Danbnyn/Bloomberg_Financial_News
收藏Hugging Face2024-06-18 更新2024-06-29 收录
下载链接:
https://hf-mirror.com/datasets/Danbnyn/Bloomberg_Financial_News
下载链接
链接失效反馈官方服务:
资源简介:
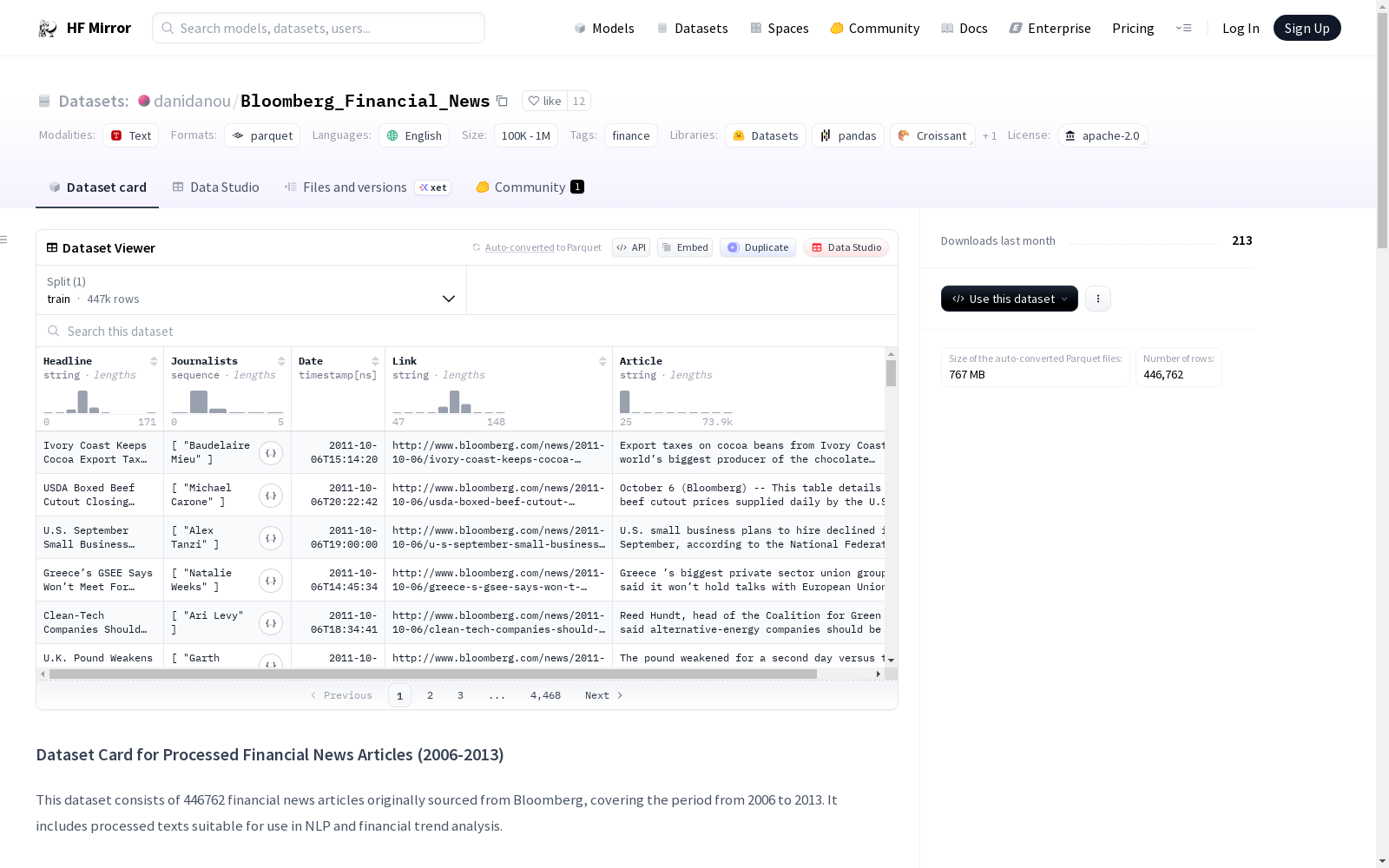
该数据集包含从2006年到2013年期间从Bloomberg收集的446762篇英文金融新闻文章,适用于自然语言处理任务和金融趋势分析。数据集由Dan Benayoun整理和分享,使用Apache-2.0许可证。数据集的结构包括标题、记者、日期、链接和文章内容等字段,但没有标准的数据分割。数据集旨在帮助研究人员和开发者分析多年来的金融新闻趋势和模式,但不应用于实时金融决策或交易。数据集反映了Bloomberg报道风格和特定时期地缘政治对金融报道的潜在偏见。
该数据集包含从2006年到2013年期间从Bloomberg收集的446762篇英文金融新闻文章,适用于自然语言处理任务和金融趋势分析。数据集由Dan Benayoun整理和分享,使用Apache-2.0许可证。数据集的结构包括标题、记者、日期、链接和文章内容等字段,但没有标准的数据分割。数据集旨在帮助研究人员和开发者分析多年来的金融新闻趋势和模式,但不应用于实时金融决策或交易。数据集反映了Bloomberg报道风格和特定时期地缘政治对金融报道的潜在偏见。
提供机构:
Danbnyn
原始信息汇总
数据集卡片:Processed Financial News Articles (2006-2013)
数据集描述
- 数据集名称: Processed Financial News Articles (2006-2013)
- 数据集来源: Bloomberg
- 数据集时间范围: 2006年至2013年
- 数据集大小: 446762篇金融新闻文章
- 语言: 英语
- 许可证: Apache-2.0
- 数据集用途: 自然语言处理任务、金融分析、趋势检测
- 数据集创建者: Dan Benayoun
数据集结构
数据实例
- 字段:
Headline,Journalists,Date,Link,Article
数据分割
- 分割: 未进行标准训练、验证或测试分割
数据集创建
数据收集与处理
- 数据来源: 从Bloomberg网站抓取并处理
- 数据生产者: Bloomberg的记者和金融分析师
数据注释
- 敏感信息: 包含个人和敏感信息,如人名、公司名和可能的财务数据
偏见、风险与限制
- 偏见: 数据集反映Bloomberg报道风格和特定时期地缘政治影响的潜在偏见
- 风险: 不应用于实时金融决策或交易
引用
bibtex @misc{processed_bloomberg_financial_news_2006_2013, author = {Dan Benayoun}, title = {Processed Dataset of Financial News Articles from Bloomberg (2006-2013)}, year = {2024}, publisher = {HuggingFace}, } @misc{BloombergReutersDataset2015, author = {Philippe Remy, Xiao Ding}, title = {Financial News Dataset from Bloomberg and Reuters}, year = {2015}, publisher = {GitHub}, journal = {GitHub repository}, howpublished = {url{https://github.com/philipperemy/financial-news-dataset}} }
搜集汇总
数据集介绍
构建方式
在金融信息分析领域,高质量的数据集是支撑自然语言处理研究的关键。本数据集通过系统化采集与处理流程构建,原始文本源自彭博社在2006年至2013年间发布的金融新闻。数据收集过程涉及网络爬取技术,随后对文章进行了清洗与结构化处理,移除了无关的格式标记,并保留了标题、作者、日期、链接及正文等核心字段,从而形成适用于机器学习任务的规范化文本集合。
特点
该数据集涵盖了近四十五万篇英文金融新闻,时间跨度长达八年,为研究金融市场的长期趋势与事件演化提供了丰富素材。其内容深度聚焦于全球财经动态,包含公司财报、市场波动、政策解读等多维度信息,且经过预处理,可直接应用于文本挖掘与情感分析。值得注意的是,数据反映了特定历史时期的媒体报道特点,可能存在与当时经济环境相关的表述倾向,使用时应予以考量。
使用方法
研究人员可将本数据集用于训练自然语言处理模型,尤其适合金融领域的情感分析、事件检测与趋势预测等任务。在实际应用中,用户需自行划分训练集、验证集与测试集,并注意数据的历史局限性,避免将其用于实时交易决策。借助该数据集,学者能够深入探索新闻文本与金融市场波动之间的关联,推动计算金融学的前沿发展。
背景与挑战
背景概述
在金融信息学与自然语言处理交叉领域,历史性新闻文本的积累为量化分析与趋势预测提供了关键语料基础。Danbnyn/Bloomberg_Financial_News数据集由研究员Dan Benayoun于2024年整理并发布,其核心源于2006年至2013年间彭博社发布的金融新闻报道,涵盖逾44万篇经过预处理的英文文章。该数据集的构建旨在支持学术界与工业界深入探索金融文本中的语义模式、情感倾向及事件关联性,尤其为跨周期金融舆情分析、市场情绪建模以及时序事件检测等研究提供了标准化、规模化的实证资源,显著推动了计算金融学与文本挖掘技术的融合创新。
当前挑战
该数据集致力于应对金融领域文本理解的多重复杂性挑战,其首要难题在于如何从非结构化的新闻内容中精准提取与市场动态紧密相关的语义信号,例如企业事件、政策变动及投资者情绪等,这对模型的领域适应性与上下文推理能力提出了较高要求。在构建过程中,数据采集与处理亦面临显著障碍:原始文本需经过清洗、去重与格式标准化,以消除媒体特有的报道偏差与时代性政治经济影响;同时,数据涵盖大量敏感信息如人名、机构及财务数据,如何在保障隐私合规的前提下维持语料的完整性与可用性,成为数据集构建中的关键平衡点。
常用场景
经典使用场景
在金融自然语言处理领域,Bloomberg Financial News数据集为研究者提供了丰富的文本资源,其经典使用场景聚焦于金融新闻的情感分析与事件检测。通过分析2006年至2013年间超过44万篇新闻文章,模型能够识别市场情绪波动与关键财经事件,如企业并购或政策发布,从而揭示新闻文本与金融市场动态之间的隐含关联。这一场景常被用于构建时序情感指数,为量化金融研究提供语言层面的数据支撑。
衍生相关工作
围绕该数据集衍生的经典工作包括基于深度学习的金融新闻情感分析模型,如采用BERT变体进行细粒度情绪分类的研究。同时,它催生了多项事件抽取与因果关系探测的算法,例如从新闻流中识别盈利预警或政策变动事件。这些工作进一步拓展至跨模态分析,结合股价序列与新闻文本,推动了可解释性金融人工智能方法的发展。
数据集最近研究
最新研究方向
在金融科技与自然语言处理的交叉领域,Danbnyn/Bloomberg_Financial_News数据集作为涵盖2006至2013年期间的大规模金融新闻语料,正推动着前沿研究的深化。当前研究聚焦于利用该数据集进行金融市场情绪的动态建模,结合深度学习技术如Transformer架构,以捕捉新闻文本中的隐含情感波动与宏观经济事件的关联性。热点方向包括基于时序分析的金融风险预警系统开发,以及跨语言金融事件检测模型的构建,旨在提升对市场异常波动的预测精度。这些研究不仅强化了金融信息抽取的自动化能力,也为量化投资策略提供了数据驱动的理论支撑,在金融智能决策领域具有显著的实践意义。
以上内容由遇见数据集搜集并总结生成


