procbench
收藏ProcBench 数据集概述
数据集描述
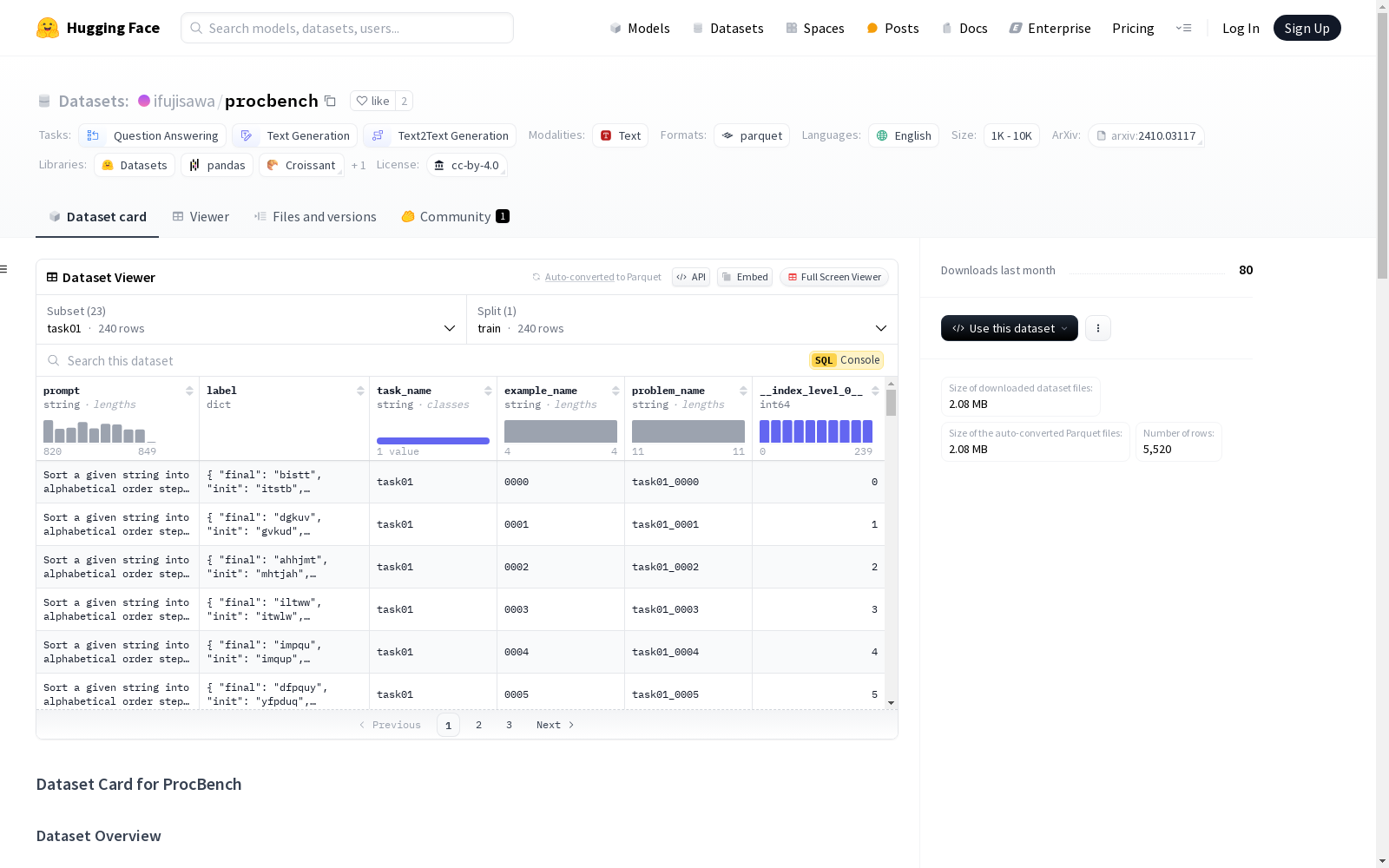
ProcBench 是一个用于评估大型语言模型(LLMs)多步骤推理能力的基准数据集。它专注于指令遵循性,要求模型通过遵循明确的、逐步的程序来解决问题。数据集中的任务不需要复杂的隐含知识,而是强调严格遵循提供的指令。该数据集评估模型在任务上的表现,这些任务对人类来说是直接的,但随着步骤的增加对LLMs来说是具有挑战性的。
- 语言:英语
- 许可证:CC-BY-4.0
数据集结构
数据集包含23种任务类型,总计5,520个示例。任务涉及字符串操作、列表处理和数值计算等操作。每个任务都配有一组明确的指令,要求模型输出中间状态以及最终结果。
难度级别
任务分为三个难度级别:
- 短:2-6步
- 中:7-16步
- 长:17-25步
难度级别可以通过运行GitHub仓库中提供的预处理脚本preprocess.py来获取。
数据集创建
ProcBench 的创建旨在评估LLMs遵循指令的能力。目标是隔离并测试指令遵循性,而不依赖于复杂的隐含知识,提供了一个独特的程序推理视角。
数据收集和处理
每个示例由模板和问题组合而成。每个任务都与一个固定的模板相关联,该模板包含解决问题的程序。所有用于创建问题的模板和生成器都可以在GitHub仓库中找到。
引用
bibtex @misc{fujisawa2024procbench, title={ProcBench: Benchmark for Multi-Step Reasoning and Following Procedure}, author={Ippei Fujisawa and Sensho Nobe and Hiroki Seto and Rina Onda and Yoshiaki Uchida and Hiroki Ikoma and Pei-Chun Chien and Ryota Kanai}, year={2024}, eprint={2410.03117}, archivePrefix={arXiv}, primaryClass={cs.AI} }