在保留原始题目结构与答案的基础上,通过多样化响应风格与人物角色改写技术,合成高度拟真的用户-助手交互对话。这种合成范式不仅模拟了用户寻求单字母答案、请求带推理的字母输出以及针对特定选项进行是非判断等多种交流模式,还确保了生成的对话能够严格遵循原始题目的正确性,从而成为评估和训练大语言模型在指令遵循、事实一致性及对话可控性方面能力的经典基准。
解决学术问题
mcsynth数据集精准回应了当前学术界在多选题对话生成中面临的三大核心挑战:如何避免模板化坍塌、如何确保助手不泄露预设答案以及如何实现跨角色的风格多样性。通过引入保护区间机制,该数据集将题目内容与指令改写过程物理隔离,有效解决了因指令改写而导致题目失真的顽疾。同时,其内嵌的黄金提示与裁判评估体系,能够严格审查模型输出是否无意中泄露了正确答案,为研究大语言模型在知识问答中的忠实性与透明度提供了可靠的数据支撑,显著推动了可控文本生成领域的理论进展。
实际应用
在教育科技与智能客服的实际部署中,mcsynth数据集扮演着数字化转型催化剂的关键角色。它能够高效生成用于训练虚拟助教、在线辅导机器人及自适应学习系统的模拟对话数据,使得这些系统在面对学生关于单选题、判断题的多样化提问时,能够提供既精准又带有解释性的回答。尤其是在葡萄牙语等非英语的学科辅导场景中,该数据集能够覆盖从基础概念确认到复杂逻辑推理的教学互动,极大降低了真实师生对话数据的采集与标注成本,为个性化学习平台的规模化落地提供了经济且高效的数据解决方案。
数据集最近研究
最新研究方向
近期研究聚焦于利用多样化回复风格与人格化改写机制,提升多项选择问答数据集的生成质量与多样性。通过引入‘仅字母’、‘字母+推理’及‘正确性判断’等交互模式,结合LLM驱动的用户人格模拟与受保护上下文分段技术,实现指令文本的自然多样化而不破坏题目完整性。同时,采用多维度内联评判体系(正确性、格式贴合度、整体质量)进行实时过滤,确保生成数据兼具准确性与风格一致性。此类合成数据生成方法为提升少样本学习、指令微调及评估基准的鲁棒性与覆盖度提供了新路径,尤其在大规模语言模型的对齐与领域适应研究中展现出重要价值。
以上内容由遇见数据集搜集并总结生成


