PleIAs/WTO-Text
收藏Hugging Face2024-07-12 更新2024-07-22 收录
下载链接:
https://hf-mirror.com/datasets/PleIAs/WTO-Text
下载链接
链接失效反馈官方服务:
资源简介:
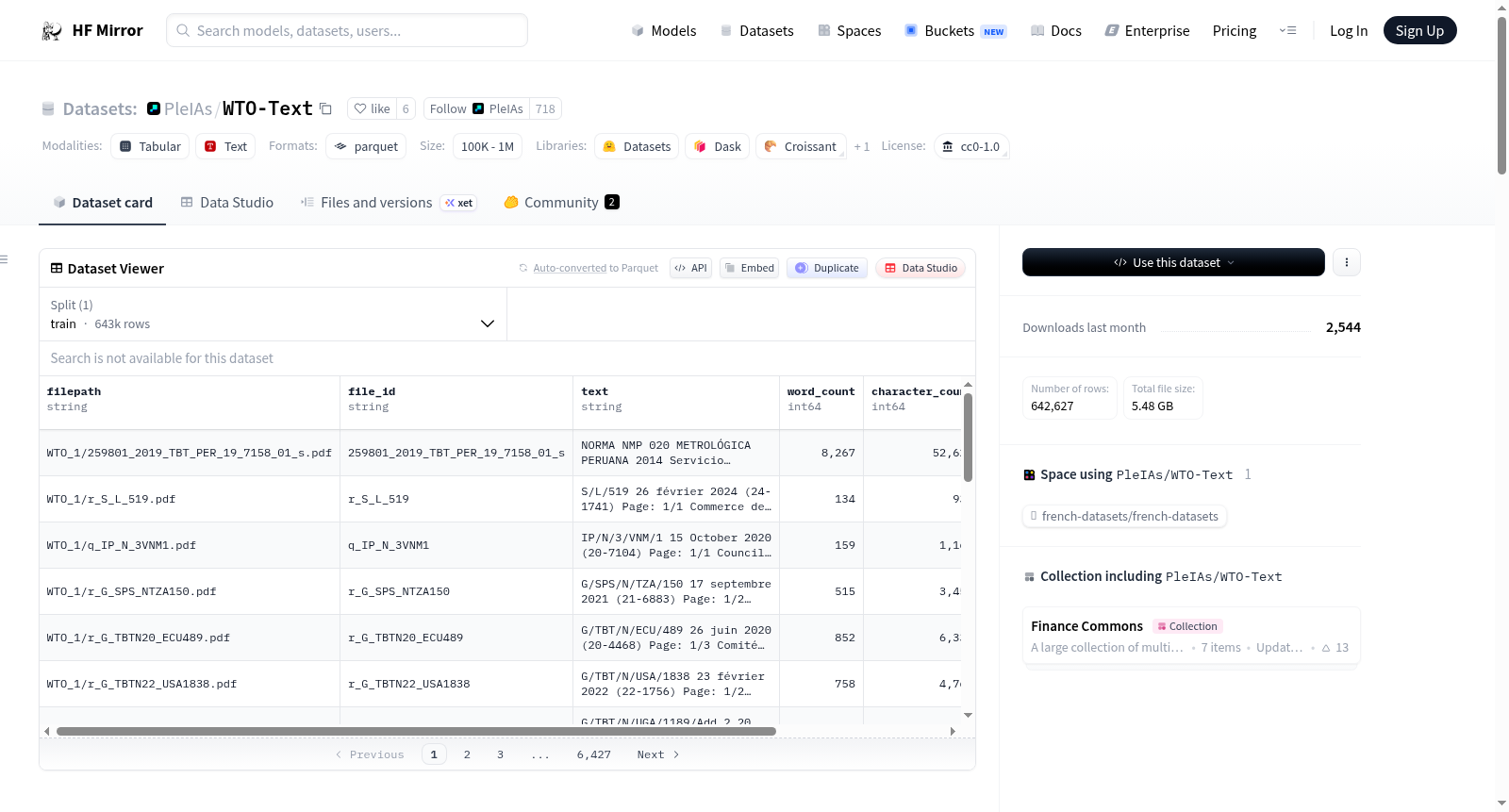
WTO Documents数据集是一个全面的世界贸易组织(WTO)官方文档集合,来源于WTO的官方文档在线平台。该平台提供从1995年以来的文档,支持三种官方语言(英语、法语和西班牙语),并每日更新。数据集包含PDF和Word格式的文档,每个文档都附有描述性目录记录。数据集提供了广泛的搜索功能,用户可以根据符号、国家、主题等标准检索文档,并支持全文搜索。数据集包含131个Parquet文件,总计642,627个条目,平均每个文档有2,364.08个单词。此外,数据集还提供了语言分布的样本数据,展示了不同语言的文档数量。数据集采用CC0 1.0许可证,允许自由使用、分发和复制。
The WTO Documents Dataset is a comprehensive collection of official documentation from the World Trade Organization (WTO). This dataset is sourced from the WTOs official Documents Online platform, which provides access to documents in the three official languages (English, French, and Spanish) from 1995 onwards. The dataset is updated daily and includes documents in PDF and Word formats. Each document is accompanied by a descriptive catalog record. The dataset offers extensive search capabilities, enabling users to retrieve documents based on various criteria such as symbol, country, topic, and full-text search within the document text.
提供机构:
PleIAs
原始信息汇总
WTO Documents Dataset
概述
标题: WTO Documents Dataset
来源: World Trade Organization Documents Online
描述: WTO Documents Dataset 是来自世界贸易组织(WTO)的官方文件的综合集合。该数据集源自WTO的官方Documents Online平台,提供自1995年以来的三种官方语言(英语、法语和西班牙语)的文件。数据集每日更新,包括PDF和Word格式的文件,每个文件都附有描述性目录记录。数据集提供广泛的搜索功能,用户可以根据符号、国家、主题和全文搜索等标准检索文档。
内容和结构
数据集包含大量文档,分为131个Parquet文件,命名为WTO_1到WTO_131。数据集的结构和内容如下:
一般统计
- 总字数: 1,676,595,872
- 总条目数: 642,627
- 每份文档的平均字数: 2,364.08
- 零字数文档数: 70,869
- Parquet文件总数: 131
文档分布
- 每个Parquet文件的平均条目数: 4,906
- 每个Parquet文件的平均零字数文档数: 541
语言分布(10,000份文档样本)
| 语言 | 数量 |
|---|---|
| 法语 (fr) | 3,027 |
| 英语 (en) | 3,593 |
| 西班牙语 (es) | 3,168 |
| 加泰罗尼亚语 (ca) | 10 |
| 简体中文 (zh-cn) | 33 |
| 葡萄牙语 (pt) | 22 |
| 韩语 (ko) | 31 |
| 阿拉伯语 (ar) | 29 |
| 泰语 (th) | 10 |
| 德语 (de) | 28 |
| 威尔士语 (cy) | 1 |
| 意大利语 (it) | 2 |
| 希伯来语 (he) | 5 |
| 乌克兰语 (uk) | 11 |
| 繁体中文 (zh-tw) | 1 |
| 土耳其语 (tr) | 7 |
| 罗马尼亚语 (ro) | 3 |
| 丹麦语 (da) | 1 |
| 瑞典语 (sv) | 1 |
| 荷兰语 (nl) | 1 |
| 印度尼西亚语 (id) | 4 |
| 芬兰语 (fi) | 2 |
| 克罗地亚语 (hr) | 1 |
| 俄语 (ru) | 3 |
| 越南语 (vi) | 3 |
| 希腊语 (el) | 1 |
| 日语 (ja) | 1 |
| 捷克语 (cs) | 1 |
搜索界面
WTO Documents Online平台提供七种不同的搜索界面以方便文档检索:
- 最新文档: 访问最新发布的文档。
- 常用文档: 方便检索经常请求的文档。
- 会议文档: WTO机构正式和非正式会议及其相关文档的列表。
- 按主题: 按广泛的主题类别搜索文档。
- 通知: 按通知成员和WTO法律要求搜索通知文档。
- 高级搜索: 额外的搜索标准,如符号、要求主题和分类。提供全文搜索功能。
- GATT模块: 访问根据关税及贸易总协定(GATT)发布的官方文档。包括乌拉圭回合贸易谈判的文档,并将逐步添加更多文档。
许可
数据集在CC0 1.0 Universal (CC0 1.0) Public Domain Dedication许可下提供,允许在任何媒介中免费使用、分发和复制,前提是注明原作者和来源。
作者
该数据集由PleIAs编译和维护。
用途和应用
WTO Documents Dataset 是研究国际贸易法和政策的学者、政策制定者和法律专业人士的宝贵资源。它提供了一个全面的WTO官方文档档案,提供了对贸易谈判、协议和争端的见解。数据集的广泛搜索功能使其易于导航和检索特定文档,促进了深入的研究和分析。
搜集汇总
数据集介绍
构建方式
在构建WTO文本数据集的过程中,研究者系统性地从世界贸易组织官方文档在线平台获取了自1995年以来的多语言官方文件。这些文档以PDF和Word格式存在,每日进行更新,并附有详细的目录记录。通过自动化流程,原始文档被转化为结构化的文本数据,最终整理为131个Parquet文件,每个文件平均包含约4906个条目,确保了数据集的时效性与完整性。
特点
该数据集以其庞大的规模和丰富的语言多样性著称,总计包含超过16.7亿词汇和64万余条记录,平均每份文档约含2364个词汇。语言分布上,除英语、法语和西班牙语三种官方语言占据主体外,还涵盖了包括中文、阿拉伯语在内的二十余种语言变体,体现了全球贸易文档的多语种特性。数据集支持基于符号、国家、主题及全文的多种检索方式,为深度分析提供了灵活的数据访问途径。
使用方法
使用者可通过加载Parquet文件直接访问结构化文本,利用数据集内嵌的元数据进行高效查询与分析。该资源适用于自然语言处理任务,如多语言文本分类、信息检索及法律文本挖掘,也可服务于贸易政策研究、国际法分析等学术领域。借助其CC0许可,用户可自由进行数据提取、模型训练及衍生作品的创作,仅需遵循署名要求即可。
背景与挑战
背景概述
世界贸易组织(WTO)作为全球贸易治理的核心机构,其官方文档是研究国际贸易法律、政策演变及多边谈判进程的关键资源。PleIAs/WTO-Text数据集由PleIAs团队构建,自2023年起持续更新,旨在系统整合WTO自1995年成立以来的多语言官方文件,涵盖英语、法语和西班牙语等主要语种。该数据集通过结构化存储与元数据标注,为学术界和政策分析者提供了大规模、可追溯的文本语料,显著推动了国际贸易领域的定量研究与文本挖掘应用,增强了多边贸易体系透明度与知识共享。
当前挑战
该数据集致力于解决国际贸易文本分析中的多语言理解与信息检索难题,其挑战在于如何从非结构化文档中精准提取法律术语、谈判立场及政策关联性。构建过程中,面临文档格式异构性(如PDF与Word混合)、多语言对齐复杂性以及零字文档过滤等数据处理瓶颈;同时,需平衡大规模语料更新频率与数据一致性,确保元数据标注的准确性与跨语言检索的实效性,这对自然语言处理技术的适应性提出了更高要求。
常用场景
经典使用场景
在贸易政策与法律研究领域,WTO文本数据集为学者提供了分析全球贸易规则演变的核心语料。该数据集通过整合世贸组织自1995年以来的官方文件,包括协议文本、争端解决报告及会议记录,支持对多边贸易体系进行历时性考察。研究者可借助其多语言结构与全文检索功能,追踪特定议题如关税壁垒或知识产权保护的谈判历程,揭示文本背后的法律逻辑与政策意图。
衍生相关工作
围绕该数据集已衍生出多项前沿研究。例如,斯坦福大学团队开发了基于深度学习的条约条款自动分类系统,提升文件检索效率;日内瓦高级国际关系学院利用其构建了贸易争端预测模型,分析文本情感与裁决结果关联。这些工作推动了计算社会科学与法律文本挖掘的交叉创新。
数据集最近研究
最新研究方向
在全球化与数字治理深度融合的背景下,WTO文本数据集作为国际经贸法律语料库,正推动自然语言处理与政策分析的交叉前沿。研究者利用其多语言、大规模的结构化文档,开发基于深度学习的自动摘要与主题建模技术,以实时追踪贸易协定演变趋势。结合地缘经济热点如供应链重组与数字贸易规则谈判,该数据集支持对争端解决案例的语义挖掘,为预测政策影响提供量化依据。其开放许可特性进一步促进了跨学科合作,使算法模型能够更精准地解析法律文本的复杂性,强化全球治理研究的实证基础。
以上内容由遇见数据集搜集并总结生成


