foundation_v0.1
收藏Hugging Face2026-05-07 更新2026-05-08 收录
下载链接:
https://huggingface.co/datasets/fdnai/foundation_v0.1
下载链接
链接失效反馈官方服务:
资源简介:
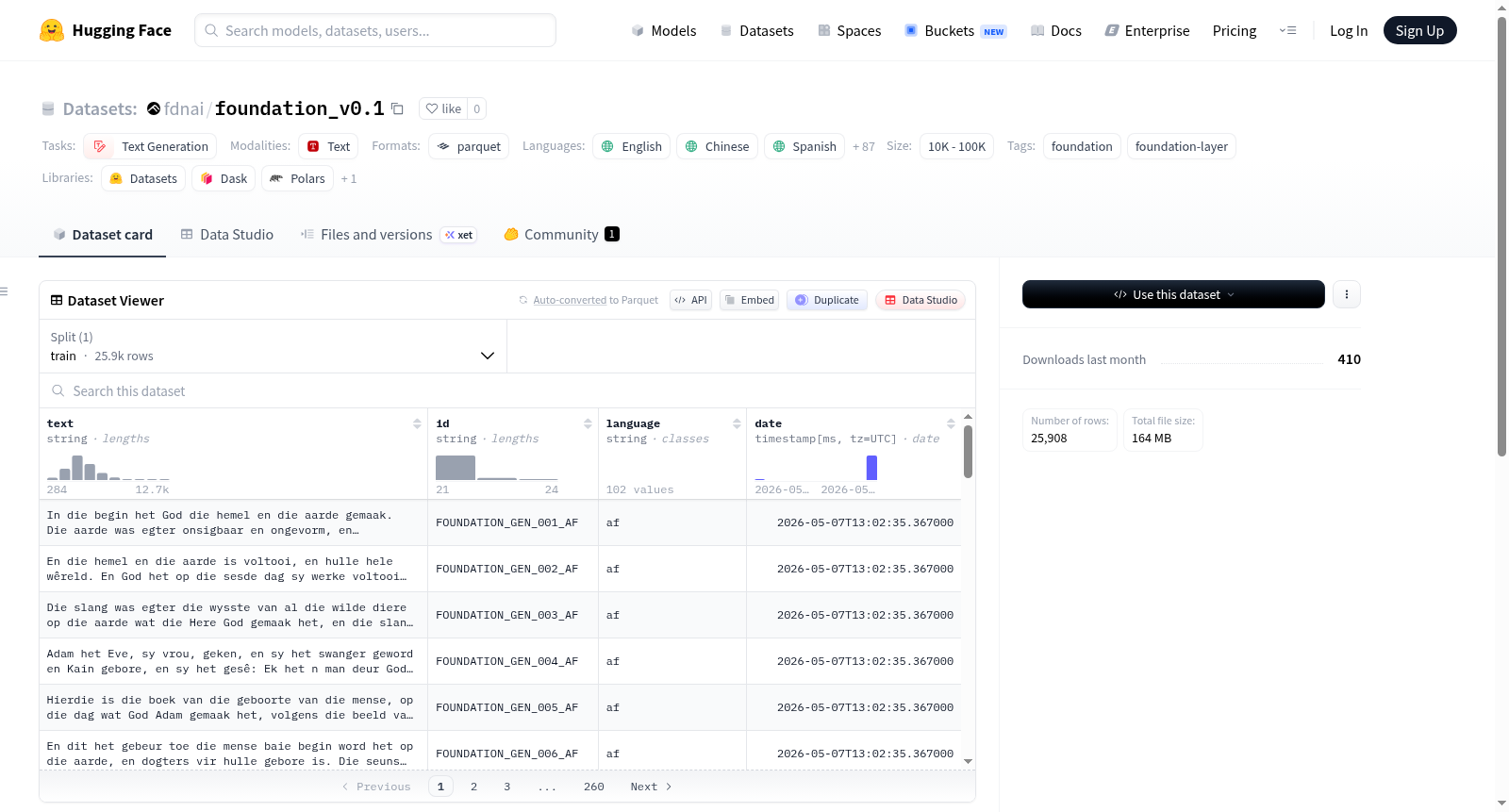
Foundation_AI 是一个多语言基础层训练数据集,旨在为大型语言模型(LLM)的预训练阶段提供支持。该数据集覆盖101种语言(注:HuggingFace平台未全部提供),主要目标包括:1) 提高训练效率并加速模型收敛;2) 强化积极和非歧视性行为;3) 减少幻觉和有害建议的产生;4) 增强跨语言泛化能力。该数据集采用基础层训练方法,适用于文本生成任务。需要注意的是,该数据集及训练方法属于实验性质,尚未经过广泛验证,使用风险需自行承担。
创建时间:
2026-05-04
搜集汇总
数据集介绍
构建方式
Foundation_AI 数据集专为大型语言模型的预训练前阶段设计,旨在通过提供基础层训练数据来优化模型的学习起点。该数据集覆盖了101种语言,其语料经过精心筛选与编排,确保在模型正式预训练之前,能注入高质量、多样化的语言信息。构建过程中,研究者聚焦于四个核心目标:提升训练效率与收敛速度、强化非歧视性行为、减少幻觉与有害输出、增强跨语言泛化能力。数据集以文本生成为主要任务形式,语料来源多元且经过平衡处理,以兼顾语言的广泛性与代表性。
使用方法
使用 Foundation_AI 数据集时,建议将其置于模型预训练流程的起始阶段,作为初始数据批次输入,以建立语言基线与行为规范。研究团队推荐在预处理中保持原始语种分布,以便最大化跨语言迁移效果。用户可直接从 HuggingFace 仓库加载数据,利用其标准文本生成格式适配常见训练框架。需注意,该数据集为实验性资源,使用时需结合自定义验证流程以评估其对特定任务的适用性。建议配合其他预训练数据渐进式引入,避免单一依赖,从而在可控风险下探索其对模型性能的潜在提升。
背景与挑战
背景概述
大型语言模型的预训练过程常面临训练效率低下、收敛缓慢、行为偏见及跨语言泛化不足等核心瓶颈。为应对这一挑战,Foundation_AI数据集于近期被提出,旨在构建一种全新的“基础层”(foundation layer)训练数据,专用于正式预训练之前的阶段。该数据集由相关研究团队创建,覆盖101种语言,涵盖广泛的语言多样性,其核心研究问题聚焦于如何通过结构化的先行训练数据,提升模型训练效率、强化正向与非歧视性行为、缓解幻觉与有害输出,并增强跨语言泛化能力。这一创新思路有望为大语言模型的发展提供一种成本效益更高的基础方案,在多元语言与公平性研究领域具有前瞻性影响。
当前挑战
该数据集面临的核心挑战首先在于所解决的领域问题:大语言模型在预训练阶段缺乏高效的引导机制,导致资源浪费与行为偏差,而现有方法难以兼顾训练速度与模型安全性。Foundation_AI试图通过前置训练数据优化这一过程,但其有效性尚未经过广泛验证。在构建过程中,另一个挑战是确保101种语言的数据覆盖质量与语义一致性,避免低资源语言因数据稀缺而产生偏差或噪声。此外,如何设计数据以同时实现收敛加速、无害化与跨语言泛化,这三项目标之间可能存在权衡,构成了数据集构建与验证中的关键难题。
常用场景
经典使用场景
在自然语言处理领域,大语言模型的预训练阶段是奠定其核心能力的关键环节。foundation_v0.1数据集专为这一初始阶段设计,旨在作为预训练之前的‘基础层’训练语料。其经典使用场景是提供涵盖101种语言的高质量文本数据,用于对模型进行早期、广泛的语言基础培养。通过从头开始或作为预训练流程的第一步,该数据集帮助模型在掌握基础语法、常识知识和跨语言结构上建立稳固根基,从而加速后续的正式预训练过程。这种在预训练之前先行一步的策略,期望能有效提升模型在多样化语言环境下的整体学习效率与收敛速度。
解决学术问题
学术研究中,大语言模型面临训练效率低下、收敛缓慢、行为偏见和跨语言泛化困难等核心挑战。foundation_v0.1数据集旨在通过前置的‘基础层’训练方案,缓解这些长期困扰学界的问题。它提供了一种系统性的数据策略,通过构建多语言、非歧视性的基础语料,强化模型在初期阶段的积极行为规范,同时降低生成幻觉和有害建议的风险。该数据集的引入,为研究如何通过数据质量控制与多语言均衡来提升训练速度、减少偏见和增强模型稳健性开辟了新路径,其意义在于从数据源头探索了改善大模型训练根本机制的可能性。
实际应用
在实际应用层面,foundation_v0.1数据集主要服务于需要训练自定义或领域特定大语言模型的机构与研究者。开发者可以将其作为预训练流程的预热工具,在部署正式大规模训练前,用该数据集对模型进行快速、全面的语言基础塑造。例如,在构建面向全球用户的多语言客服系统、跨文化内容生成平台或教育辅助工具时,利用此数据集先行训练模型,可增强其对英语、中文、西班牙语、阿拉伯语等主流及稀有语言的覆盖能力,并提升在低资源语言上的表现。这使得最终模型在实际交互中表现出更少的偏见、更高的准确性和更强的跨语言迁移能力。
数据集最近研究
最新研究方向
在大型语言模型预训练的前沿探索中,Foundation_AI数据集以101种语言的覆盖广度,开创了“基础层训练”这一新兴范式。该研究方向聚焦于在传统预训练之前植入系统性知识基底,旨在通过多语言正反馈机制加速模型收敛,同时从数据源头遏制有害生成与幻觉现象。这一策略呼应了当前学界对模型安全性与跨语言泛化能力的热切关注,其多语种均衡设计尤其为打破语言鸿沟、构建真正的通用人工智能基础设施提供了实验性框架。尽管仍待大规模验证,该数据集的提出标志着从“被动预训练”向“主动引导”的范式转变,对低资源语言建模与模型伦理对齐具有深远启示。
以上内容由遇见数据集搜集并总结生成


