frwiktionary
收藏Hugging Face2026-01-16 更新2026-01-17 收录
下载链接:
https://huggingface.co/datasets/cargilcm/frwiktionary
下载链接
链接失效反馈官方服务:
资源简介:
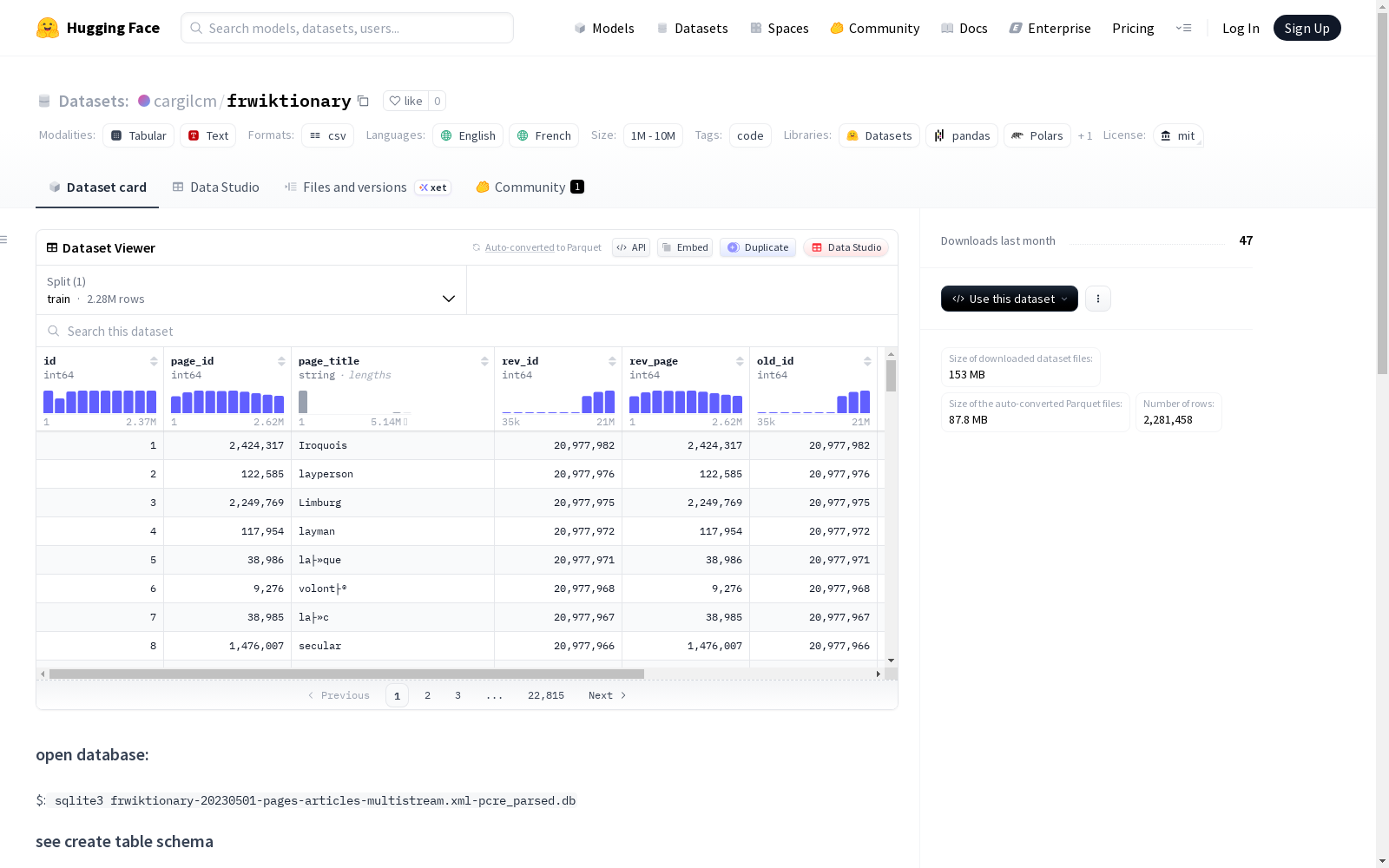
该数据集是一个包含法语Wiktionary(维基词典)解析内容的SQLite数据库,主要表格'joined_trans'存储了37,010条带有翻译文本的词条记录,包含页面ID、标题、修订ID和翻译文本等字段。数据集来源于2016年的研究项目,但实际完成于2023-2024年。需要注意的是,由于使用latin_swedish_ci字符集导入数据,部分特殊字符可能出现乱码问题。
创建时间:
2026-01-14
原始信息汇总
数据集概述
基本信息
- 数据集名称: frwiktionary-20230501-pam-pcre_parsed.db
- 许可证: MIT
- 支持语言: 英语 (en)、法语 (fr)
- 标签: code
- 数据规模: 10K<n<100K
数据内容
- 数据源: 法语 Wiktionary (2023年5月1日版本)
- 核心数据表:
joined_trans - 表结构:
id: 整数,非空page_id: 整数,可为空page_title: 字符串 (最大长度255),可为空rev_id: 整数,可为空rev_page: 整数,可为空old_id: 整数,可为空text_transd: 字符串 (最大长度1255),可为空
数据统计
- 总行数: 2,281,460
- 有效翻译文本行数: 37,010 (通过
select count(*) from joined_trans wheretext_transd!= NULL;查询获得) - 规模说明: 有效词条数量显著少于英语词典(通常约6万词),这与相关论文中描述的法语 Wiktionary 中分配了翻译文本的词汇不足情况一致。
已知问题
- 字符编码问题: 数据导入时使用了默认的 latin_swedish_ci 排序规则,导致特殊字符被错误映射,可能产生乱码文本或查询无结果。
- 影响示例: 查询词条 "être" 时,由于编码问题,需要使用错误映射后的字符串 "├¬tre" 进行查询。
- 解决计划: 计划在2026年6月1日之前,通过字符串替换所有错误的特殊字符来修复乱码问题,但此计划可能因个人原因延迟。
相关资源
- 参考论文: 可通过 https://sci-hub.ee/10.1109/i-Society.2016.7854182 下载以避免付费墙。
- 示例查询: 可在 https://huggingface.co/datasets/cargilcm/frwiktionary/viewer?views%5B%5D=train&sql=SELECT+*+%0AFROM+train+%0AWHERE+page_title+%3D+%27%E2%94%9C%C2%ACtre%27%0ALIMIT+100%3B 查看由于编码问题导致的 "être" 词条查询示例。
搜集汇总
数据集介绍
构建方式
在语言资源构建领域,frwiktionary数据集源自法文维基词典的条目解析与结构化处理。该数据集通过提取2023年5月1日的法文维基词典页面文章多流XML文件,并运用PCRE正则表达式进行解析,将原始文本转化为结构化的数据库格式。解析过程中,关键字段如页面标题、修订标识及翻译文本被提取并存入SQLite数据库的joined_trans表中,形成了包含37,010条有效翻译条目的语料集合,为跨语言词汇研究提供了基础数据支撑。
特点
该数据集在词汇资源方面展现出独特的特点,其规模虽较英文词典为小,但精准聚焦于法文维基词典中实际标注翻译的词汇条目,避免了未翻译或空值数据的干扰。数据以SQLite数据库形式存储,支持高效的查询操作,便于研究者直接通过SQL语句访问特定词汇的翻译信息。然而,由于数据导入时字符编码设置的影响,部分特殊字符存在乱码现象,这为数据的使用带来了一定的预处理需求,同时也反映了多语言数据处理中字符编码一致性的重要性。
使用方法
对于研究者而言,使用frwiktionary数据集需借助SQLite数据库工具进行交互。用户可通过执行SQL查询语句,如SELECT * FROM joined_trans WHERE page_title = '特定词汇',来检索目标词汇的翻译内容。鉴于数据中存在的字符乱码问题,建议在使用前评估编码影响,或通过字符串替换方法修正特殊字符,以确保数据的准确性与可读性。该数据集适用于跨语言学习、机器翻译辅助资源及词典学研究等场景,为语言技术开发提供了实用的词汇对齐参考。
背景与挑战
背景概述
frwiktionary数据集源于法语维基词典的数字化工程,由研究人员于2023至2024年间构建完成,其核心研究问题聚焦于多语言词典资源的自动化解析与结构化存储。该数据集基于2016年相关学术论文所提出的方法论,旨在通过提取法语维基词典中的词条与翻译文本,为自然语言处理领域提供高质量的双语词汇对齐资源。其影响力不仅体现在跨语言信息检索与机器翻译任务中,还为词典学与计算语言学之间的交叉研究搭建了桥梁,推动了开放语言数据在学术与工业界的应用。
当前挑战
frwiktionary数据集所解决的领域问题在于多语言词典数据的标准化与可访问性,其挑战体现在如何从非结构化的维基词典文本中准确提取并对齐双语词条,同时处理语言特有的形态与语义歧义。在构建过程中,数据集面临字符编码转换的难题,由于导入时默认使用了latin_swedish_ci校对规则,导致特殊字符如法语重音符号被错误映射,产生乱码现象。此外,数据集规模相对有限,仅包含约37,010条有效翻译文本,远少于典型英语词典的词汇量,这反映了法语维基词典中翻译标注的覆盖不足,需通过后续数据清洗与扩充来提升完整性与实用性。
常用场景
经典使用场景
在自然语言处理领域,多语言词典数据集如frwiktionary常被用于跨语言词义对齐与翻译任务。该数据集通过解析法语维基词典的结构化内容,提供了大量法语词条及其对应的翻译文本,为研究者构建双语或多语词汇映射资源奠定了数据基础。典型应用包括训练跨语言词嵌入模型,其中模型通过学习不同语言间词汇的语义对应关系,实现词向量的跨语言对齐,进而支持下游的机器翻译或跨语言信息检索任务。
实际应用
在实际应用中,frwiktionary数据集为开发多语言工具和系统提供了核心词汇支持。例如,在构建教育类语言学习应用时,该数据集可作为法语词汇释义与翻译的权威参考源,辅助生成词汇卡片或交互式练习。在商业搜索引擎或内容平台中,其翻译对信息可用于增强跨语言查询扩展或文档分类功能,帮助用户跨越语言障碍获取信息。此外,它还能为本地化行业提供术语库补充,提升翻译一致性与效率。
衍生相关工作
围绕frwiktionary这类多语言词典数据,学术界已衍生出多项经典研究工作。例如,基于维基词典结构解析的跨语言知识图谱构建方法,将词条与翻译关系整合为语义网络,支持跨语言实体链接。同时,该数据常被用于评估跨语言词嵌入模型(如MUSE或VecMap)的性能,通过测量翻译对的向量相似度来验证对齐效果。此外,相关研究还探索了利用词典数据增强神经机器翻译的稀有词处理能力,或改进低资源语言的无监督翻译模型。
以上内容由遇见数据集搜集并总结生成


