Nemotron-Math-HumanReasoning
收藏Hugging Face2025-07-15 更新2025-07-16 收录
下载链接:
https://huggingface.co/datasets/nvidia/Nemotron-Math-HumanReasoning
下载链接
链接失效反馈官方服务:
资源简介:
Nemotron-Math-HumanReasoning是一个紧凑的数据集,包含人工编写的数学问题解决方案,这些解决方案旨在模拟DeepSeek-R1等模型的扩展推理风格。这些解决方案由具有奥赛级别数学经验的学生撰写。数据集提供了多种解决方案版本,并报告了与使用QwQ-32B-Preview模型生成的解决方案进行训练相比的训练效果。该数据集可供非商业使用。
提供机构:
NVIDIA
创建时间:
2025-07-10
原始信息汇总
Nemotron-Math-HumanReasoning 数据集概述
数据集描述
Nemotron-Math-HumanReasoning 是一个紧凑的数据集,包含人类撰写的数学问题解决方案,旨在模拟类似 DeepSeek-R1 的扩展推理风格。这些解决方案由具有奥数经验的学生撰写。数据集提供了多个版本的解决方案,并比较了使用人类撰写数据与 QwQ-32B-Preview 生成数据训练的模型性能。
数据集所有者
NVIDIA Corporation
数据集创建日期
2025年6月1日
许可证/使用条款
cc-by-nc-4.0(非商业用途)
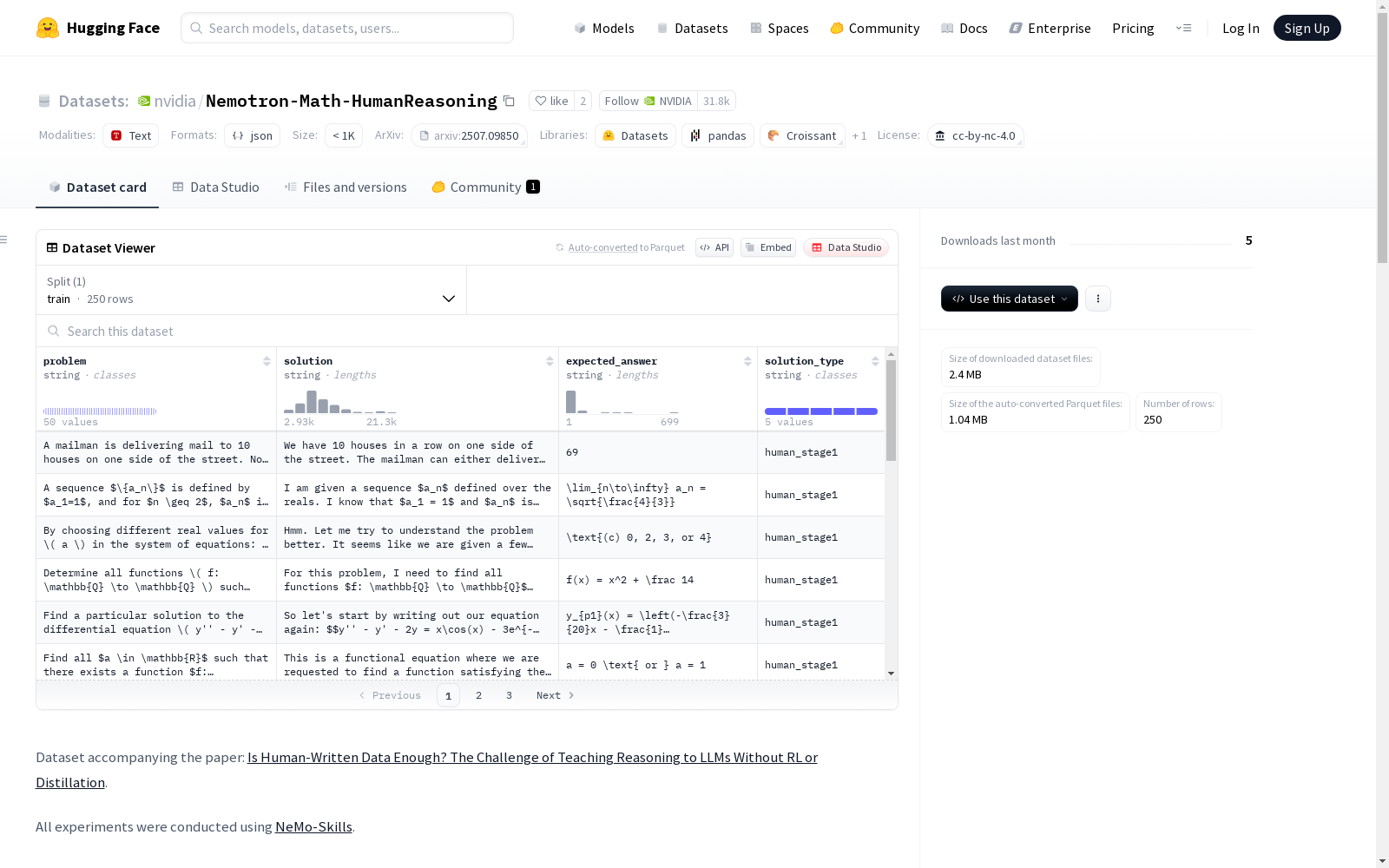
数据集字段
- problem: 数学问题陈述
- solution: 问题解决方案(人类撰写或 QwQ-32B-Preview 生成)
- solution_type: “human_stageX”(X为1到4)或“qwq_32b_preview”
- expected_answer: 问题的标准答案
数据集大小
- 包含50个来自 OpenMathReasoning 的数学问题
- 200个人类撰写的解决方案
- 50个 QwQ-32B-Preview 生成的解决方案
- 总大小:2.4 Mb
数据集格式
纯文本
评估结果
| 数据 | AIME24 | AIME25 | HMMT-24-25 |
|---|---|---|---|
| human_stage1 | 9.27 (33.33) | 6.25 (20.00) | 4.82 (11.73) |
| human_stage2 | 6.93 (20.00) | 5.83 (20.00) | 4.62 (11.22) |
| human_stage3 | 6.41 (20.00) | 4.69 (20.00) | 3.37 (8.16) |
| human_stage4 | 6.41 (26.67) | 5.26 (23.33) | 4.05 (9.69) |
| qwq_32b_preview | 28.02 (56.67) | 21.61 (40.00) | 16.80 (30.10) |
注:指标为 pass@1 (maj@64)
参考论文
Is Human-Written Data Enough? The Challenge of Teaching Reasoning to LLMs Without RL or Distillation
预期用途
语言模型训练
伦理考虑
NVIDIA 强调可信赖 AI 是共同责任,开发者应确保模型满足相关行业和使用案例的要求,并解决意外产品滥用问题。
搜集汇总
数据集介绍
构建方式
在数学推理领域的研究中,Nemotron-Math-HumanReasoning数据集通过精心设计的构建流程脱颖而出。该数据集精选了来自OpenMathReasoning数据集的50道数学题目,并由具有奥数经验的学生撰写了200份详细解答。构建过程中特别设计了四个渐进式的人工标注阶段(human_stage1至human_stage4),同时辅以QwQ-32B-Preview模型生成的50份对比解答,形成了多维度验证的解决方案集合。这种构建方法既保留了人类解题的思维过程,又为对比研究提供了可靠基准。
使用方法
研究人员可通过对比分析不同阶段人类解答与模型生成解答的差异,深入探究有效推理的关键要素。数据集特别适用于微调语言模型的数学推理能力,如示例中展示的Qwen2.5-32B微调实验。使用时需注意区分human_stage1至stage4不同优化阶段的解决方案,并可与qwq_32b_preview方案进行横向对比。评估建议采用论文中提到的pass@1和maj@64双重指标,以全面衡量模型在AIME、HMMT等数学基准测试中的表现。
背景与挑战
背景概述
Nemotron-Math-HumanReasoning数据集由NVIDIA公司于2025年6月发布,旨在探索如何在不依赖强化学习或蒸馏技术的前提下,提升大型语言模型在数学推理任务中的表现。该数据集包含50道数学题目及200份由具有奥数背景的学生撰写的人工解答,以及50份由QwQ-32B-Preview模型生成的合成解答。研究团队通过对比不同训练数据(人工分阶段标注数据与模型生成数据)对模型性能的影响,揭示了人工标注数据在培养模型推理能力方面的独特价值。这项研究为理解人类推理模式与机器推理机制之间的差异提供了重要实证基础,对推动可解释性人工智能发展具有深远意义。
当前挑战
该数据集面临的核心挑战主要体现在两个方面:在领域问题层面,如何准确捕捉人类复杂推理过程中的隐性知识,并将其转化为可训练的显性特征仍是一大难题,现有评估指标(如pass@1和maj@64)虽能反映模型输出准确性,但难以全面衡量推理逻辑的严谨性;在构建过程层面,人工标注需要协调高水平数学专家进行多轮迭代优化,不同标注阶段(stage1-stage4)的质量控制与一致性维护消耗大量资源,而模型生成数据虽然效率较高,但其在HMMT等高级数学竞赛题目上的表现(16.8%准确率)仍显著落后于人类水平,突显了合成数据在复杂推理任务中的局限性。
常用场景
经典使用场景
在数学推理领域,Nemotron-Math-HumanReasoning数据集为研究人类与机器生成解决方案的差异提供了宝贵资源。该数据集通过收录奥林匹克数学竞赛水平学生撰写的问题解决方案,以及QwQ-32B-Preview模型生成的推理过程,成为评估语言模型数学推理能力的基准工具。研究人员可对比分析不同解决方案对模型性能的影响,探索人类思维与机器推理的本质区别。
解决学术问题
该数据集有效解决了数学推理研究中人类标注数据稀缺的核心问题。通过提供多层次的人类阶段解决方案,研究者能够深入探究解决方案质量与模型表现的关系。实验数据表明,人类撰写的解决方案虽在准确率上不及机器生成内容,但为理解推理过程的关键要素提供了独特视角,这对提升语言模型的逻辑推理能力具有重要启示意义。
实际应用
在教育技术领域,该数据集的实际价值体现在智能辅导系统的开发中。通过分析高水平学生的问题解决策略,可优化教学算法设计。同时,对比人类与机器解决方案的差异,有助于开发更接近人类思维模式的数学辅助工具。数据集中的多阶段解决方案也为自适应学习系统提供了丰富的训练素材,能够针对不同学习阶段定制教学内容。
数据集最近研究
最新研究方向
在数学推理领域,Nemotron-Math-HumanReasoning数据集的推出为探索人类书写与模型生成解决方案的差异提供了新的研究视角。近期研究聚焦于比较不同阶段人工标注数据与QwQ-32B-Preview生成数据对模型性能的影响,揭示了合成数据在AIME24、AIME25等数学基准测试中的显著优势。这一发现挑战了传统依赖人类标注数据的训练范式,为如何高效构建数学推理数据集开辟了新思路。数据集的设计理念呼应了当前大语言模型领域对少样本学习与推理能力提升的核心诉求,其精细标注的多阶段解决方案为研究推理链条的构建机制提供了宝贵素材。
以上内容由遇见数据集搜集并总结生成


