重构的综合数据集
收藏arXiv2025-03-27 更新2025-03-28 收录
下载链接:
http://arxiv.org/abs/2503.20752v1
下载链接
链接失效反馈官方服务:
资源简介:
本文重构了一个综合数据集,该数据集由北京大学多媒体信息处理国家重点实验室、北京科学院人工智能研究所、中国科学院大学人工智能学院和北京智源人工智能研究院共同创建,旨在评估视觉认知、几何理解和跨任务泛化能力。数据集覆盖了视觉计数、结构感知和空间变换三个核心领域,包含了高质量的步骤式推理数据,用于激活和增强视觉语言模型在视觉推理任务中的潜力。
This paper reconstructs a comprehensive dataset jointly created by the State Key Laboratory of Media Computing at Peking University, the Institute of Artificial Intelligence of Beijing Academy of Sciences, the School of Artificial Intelligence of the University of Chinese Academy of Sciences, and the Beijing Academy of Artificial Intelligence (BAAI). This dataset is designed to evaluate visual cognition, geometric understanding and cross-task generalization capabilities. It covers three core domains: visual counting, structural perception and spatial transformation, and contains high-quality step-by-step reasoning data to activate and enhance the potential of vision-language models in visual reasoning tasks.
提供机构:
北京大学多媒体信息处理国家重点实验室,北京科学院人工智能研究所,中国科学院大学人工智能学院,北京智源人工智能研究院
创建时间:
2025-03-27
搜集汇总
数据集介绍
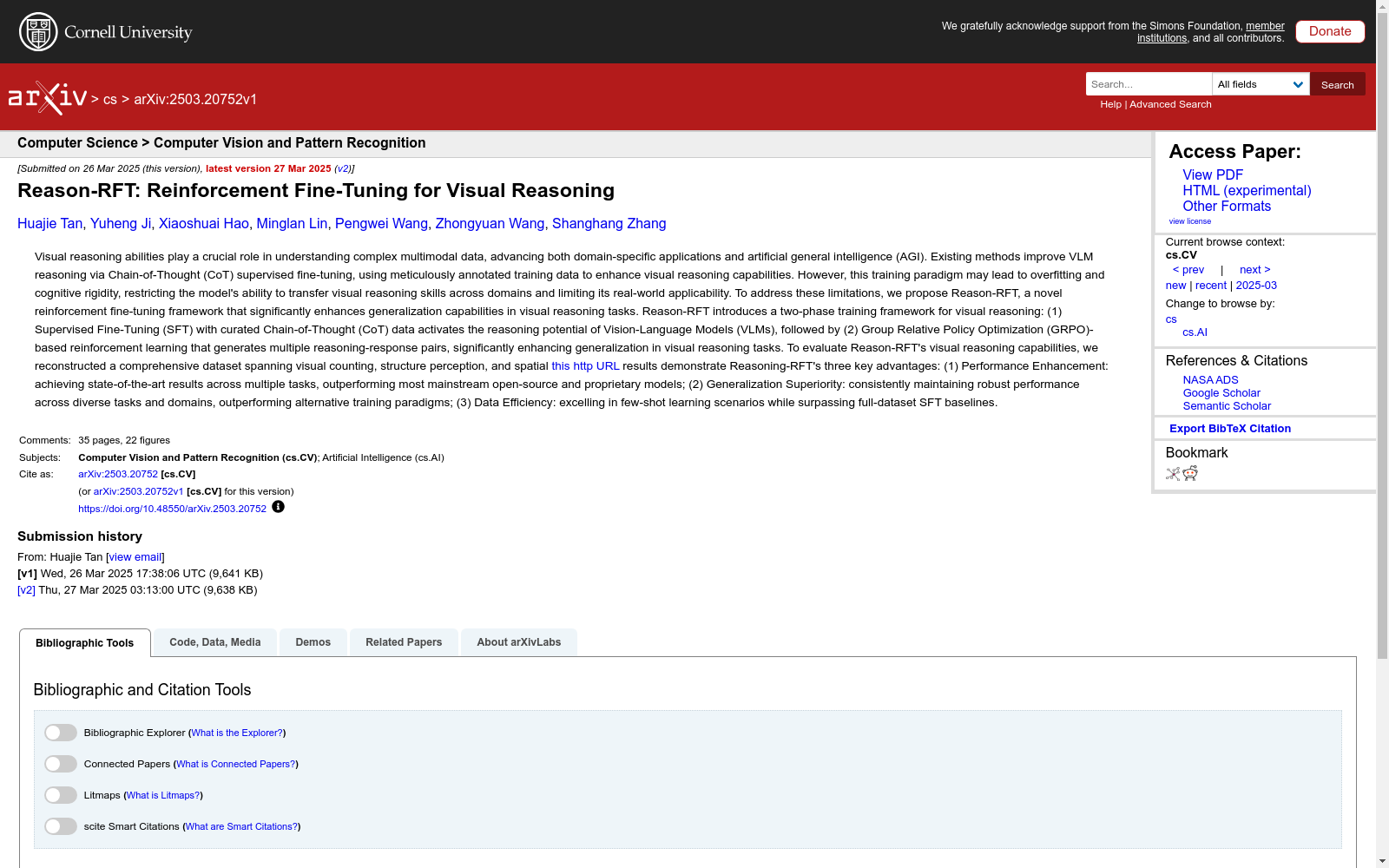
构建方式
重构的综合数据集是通过整合多个现有数据集(如CLEVR-Math、Super-CLEVR、GeoMath和TRANCE)并经过严格筛选和优化构建而成。该数据集覆盖了视觉计数、结构感知和空间转换三个核心领域,旨在系统评估视觉认知、几何理解和跨任务泛化能力。构建过程中采用了GPT-4o进行数据清洗,确保样本质量和多样性,同时通过多视角配置(如中心、左、右视图)增强数据集的复杂性和泛化性。
特点
该数据集具有以下显著特点:1) 多模态融合,结合视觉与语言信息,支持复杂推理任务;2) 任务多样性,涵盖视觉计数、几何问题求解和空间转换等多种挑战;3) 严格的评估标准,针对不同任务设计了格式奖励和精度奖励机制;4) 领域泛化性,通过专门设计的域外测试集(如Super-CLEVR-Math)评估模型跨域适应能力。这些特点使其成为评估视觉推理模型性能的理想基准。
使用方法
数据集的使用分为三个主要阶段:1) 监督微调阶段,利用带有思维链标注的数据激活模型的领域特定推理能力;2) 强化学习阶段,通过组相对策略优化(GRPO)算法进一步提升推理潜力;3) 评估阶段,采用准确率作为核心指标,针对数值答案验证数学等价性,对多选题进行字符串匹配,对函数型序列采用多级逐步评估。用户可通过提供的系统提示模板(如<think>和<answer>标签结构)规范模型输出格式。
背景与挑战
背景概述
重构的综合数据集(Reason-RFT)由北京人工智能研究院(BAAI)与北京大学等机构的研究团队于2025年提出,旨在解决视觉推理任务中的泛化性瓶颈问题。该数据集聚焦视觉计数、结构感知和空间变换三大核心领域,通过整合CLEVR-Math、Super-CLEVR、GeoMath等现有基准并引入严格的质量过滤机制,构建了包含几何理解、空间认知和跨模态推理能力的评估体系。其创新性在于首次将强化微调(RFT)框架引入视觉语言模型(VLMs)的训练范式,通过两阶段训练策略——基于思维链(CoT)的监督微调和基于群组相对策略优化(GRPO)的强化学习,显著提升了模型在分布外场景的适应能力,为多模态推理研究提供了新的方法论范式。
当前挑战
该数据集主要应对两大挑战:在领域问题层面,传统视觉推理方法面临认知僵化、过拟合和跨领域迁移困难等核心问题,特别是当处理需要几何计算(如相似图形面积求解)或复杂空间变换(如多视角物体状态推理)时性能显著下降;在构建过程层面,研究团队需解决三大难题:1) 多源异构数据的质量统一控制,需通过GPT-4o辅助过滤低质量样本;2) 强化学习奖励函数的精细化设计,需平衡格式规范(如<think>标签结构)与语义准确性(如数学表达式容错评估);3) 跨任务评估体系的建立,需在视觉计数对抗样本、几何证明题和三维空间变换等差异化任务中保持度量标准的一致性。
常用场景
经典使用场景
重构的综合数据集在视觉推理任务中被广泛用于评估模型的跨领域泛化能力。该数据集涵盖了视觉计数、结构感知和空间转换三大核心领域,为研究者提供了一个系统评估视觉认知、几何理解和空间泛化能力的基准。在视觉计数任务中,模型需要解决涉及3D场景中物体属性的算术问题;结构感知任务则要求模型理解几何图形的结构关系并进行计算;空间转换任务则测试模型从不同视角推断物体状态变化的能力。
解决学术问题
该数据集有效解决了视觉推理领域中的三个关键学术问题:一是传统监督微调方法导致的过拟合和认知僵化问题,通过引入强化学习微调框架提升了模型的泛化能力;二是跨领域迁移的挑战,通过精心设计的任务和数据集验证了模型在未见领域的表现;三是数据效率问题,证明了模型在少量数据下仍能保持优异性能。这些突破为多模态推理研究提供了新的方法论支持。
衍生相关工作
基于该数据集衍生的经典工作包括Reason-RFT框架及其变体,这些工作系统比较了监督微调与强化学习在视觉推理中的表现。相关研究还探索了格式奖励与精度奖励的优化设计,提出了针对不同任务类型的定制化奖励机制。在数据集层面,后续工作扩展了视觉计数任务的多样性,并开发了更复杂的空间转换场景,持续推动着多模态推理领域的发展。
以上内容由遇见数据集搜集并总结生成


