STSBench
收藏arXiv2025-06-07 更新2025-06-10 收录
下载链接:
https://huggingface.co/datasets/ivc-lrp/STSBench
下载链接
链接失效反馈官方服务:
资源简介:
STSBench是一个基于场景的框架,旨在评估自动驾驶中视觉语言模型(VLMs)的整体理解能力。该框架使用地面真实标注自动从任何数据集中挖掘预定义的交通场景,提供一个直观的用户界面以便高效的人工验证,并为模型评估生成多项选择题。应用于NuScenes数据集,我们展示了STSnu,这是第一个基于全面3D感知评估VLMs时空推理能力的基准。现有基准通常针对单一视角的图像或视频中的现成或微调VLMs,并专注于语义任务,如对象识别、密集标注、风险评估或场景理解。相比之下,STSnu评估驾驶专家VLMs进行端到端驾驶,操作多视图相机或激光雷达的视频。它特别评估它们对自身车辆行为和交通参与者之间复杂交互的推理能力,这是自动驾驶车辆的关键能力。基准功能43个多样化的场景,跨越多个视图和帧,导致971个人工验证的多项选择题。彻底的评估揭示了现有模型在复杂环境中推理基本交通动态的关键缺陷。这些发现突出了显式建模时空推理的架构进步的迫切需要。通过解决时空评估中的核心差距,STSBench使更健壮和可解释的VLMs的开发成为可能。
STSBench is a scene-based framework designed to evaluate the holistic understanding capabilities of Vision-Language Models (VLMs) in autonomous driving. This framework automatically mines predefined traffic scenarios from any dataset using ground-truth annotations, provides an intuitive user interface for efficient manual verification, and generates multiple-choice questions for model evaluation. When applied to the NuScenes dataset, we present STSnu, the first benchmark that evaluates the spatiotemporal reasoning capabilities of VLMs based on comprehensive 3D perception. Existing benchmarks typically target off-the-shelf or fine-tuned VLMs in single-view images or videos, and focus on semantic tasks such as object recognition, dense labeling, risk assessment, or scene understanding. In contrast, STSnu evaluates driving-specialized VLMs for end-to-end driving, processing videos from multi-view cameras or LiDAR data. It specifically evaluates their reasoning capabilities regarding the behavior of the ego vehicle and the complex interactions between traffic participants, which is a critical capability for autonomous vehicles. The benchmark features 43 diverse scenarios spanning multiple views and frames, resulting in 971 manually verified multiple-choice questions. Comprehensive evaluations reveal critical flaws in existing models' ability to reason about fundamental traffic dynamics in complex environments. These findings highlight the urgent need for architectural advancements that explicitly model spatiotemporal reasoning. By addressing the core gaps in spatiotemporal evaluation, STSBench enables the development of more robust and interpretable VLMs.
提供机构:
格拉茨工业大学视觉计算研究所, 嵌入式机器学习克里斯蒂安·多普勒实验室, 林茨约翰内斯·开普勒大学机器学习研究所, 亚马逊
创建时间:
2025-06-07
原始信息汇总
STSBench数据集概述
基本信息
- 许可证: CC-BY-NC-SA 4.0
- 任务类别: 视觉问答 (Visual Question Answering)
- 语言: 英语 (en)
- 标签:
- VLM (Vision-Language Models)
- 自动驾驶 (Autonomous Driving)
- 时空推理 (Spatio-temporal)
- 多选题 (Multiple Choice)
- VQA (Visual Question Answering)
- 文本 (Text)
- 多视角数据 (Multi-view Data)
- 视频 (Video)
- 图像 (Images)
- LiDAR
- 端到端自动驾驶 (End-to-end Autonomous Driving)
- 自车行为 (Ego-vehicle Actions)
- 自车与代理交互 (Ego-agent Interaction)
- 代理行为 (Agent Action)
- 代理间交互 (Agent-agent Interaction)
- 数据集名称: STSBench
- 规模类别: n<1K (小于1000样本)
数据集配置
- 配置名称: default
- 数据文件:
- 分割: val
- 路径: STSnu/STSnu.json
数据集描述
STSBench是一个基于场景的基准测试框架,用于评估视觉语言模型(VLMs)在自动驾驶中的整体理解能力。该框架通过以下方式实现:
- 自动从任何数据集中挖掘预定义的交通场景(使用真实标注)。
- 提供直观的用户界面以进行高效的人工验证。
- 生成多选题用于模型评估。
特点
- 首个基于3D感知的时空推理能力评估基准:专注于多视角摄像头或LiDAR视频的端到端驾驶模型。
- 评估内容:包括自车行为、交通参与者之间的复杂交互推理能力。
- 场景多样性:包含43种不同场景,覆盖多视角和多帧数据,生成971个人工验证的多选题。
场景类别
-
自车场景 (Ego-vehicle Scenarios)
- 涉及自车的动作(如加速/减速、左/右转、变道)。
- 提供与其他场景相关的负样本。
-
代理场景 (Agent Scenarios)
- 涉及单个交通参与者(如行人、骑行者)。
- 关注其动作(如行走、跑步、横穿马路)。
-
自车与代理交互场景 (Ego-to-agent Scenarios)
- 描述自车与代理的直接交互(如超车、跟随、领先)。
- 直接影响驾驶决策。
-
代理间交互场景 (Agent-to-agent Scenarios)
- 描述两个代理之间的交互(如车辆超车、行人并行移动)。
- 最具挑战性,要求对场景的全面理解。
数据来源
- 基准构建工具: STSBench框架
- 基础数据集: nuScenes (验证集的150个场景)
- 数据范围: 仅包含标注的关键帧。
应用与意义
- 揭示现有模型在复杂环境中推理交通动态的不足。
- 推动显式建模时空推理的架构创新。
- 促进自动驾驶领域更鲁棒、可解释的VLMs发展。
搜集汇总
数据集介绍
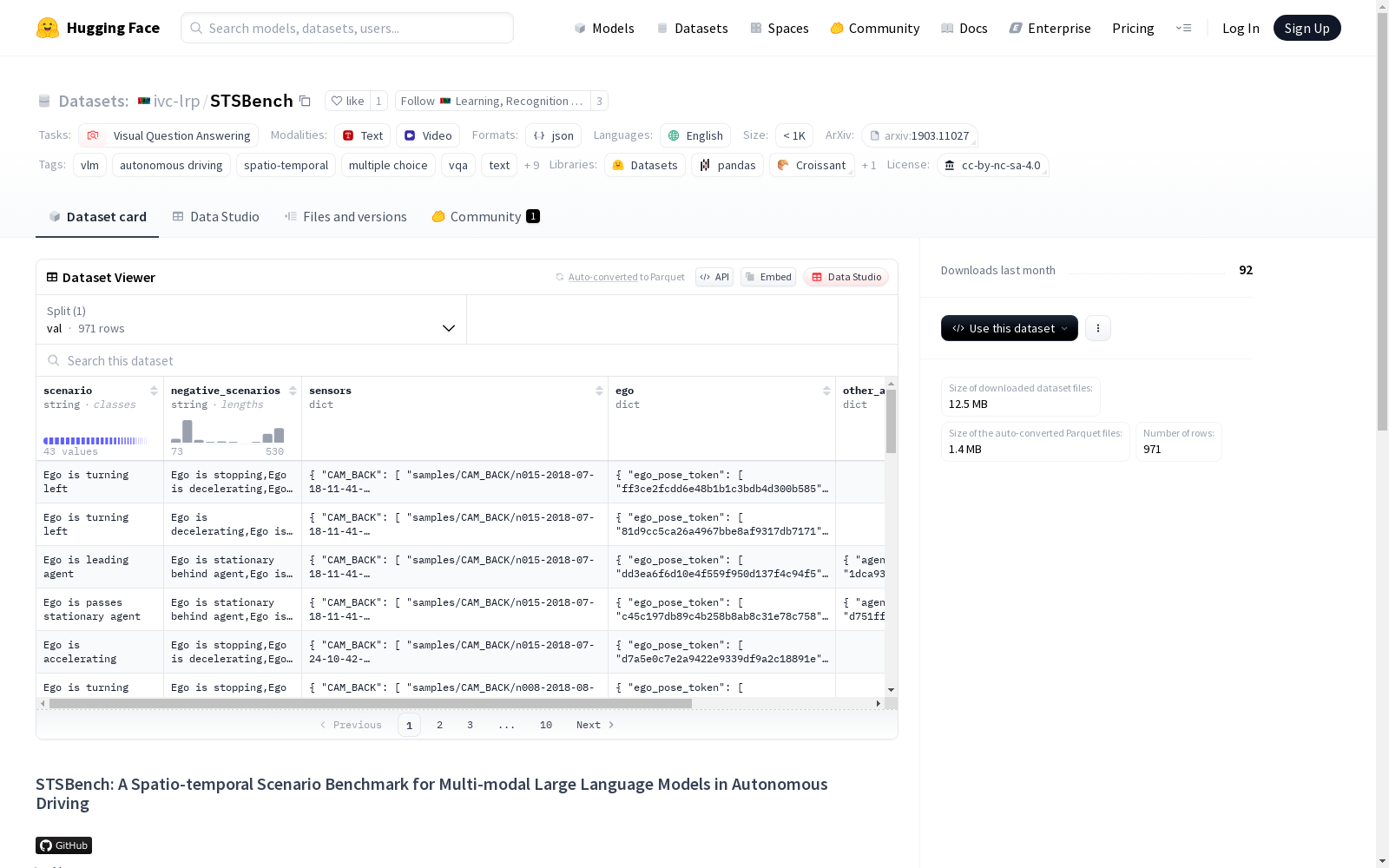
构建方式
STSBench是一个基于场景的基准测试框架,用于评估视觉语言模型(VLMs)在自动驾驶领域的整体理解能力。该框架通过利用真实标注数据自动挖掘预定义的交通场景,提供直观的用户界面进行高效的人工验证,并生成多项选择题用于模型评估。在NuScenes数据集上应用STSBench,我们提出了STSnu,这是首个基于全面3D感知评估VLMs时空推理能力的基准测试。与现有基准测试不同,STSnu专注于评估端到端驾驶专家模型在多视角摄像头或LiDAR视频中的表现,特别关注其对自车行为及交通参与者间复杂互动的推理能力。
特点
STSBench数据集的特点在于其多样化的交通场景覆盖和严格的验证流程。该数据集包含43种不同的交通场景,共生成971道经过人工验证的多项选择题。这些场景涵盖了自车行为、其他交通参与者行为、自车与其他交通参与者的互动以及交通参与者之间的互动四大类别。数据集通过自动挖掘和人工验证相结合的方式构建,确保了高质量和多样性。此外,STSBench还提供了可视化工具,便于快速验证和修正挖掘的场景,大大降低了人工标注的成本和时间。
使用方法
使用STSBench数据集进行模型评估时,首先需要根据场景类型(自车、交通参与者、自车与交通参与者的互动、交通参与者之间的互动)选择合适的评估策略。对于每个场景,模型需要回答一个多项选择题,选择最符合场景描述的选项。评估指标采用准确率,即模型正确回答问题的比例。为了确保评估的公平性,数据集中的多项选择题选项分布均匀,避免了模型因选项位置偏好而导致的偏差。此外,STSBench支持灵活调整多项选择题的选项数量,以适应不同难度的评估需求。
背景与挑战
背景概述
STSBench是由Graz University of Technology、Johannes Kepler University Linz和Amazon的研究人员于2025年提出的一个面向自动驾驶领域的多模态大语言模型(MLLM)评估基准。该数据集基于NuScenes数据集构建,专注于评估模型在复杂交通场景中的时空推理能力。作为首个基于综合3D感知的评估框架,STSBench通过自动化挖掘预定义交通场景、提供高效人工验证界面和生成多选题的方式,系统性地评估驾驶专家模型对自车行为及交通参与者间复杂交互的推理能力。该数据集包含43个多样化场景和971道人工验证的多选题,填补了现有基准在时空评估方面的核心空白,对推动自动驾驶系统向更鲁棒、可解释的方向发展具有重要意义。
当前挑战
STSBench面临的挑战主要体现在两个方面:领域问题方面,现有基准多针对单视角图像/视频的语义任务(如目标识别、密集描述等),难以评估多视角视频或LiDAR数据下的时空推理能力,特别是非自车参与者间的复杂交互理解;构建过程方面,不同数据集的传感器配置差异导致3D空间投影依赖特定校准参数,使得基准难以跨数据集迁移,而传统人工标注方式成本高昂且扩展性差。此外,场景启发式设计需平衡时空过程的可变长度特性,如U型转弯检测时间窗显著长于变道检测,这对自动挖掘算法的通用性提出了挑战。
常用场景
经典使用场景
STSBench数据集在自动驾驶领域被广泛用于评估视觉语言模型(VLMs)的时空推理能力。该数据集通过从NuScenes等大型自动驾驶数据集中自动挖掘预定义的交通场景,生成多项选择题来测试模型对复杂交通动态的理解。其经典使用场景包括评估模型在多种视角和时间步长下对自车行为、其他交通参与者行为以及它们之间复杂交互的推理能力。
衍生相关工作
STSBench衍生了一系列相关研究工作,包括DriveLM(专注于图视觉问答的驾驶模型)、OmniDrive(结合BEV特征和多模态输入的端到端驾驶模型)以及Senna-VLM(用于高级规划决策的视觉语言模型)。这些工作进一步推动了自动驾驶领域中对时空推理能力的探索,并为模型架构的改进提供了重要参考。
数据集最近研究
最新研究方向
STSBench作为自动驾驶领域首个基于多模态大语言模型(VLMs)的时空场景基准,近期研究聚焦于提升模型对复杂交通场景的时空推理能力。该数据集通过自动挖掘NuScenes等真实驾驶数据集中的预定义场景,并构建多视角视频序列的多样化选择题评估体系,填补了现有基准在评估端到端驾驶模型时空理解能力方面的空白。前沿研究主要探索三个方向:一是开发新型架构以显式建模交通参与者间的时空交互关系,解决现有模型在非自车交互场景(如车辆等待行人通过)中表现不佳的问题;二是研究跨数据集泛化方法,利用STSBench框架适配不同传感器配置的驾驶数据集;三是结合链式推理(CoT)和鸟瞰图(BEV)表征等技术创新,提升模型对多视角时序数据的融合理解能力。相关研究正推动可解释自动驾驶系统的发展,其影响延伸至风险预测、决策透明度等安全关键领域。
相关研究论文
- 1STSBench: A Spatio-temporal Scenario Benchmark for Multi-modal Large Language Models in Autonomous Driving格拉茨工业大学视觉计算研究所, 嵌入式机器学习克里斯蒂安·多普勒实验室, 林茨约翰内斯·开普勒大学机器学习研究所, 亚马逊 · 2025年
以上内容由遇见数据集搜集并总结生成


