Tatoeba-Translations
收藏Hugging Face2024-12-29 更新2024-12-30 收录
下载链接:
https://huggingface.co/datasets/ymoslem/Tatoeba-Translations
下载链接
链接失效反馈官方服务:
资源简介:
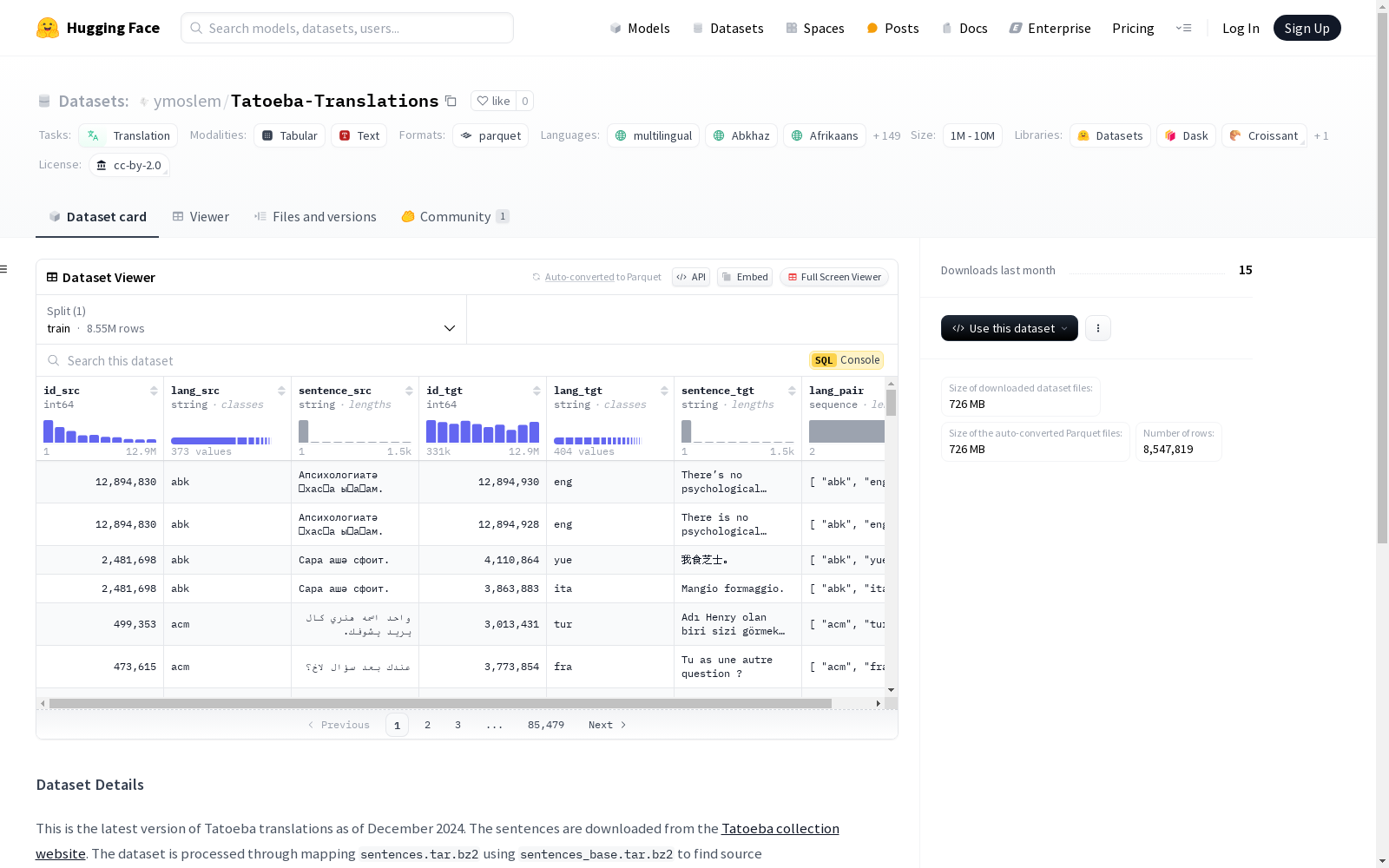
这是截至2024年12月的最新版Tatoeba翻译数据集。句子从Tatoeba集合网站下载,并通过映射`sentences.tar.bz2`和`sentences_base.tar.bz2`文件处理,以找到源句子(`sentence_src`)和目标句子(`sentence_tgt`)。`lang_src`和`lang_tgt`列遵循Tatoeba提供的映射,而`lang_pair`列仅列出翻译对中的两种语言。数据集包含8,547,819个独特的翻译对,覆盖414种语言和约5,917种语言对。
This is the latest version of the Tatoeba translation dataset as of December 2024. Sentences were downloaded from the Tatoeba collection website and processed using the mappings from the `sentences.tar.bz2` and `sentences_base.tar.bz2` files to identify the source sentence (`sentence_src`) and target sentence (`sentence_tgt`). The `lang_src` and `lang_tgt` columns follow the mappings provided by Tatoeba, while the `lang_pair` column only lists the two languages in each translation pair. The dataset contains 8,547,819 unique translation pairs, covering 414 languages and approximately 5,917 language pairs.
创建时间:
2024-12-17
搜集汇总
数据集介绍
构建方式
Tatoeba-Translations数据集的构建基于Tatoeba语言资源库,通过下载并处理`sentences.tar.bz2`和`sentences_base.tar.bz2`文件,提取源语言句子(`sentence_src`)和目标语言句子(`sentence_tgt`)。源语言和目标语言的映射关系由Tatoeba提供,而`lang_pair`列则简单列出了翻译对中的两种语言。该数据集涵盖了414种语言,共计8,547,819个独特的翻译对,涉及约5,917种语言对。
特点
Tatoeba-Translations数据集以其多语言覆盖和丰富的翻译对为显著特点。数据集包含414种语言,涵盖了从常见语言到少数语言的广泛范围,提供了多样化的语言对组合。每个翻译对都经过精心映射,确保源语言和目标语言的准确性。此外,数据集的规模庞大,包含超过850万条翻译对,为机器翻译、语言模型训练等任务提供了丰富的语料资源。
使用方法
Tatoeba-Translations数据集适用于多种自然语言处理任务,尤其是机器翻译和多语言模型训练。用户可以通过Hugging Face平台直接下载数据集,并利用其提供的多语言翻译对进行模型训练和评估。数据集的结构清晰,包含源语言、目标语言及其对应的句子,便于用户进行数据预处理和模型输入输出设计。此外,数据集的开源许可证(CC-BY-2.0)允许用户自由使用和修改数据,进一步推动了其在学术研究和工业应用中的广泛使用。
背景与挑战
背景概述
Tatoeba-Translations数据集是一个多语言翻译数据集,涵盖了414种语言和约5,917种语言对。该数据集由Tatoeba项目创建,Tatoeba是一个致力于收集和分享多语言句子的开源社区。数据集的最新版本发布于2024年12月,由ymoslem处理并上传至Hugging Face平台。Tatoeba-Translations的核心研究问题在于如何通过大规模的多语言句子对,支持机器翻译模型的训练与评估。该数据集在自然语言处理领域具有广泛的影响力,尤其是在低资源语言的翻译任务中,为研究者提供了宝贵的资源。
当前挑战
Tatoeba-Translations数据集在解决多语言翻译问题时面临诸多挑战。首先,数据集中包含大量低资源语言,这些语言的翻译对数量有限,导致模型在这些语言上的表现较差。其次,数据集的构建过程中,语言对的映射和句子对齐需要高度精确,以确保翻译质量。此外,数据集中某些语言的句子可能存在语法错误或文化差异,这进一步增加了数据清洗和预处理的难度。最后,如何在保持数据多样性的同时,确保数据的一致性和准确性,也是构建该数据集时的重要挑战。
常用场景
经典使用场景
Tatoeba-Translations数据集广泛应用于机器翻译领域,特别是在多语言翻译模型的训练与评估中。该数据集包含了超过850万条翻译对,覆盖414种语言,为研究人员提供了丰富的多语言平行语料。通过使用这些数据,研究者能够构建和优化跨语言翻译系统,尤其是在低资源语言的处理上,Tatoeba-Translations展现了其独特的价值。
解决学术问题
Tatoeba-Translations数据集有效解决了机器翻译领域中的多语言翻译难题,尤其是在低资源语言的翻译任务中。传统翻译模型往往依赖于大规模的双语语料,而Tatoeba-Translations通过提供广泛的低资源语言对,填补了这一空白。该数据集为研究多语言翻译模型的泛化能力、跨语言迁移学习以及语言间的语义对齐提供了重要支持,推动了机器翻译技术的进一步发展。
衍生相关工作
Tatoeba-Translations数据集催生了许多经典的研究工作,特别是在多语言翻译模型的开发与优化方面。例如,基于该数据集的研究提出了多种跨语言迁移学习方法,显著提升了低资源语言的翻译质量。此外,该数据集还被用于评估多语言预训练模型(如mBERT、XLM-R)的性能,推动了多语言自然语言处理技术的发展。
以上内容由遇见数据集搜集并总结生成


