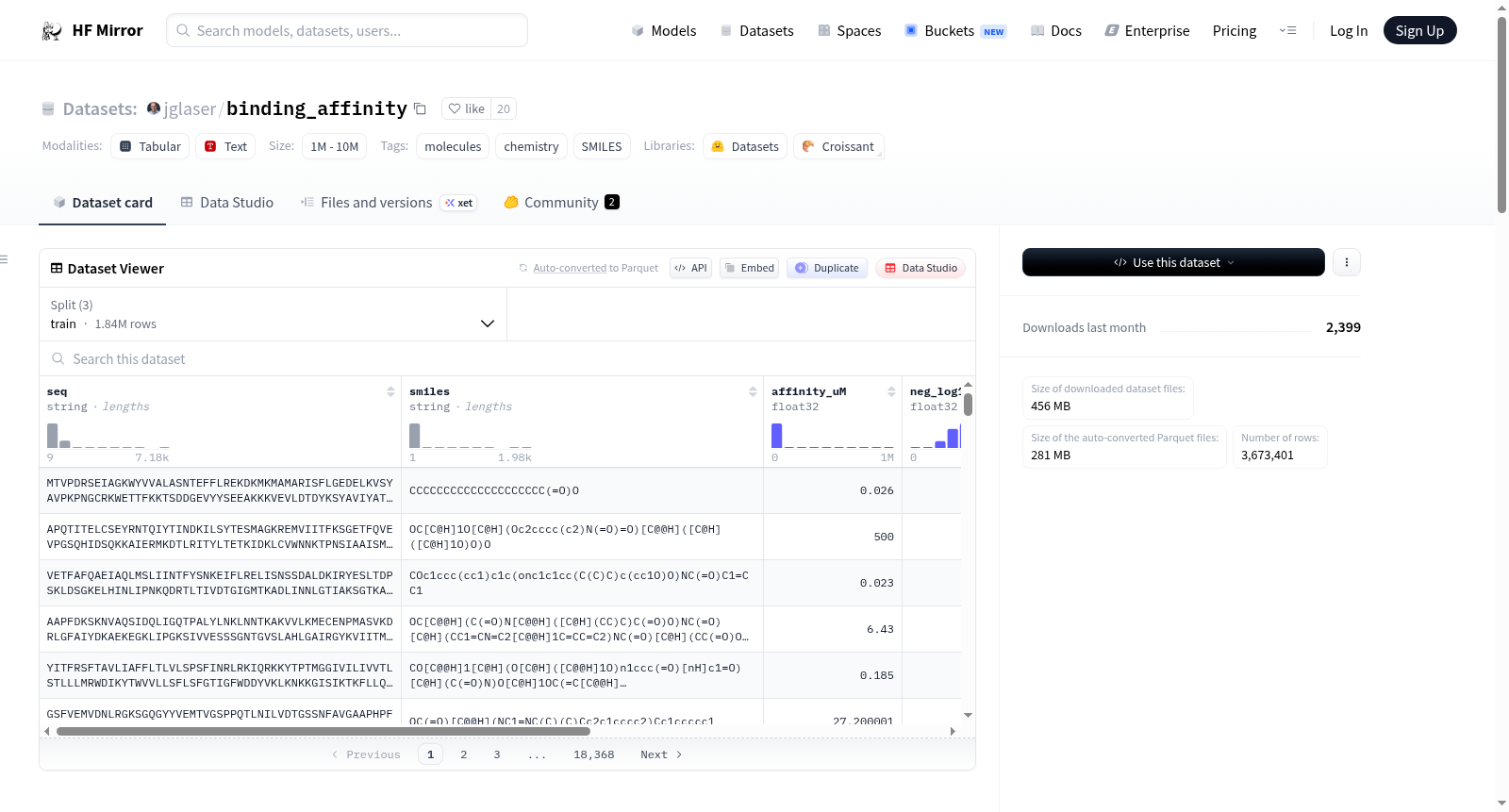
jglaser/binding_affinity
收藏Hugging Face2022-03-12 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/jglaser/binding_affinity
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含190万对独特的蛋白质序列和配体SMILES,这些数据是通过实验确定的结合亲和力。数据集可以用于微调语言模型。数据来源于BindingDB、PDBbind-cn、BioLIP和BindingMOAD。
This dataset contains 1.9 million unique pairs of protein sequences and ligand SMILES, with experimentally determined binding affinities. It can be used for fine-tuning large language models (LLMs), and the data are sourced from BindingDB, PDBbind-cn, BioLIP, and BindingMOAD.
提供机构:
jglaser
原始信息汇总
数据集概述
数据集内容
- 类型: 包含1.9M独特蛋白质序列与配体SMILES对及其实验确定的结合亲和力。
- 用途: 用于微调语言模型。
数据来源
- BindingDB
- PDBbind-cn
- BioLIP
- BindingMOAD
数据预处理
使用预处理数据
- 可通过
from datasets import load_dataset加载训练和验证集。 - 可选数据集包括不含特定蛋白质序列的版本,如
train_no_kras。
手动预处理
- BindingDB: 下载并运行
bindingdb.ipynb。 - PDBbind-cn: 注册下载并运行
pdbbind.py和pdbbind.ipynb。 - BindingMOAD: 下载并运行
moad.py和moad.ipynb。 - BioLIP: 下载并运行
biolip.py和biolip.ipynb。 - 最终合并与过滤: 运行
combine_dbs.ipynb。
数据加载
- 预处理数据存储于
data/all.parquet,需安装git LFS支持下载。
搜集汇总
数据集介绍
构建方式
在计算化学与药物发现领域,高质量的结合亲和力数据对模型训练至关重要。本数据集通过整合四大权威数据库构建而成,涵盖BindingDB、PDBbind-cn、BioLIP与BindingMOAD。构建过程涉及从各源下载原始数据,如BindingDB的TSV文件、PDBbind-cn的索引与复合物文件、BindingMOAD的CSV与压缩文件以及BioLIP的受体与配体档案。随后,利用定制脚本与笔记本进行预处理,包括数据提取、清洗与标准化,最终通过合并与过滤步骤生成包含190万独特蛋白质序列与配体SMILES对的数据集,确保数据的一致性与实验可靠性。
特点
该数据集在分子相互作用研究中展现出显著优势,其核心特点在于规模庞大且来源多样。数据集收录了190万个经实验测定的结合亲和力配对,覆盖广泛的蛋白质与配体组合,为机器学习模型提供了丰富的训练样本。数据来源于多个公开数据库,增强了数据的代表性与泛化能力。此外,数据集提供预处理的Parquet格式文件,便于直接加载使用,同时支持自定义预处理流程,允许用户根据需求调整数据整合策略。可选的分割版本,如去除特定蛋白质序列的数据,进一步提升了在特定生物靶点预测任务中的实用性。
使用方法
在药物设计与生物信息学应用中,本数据集为语言模型微调提供了便捷途径。用户可通过Hugging Face的datasets库直接加载预分割的训练与验证集,例如使用split参数划分90%训练数据与10%验证数据。对于高级应用,数据集支持手动加载预处理的Parquet文件,需依赖Git LFS工具进行数据提取。若需自定义数据整合,用户可遵循详细指南从各源数据库下载原始文件,并运行提供的Python脚本与Jupyter笔记本完成预处理步骤,最终通过合并流程生成定制化数据集,确保数据适应特定研究场景。
背景与挑战
背景概述
在计算化学与药物发现领域,蛋白质-配体结合亲和力的精准预测是加速新药研发的核心环节。数据集jglaser/binding_affinity由研究人员于2021年构建,整合了BindingDB、PDBbind-cn、BioLIP和BindingMOAD四大权威数据库,收录了约190万对蛋白质序列与配体SMILES的实测结合亲和力数据。该数据集旨在为语言模型微调提供高质量资源,推动基于深度学习的分子相互作用建模研究,对虚拟筛选与理性药物设计产生了深远影响。
当前挑战
该数据集致力于解决蛋白质-配体结合亲和力预测这一复杂问题,其挑战在于生物系统的动态性与多样性导致亲和力数值受实验条件、蛋白构象等多因素干扰,模型需从异构数据中提取稳健特征。构建过程中,数据整合面临巨大困难,包括不同来源的格式差异、度量单位不统一以及冗余条目筛选,同时大规模并行处理与跨平台预处理步骤增加了技术复杂度,确保数据一致性与可重复性成为关键瓶颈。
常用场景
经典使用场景
在计算化学与药物发现领域,jglaser/binding_affinity数据集以其190万对蛋白质序列与配体SMILES的独特组合,为分子相互作用研究提供了关键数据支撑。该数据集常被用于微调语言模型,以预测蛋白质与配体之间的结合亲和力,从而加速虚拟筛选过程。通过整合BindingDB、PDBbind-cn等权威来源的实验数据,它成为评估和优化机器学习模型性能的基准工具,尤其在模拟生物分子识别机制方面展现出重要价值。
解决学术问题
该数据集有效解决了药物设计中结合亲和力预测的精度与泛化难题。传统方法依赖耗时费力的实验测定,而本数据集通过大规模标准化数据,支持机器学习模型学习蛋白质-配体相互作用的复杂模式。这不仅提升了预测模型的准确性,还促进了跨蛋白质家族的泛化能力研究,为理解分子识别机制提供了数据基础,推动了计算生物学与人工智能的交叉融合。
衍生相关工作
基于该数据集,衍生出多项经典研究工作,推动了AI在化学领域的进展。例如,研究人员开发了基于Transformer的模型,用于端到端的结合亲和力预测,显著提升了预测效率。同时,该数据集促进了蛋白质特异性预测任务的发展,如针对KRAS蛋白的剔除训练实验,探索了模型在有限数据下的泛化能力。这些工作不仅丰富了计算工具库,还为后续大规模生物分子建模提供了重要参考。
以上内容由遇见数据集搜集并总结生成


