VisImages
收藏arXiv2022-03-06 更新2024-06-21 收录
下载链接:
https://visimages.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
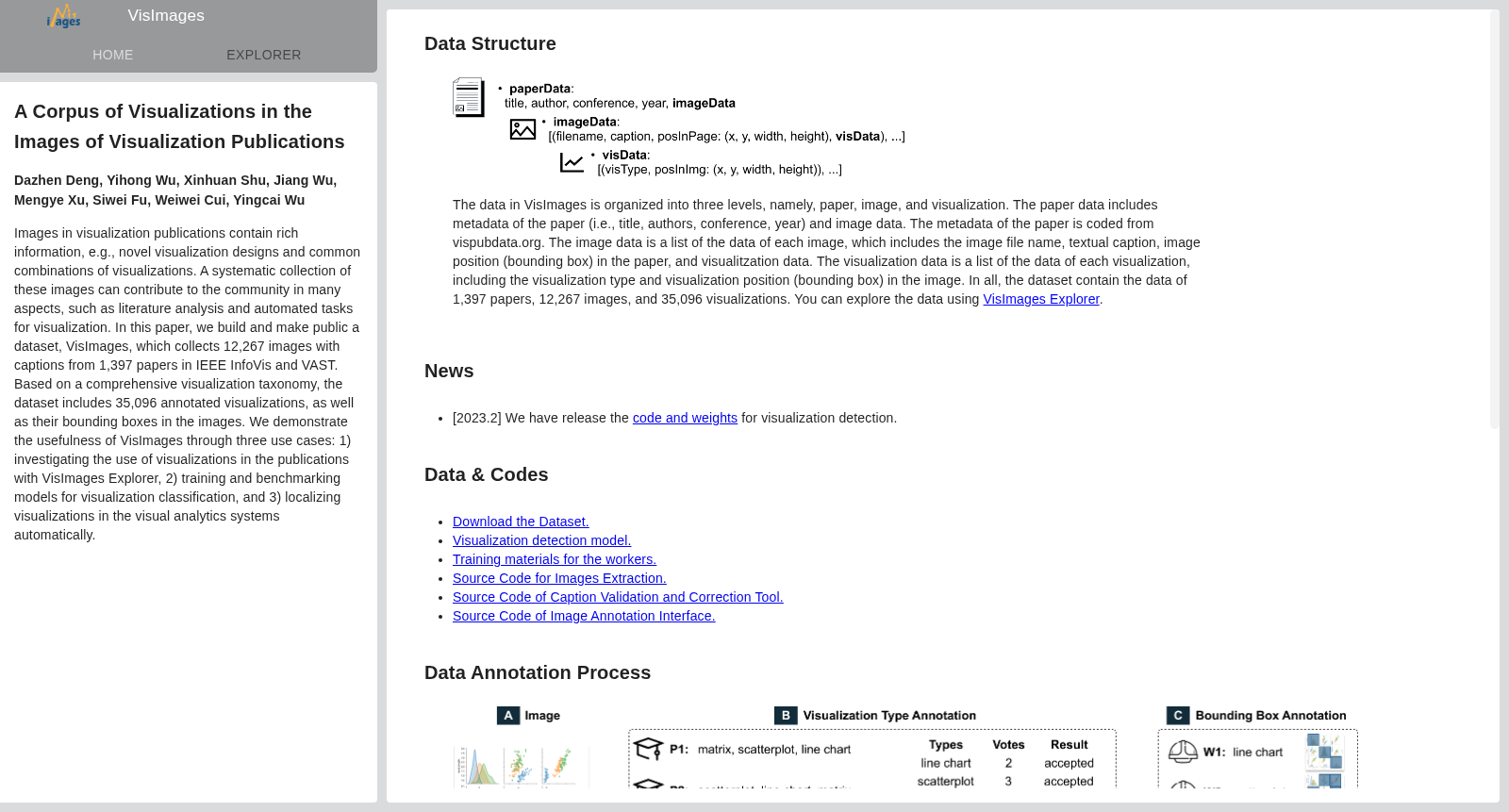
VisImages数据集是由浙江大学CAD&CG国家重点实验室创建的,专注于可视化出版物中的图像数据。该数据集包含12267张图像,来源于1397篇IEEE InfoVis和VAST的论文,每张图像都配有详细的标题和边界框注释,总计35096个可视化元素。数据集通过一个综合的可视化分类法进行组织,旨在支持可视化领域的文献分析和自动化任务,如可视化分类和检测。VisImages不仅提供了可视化设计的新颖性和复杂性,还通过其详尽的注释支持了人工智能在可视化研究(AI4VIS)中的应用,为研究者提供了一个宝贵的资源,以探索和理解可视化领域的发展趋势和设计实践。
VisImages Dataset was created by the State Key Laboratory of CAD&CG at Zhejiang University, focusing on image data from visualization publications. This dataset contains 12,267 images sourced from 1,397 papers published in IEEE InfoVis and VAST conferences. Each image is accompanied by detailed captions and bounding box annotations, totaling 35,096 visualization elements. Organized via a comprehensive visualization taxonomy, the dataset is designed to support literature analysis and automated tasks in the visualization field, such as visualization classification and detection. VisImages not only showcases the novelty and complexity of visualization designs but also supports the application of artificial intelligence in visualization research (AI4VIS) through its exhaustive annotations, serving as a valuable resource for researchers to explore and understand the development trends and design practices in the visualization domain.
提供机构:
浙江大学CAD&CG国家重点实验室
创建时间:
2020-07-09
搜集汇总
数据集介绍
构建方式
VisImages数据集的构建始于从IEEE InfoVis和VAST两大顶级可视化会议中收集论文图像。研究团队首先利用PDFFigures 2.0工具从1,397篇论文中提取出12,267张图像及其对应的12,057条文字说明。在此基础上,采用了一套经过扩展和完善的可视化分类体系,该体系涵盖13个大类和34个子类型。为了确保标注的准确性与专业性,可视化类型的标注工作邀请了25位具有可视化研究背景的参与者,每张图像由三人独立标注,并通过多数投票机制确定最终类型。随后,针对已标注类型的图像,团队委托专业数据标注公司的众包工人为每种可视化绘制边界框,并对标注过程实施严格的质量控制,包括黄金标准测试、批次级与工人级抽样检验,最终获得了35,096个高质量的边界框标注。
特点
VisImages数据集的核心特点在于其细粒度、多层次的结构与丰富的标注信息。数据组织分为论文、图像和可视化三个层级,不仅包含论文元数据(标题、作者、会议、年份),还记录了每张图像的边界框、文字说明以及图像内每个可视化的类型和精确位置。该数据集的可视化类型分布相较于通用来源的数据集更为均衡,涵盖了从基础图表(如柱状图、散点图)到复杂系统界面(如多视图可视化分析系统)的广泛设计,尤其包含了大量新颖的可视化变体与组合。这种多样性使得VisImages成为评估机器学习模型泛化能力和鲁棒性的理想基准,其标注粒度与数量(超过35,000个实例)远超现有同类数据集,为文献分析和人工智能驱动的可视化研究提供了独特的数据支撑。
使用方法
VisImages数据集的使用方法灵活多样,可支撑多种研究场景。研究人员可直接利用其可视化类型和边界框标注,训练和评估可视化分类与目标定位模型,例如使用Faster R-CNN等算法进行可视化检测。数据集中的图像与文字说明配对,为可视化-文本翻译任务提供了天然资源。此外,通过VisImages Explorer交互式工具,用户能够按论文元数据、可视化类型和说明关键词进行筛选与探索,辅助文献综述与设计灵感挖掘。数据集以公开方式提供,并附有数据收集与处理的代码,便于研究者复现、扩展或将其与现有文献元数据(如vispubdata.org)结合,开展更深层次的可视化领域分析与跨学科研究。
背景与挑战
背景概述
在可视化研究领域,学术出版物中的图像承载着丰富的视觉与语义信息,如新颖的可视化设计模式与系统框架。然而,现有数据集多来源于网络或自动生成的简单图表,缺乏对学术出版物中复杂、创新设计的系统标注,限制了文献分析与人工智能驱动的可视化研究(AI4VIS)的发展。为填补这一空白,浙江大学、香港科技大学及微软亚洲研究院的研究人员于2022年构建了VisImages数据集。该数据集从1996年至2018年间IEEE InfoVis与VAST会议的1,397篇论文中,收集了12,267张图像及其标题,并基于综合可视化分类体系,为35,096个可视化元素提供了细粒度的类别与边界框标注。VisImages不仅为可视化文献分析提供了全新维度,还成为训练和评估可视化分类、定位等AI模型的基准,显著推动了领域知识的深化与AI4VIS的应用拓展。
当前挑战
VisImages的构建面临三大核心挑战。首先,学术出版物中的可视化设计高度多样化,包括新颖的图形符号、现有图表的变体及复杂系统界面,而现有分类体系难以全面覆盖,且标注需要深厚的可视化专业知识。其次,图像内可视化元素布局复杂,如多个图表共存、重叠或相互连接,使得精准定位其边界框变得困难且耗时。最后,标注质量难以保障,由于标注者知识背景差异及缺乏绝对真值,如何有效解决标注冲突、减少主观偏差成为关键。为此,研究团队采用了基于综合分类体系的专家标注、多数投票机制、金标准测试及抽样检验等多重质量控制措施,确保了数据集的高可靠性与实用性。
常用场景
经典使用场景
在可视化研究领域,VisImages数据集常被用于文献分析与可视化设计模式的探索。借助该数据集,研究者能够系统性地梳理IEEE InfoVis与VAST会议中22年间发表的12,267张图像及其对应的35,096个可视化元素边界框,深入剖析不同可视化类型在学术出版物中的演变趋势与组合规律。例如,通过内置的VisImages Explorer交互式工具,用户可以按年份、会议、作者或可视化子类型进行灵活筛选,直观观察柱状图、散点图、热力图等常见图表的使用频率变化,从而揭示领域内研究焦点的迁移与新兴可视化范式的涌现。
衍生相关工作
VisImages数据集催生了一系列具有深远影响的衍生研究工作。在可视化分类方面,研究者基于该数据集对比了ResNet、VGG等主流卷积神经网络与基于SVG特征的传统分类方法(如决策树)的性能差异,发现CNN在学术图表上的表现并非最优,从而引发了对可视化感知任务中模型选择的深入思考。在目标定位领域,利用VisImages训练的检测模型成功实现了对视觉分析系统界面的自动分解,为后续的多视图可视化组合模式分析(如MV Dataset相关工作)与可视化语法逆向工程提供了关键技术支撑。此外,该数据集还启发了可视化-文本翻译、可视化推荐等前沿研究方向,其中标注丰富的图像与图注自然构成了训练图像描述生成模型的高质量语料库,为智能可视化叙事开辟了新的可能性。
数据集最近研究
最新研究方向
在可视化研究领域,图像数据中蕴含的丰富视觉与语义信息正逐渐成为推动文献分析与人工智能驱动可视化(AI4VIS)发展的关键资源。VisImages数据集从IEEE InfoVis与VAST会议论文中系统收集了12,267张图像及35,096个精细标注的可视化实例,构建了涵盖34种可视化子类型的多层次标注体系。该数据集的前沿研究方向聚焦于利用细粒度标注训练可视化分类与目标检测模型,以应对学术出版物中复杂布局与创新设计的挑战。同时,VisImages支持跨年度可视化演变分析、多视图系统反向工程等热点任务,为评估模型泛化性与鲁棒性提供了独特基准。其深远意义在于弥合了学术可视化设计与AI模型之间的鸿沟,推动文献计量学从元数据层面迈向图像语义层面的深度挖掘,并为自动化可视化推荐与文本-图像翻译开辟了新的研究路径。
相关研究论文
- 1VisImages: A Fine-Grained Expert-Annotated Visualization Dataset浙江大学CAD&CG国家重点实验室 · 2022年
以上内容由遇见数据集搜集并总结生成


