Press-and-Plot
收藏Hugging Face2025-10-27 更新2025-10-28 收录
下载链接:
https://huggingface.co/datasets/chcaa/Press-and-Plot
下载链接
链接失效反馈官方服务:
资源简介:
Press&Plot是一个包含29个丹麦报纸故事(1816-1832年)的精选集合,包括单篇和多篇小说。这些故事经过人工检查、清洗和分类,供研究使用。数据集包含短篇小说、传记、游记和爱情故事等多个类别。
提供机构:
Center for Humanities Computing Aarhus
创建时间:
2025-10-27
原始信息汇总
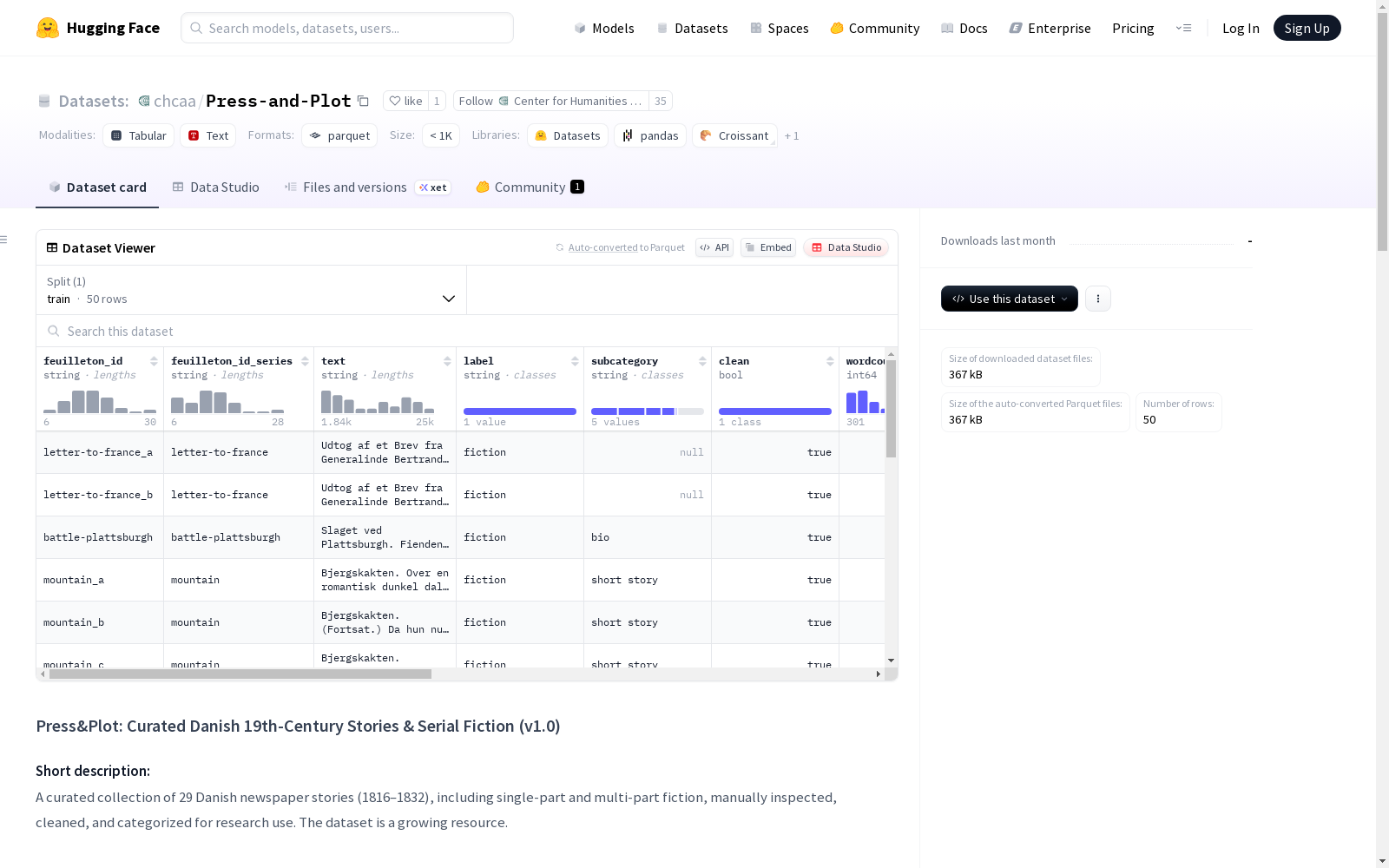
Press&Plot 数据集概述
数据集基本信息
- 数据集名称: Press&Plot: Curated Danish 19th-Century Stories & Serial Fiction (v1.0)
- 简短描述: 包含29个丹麦报纸故事(1816-1832年)的精选集合,包括单部分和多部分小说,经过人工检查、清理和分类,供研究使用
- 语言: 丹麦语(dan),来自18世纪和19世纪
- 许可证: 公共领域(CC0)
- 版本: v1.0
数据规模
- 故事数量: 29个(单部分和多部分叙事)
- 文章数量: 50篇(按连载ID分组)
- 类别数量: 6个
- 训练集大小: 50个样本,585,442字节
数据特征结构
| 特征名称 | 数据类型 | 描述 |
|---|---|---|
| feuilleton_id | string | 每期唯一标识符 |
| feuilleton_id_series | string | 系列/故事ID |
| text | string | 每期完整文本 |
| label | string | 任务分配的标签,区分报纸中的小说和非小说 |
| subcategory | string | 4个子类别之一 |
| clean | bool | 是否已进行手动清理 |
| wordcount/part | int64 | 部分的字数统计 |
| wordcount/whole | int64 | 完整系列的字数统计 |
| date | string | 日期 |
| author | string | 作者 |
| original_language | string | 原文语言(如果已知) |
| cliffhanger | float64 | 部分是否包含悬念 |
| feuilleton_name | string | 原始标题 |
| complete | string | 部分是否缺失 |
数据类别
- 主要类别: 短篇小说(普通小说)、传记、游记、爱情故事
- 子类别: 6个具体分类
数据来源与处理
- 策划方: 奥胡斯大学人文计算中心GoldenMatrix
- 处理方: 奥尔堡大学ENO
- 上传者: Pascale Feldkamp
- 选择方法: 从小说分类器的高置信度预测中选择
- 处理流程: 人工检查、跨期分组、拼写和格式清理
引用信息
- 论文待发表
- 引用信息待定
搜集汇总
数据集介绍
构建方式
在数字人文研究领域,Press-and-Plot数据集通过系统化流程构建而成。其素材源自丹麦19世纪报纸中经虚构作品分类器高置信度预测的文本,随后进行人工核查与跨期次归类,确保叙事连贯性。数据清理阶段着重修正历史文献中常见的拼写变异与格式不一致问题,最终形成包含29个独立故事的标准化语料库。
特点
该数据集凸显出多维度标注的学术价值,每个文本单元均配备层级化分类标签与元数据。除基础的小说/非小说分类外,还细化至传记、游记、爱情故事等子类别,并创新性地引入悬念标记指标。通过连载标识符与完整度字段,研究者可追溯多部作品的分期发表脉络,为叙事结构演化研究提供实证基础。
使用方法
利用现代自然语言处理工具链,研究者可通过HuggingFace平台直接加载数据集至Python环境。支持转换为pandas DataFrame格式后,可结合词频统计与时间序列分析,探索19世纪连载小说的叙事模式演变。其结构化字段设计特别适合计算文学研究,如通过悬念指标量化叙事张力,或基于作者字段进行风格计量学分析。
背景与挑战
背景概述
数字人文研究领域日益重视对历史文献的系统性挖掘与分析,Press-and-Plot数据集由奥胡斯大学人文计算中心和奥尔堡大学研究团队于2024年联合构建,聚焦19世纪丹麦报纸中的连载小说与短篇叙事作品。该数据集通过人工标注与分类,系统收录了1816至1832年间29部叙事作品的50个文本单元,涵盖传记、游记、爱情故事等六类文学体裁,为研究北欧浪漫主义时期大众文学传播与报刊出版生态提供了结构化数据支撑。
当前挑战
在历史文献数字化进程中,该数据集需解决19世纪丹麦语拼写变异与印刷错误的文本清洗难题,同时面临连载叙事中章节断裂与跨期追踪的完整性校验挑战。构建过程中需通过多轮人工校验解决原始报刊扫描件的字符识别误差,并建立系列作品关联模型以还原碎片化出版形态下的叙事逻辑,这对数字人文领域的多模态文献重构方法提出了更高要求。
常用场景
经典使用场景
在数字人文领域,Press-and-Plot数据集为研究19世纪丹麦报纸连载小说提供了珍贵素材。其经典使用场景聚焦于文学风格演变分析,学者们通过文本特征如词频统计、连载结构及悬念设置模式,深入探索这一时期叙事艺术的流变规律。
衍生相关工作
基于该数据集衍生的经典研究包括跨媒介叙事比较分析,学者通过对比报纸连载与单行本小说的文本特征,揭示了早期大众传媒的文学改编规律。后续工作还拓展至多语言虚构文学谱系建构,为北欧文学研究开辟了新维度。
数据集最近研究
最新研究方向
在数字人文领域,Press-and-Plot数据集为19世纪丹麦报刊小说研究开辟了新路径。当前前沿聚焦于利用多模态分析技术探索连载小说的叙事结构演化,特别是通过cliffhanger标记研究悬疑机制的文本特征。该数据集与欧洲数字图书馆计划形成联动,推动了对非经典文学遗产的挖掘,其精细标注的文本单元为跨语言比较研究提供了基准。这些进展不仅深化了我们对早期大众传媒叙事模式的理解,更为文化遗产的数字化重构奠定了方法论基础。
以上内容由遇见数据集搜集并总结生成


