MicroVQA
收藏arXiv2025-03-18 更新2025-03-19 收录
下载链接:
https://huggingface.co/datasets/jmhb/microvqa
下载链接
链接失效反馈官方服务:
资源简介:
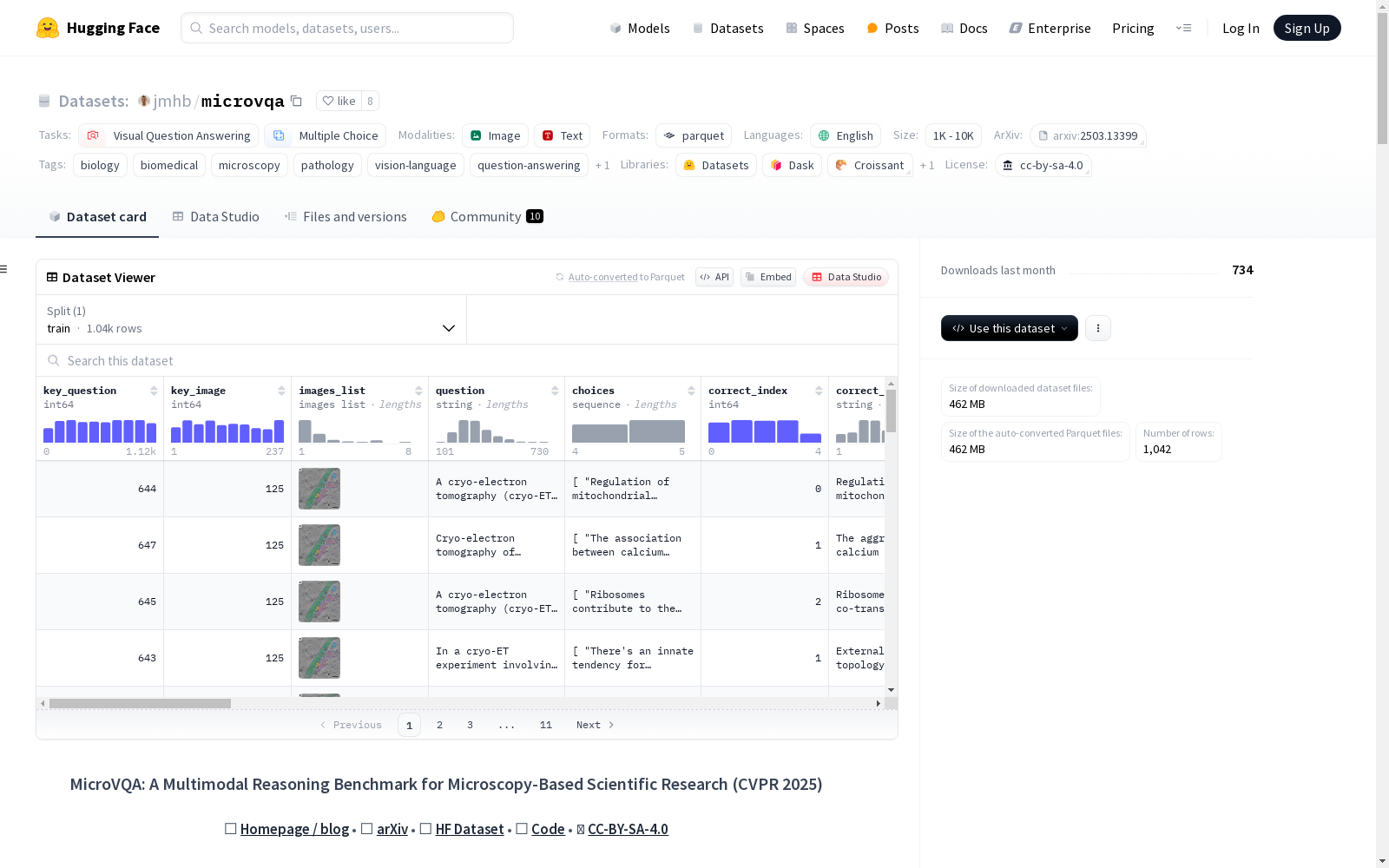
MicroVQA是一个针对生物显微镜学领域视觉问答的基准数据集,由斯坦福大学等多个研究机构的生物专家手工创建了1042个视觉问答样本。数据集中的问题涵盖了专家图像理解、假设生成和实验提议三个关键的科学探究任务,旨在评估多模态大型语言模型在科学研究中的推理能力。数据集的问题和答案都是由专家编写的,涉及从细胞形态到技术成像挑战等多个方面,使用了多种显微镜模态,覆盖了从组织到原子级别的不同尺度,并以人类和鼠标等与人类生物学和医学相关的研究为主。
MicroVQA is a benchmark dataset for visual question answering (VQA) in the field of biological microscopy. It contains 1042 manually curated visual question answering samples created by biological experts from multiple research institutions including Stanford University. The questions in the dataset cover three core scientific inquiry tasks: expert image understanding, hypothesis generation, and experimental proposal, aiming to evaluate the reasoning capabilities of multimodal large language models (LLMs) in scientific research. Both the questions and answers in the dataset are expert-written, covering various aspects from cell morphology to technical imaging challenges. It utilizes multiple microscopy modalities, spans scales ranging from tissue to atomic-level, and primarily focuses on research related to human biology and medicine, such as studies on humans and mice.
提供机构:
斯坦福大学
创建时间:
2025-03-18
搜集汇总
数据集介绍
构建方式
MicroVQA数据集的构建过程采用了专家驱动的多阶段方法。首先,生物学专家手动创建了1,042个视觉问答(VQA)样本,每个样本均基于真实的显微镜图像和实验背景。随后,通过两阶段的流程将原始问题转化为多项选择题(MCQ)。第一阶段使用优化的LLM提示将问答对格式化为MCQ,第二阶段则通过基于代理的‘RefineBot’系统进一步优化问题,消除语言捷径,确保问题真正测试科学推理能力。
特点
MicroVQA数据集的特点在于其专注于生物显微镜领域的高阶推理任务,涵盖了专家图像理解、假设生成和实验设计三个关键任务。数据集包含多种显微镜模态(如荧光、电子显微镜)和生物尺度(组织、细胞、亚细胞、原子),确保了问题的多样性和科学相关性。每个问题均由专家精心设计,确保其难度和复杂性符合真实科学研究的需求。
使用方法
MicroVQA数据集的使用方法主要包括评估多模态大语言模型(MLLMs)在生物显微镜图像上的推理能力。用户可以通过数据集中的多项选择题测试模型在图像理解、假设生成和实验设计任务中的表现。此外,数据集还支持对模型错误的详细分析,帮助研究人员识别模型在视觉推理和知识整合方面的不足,从而推动AI在生物医学研究中的应用。
背景与挑战
背景概述
MicroVQA数据集由斯坦福大学等机构的研究团队于2025年创建,旨在解决生物显微镜领域中的多模态推理问题。该数据集由生物学家精心设计,包含1,042个多选题,涵盖显微镜图像的专家理解、假设生成和实验设计等关键任务。MicroVQA的推出填补了现有多模态推理基准在科学研究级别任务上的空白,推动了AI在生物医学研究中的应用。其核心研究问题在于如何通过视觉问答(VQA)评估模型在复杂科学实验中的推理能力,尤其是在显微镜图像分析中的应用。该数据集对生物医学领域的影响力显著,为AI辅助科学研究提供了重要的评估工具。
当前挑战
MicroVQA数据集面临的挑战主要体现在两个方面。首先,其解决的领域问题——显微镜图像的多模态推理——要求模型不仅具备图像识别能力,还需结合实验背景进行复杂的推理。现有模型在处理此类任务时表现不佳,尤其是在假设生成和实验设计等高阶推理任务上。其次,数据集的构建过程中也面临诸多挑战。例如,如何确保多选题的设计不依赖于语言捷径,而是真正测试模型的多模态推理能力。为此,研究团队开发了两阶段的多选题生成流程,包括优化的大语言模型提示和基于代理的RefineBot系统,以消除语言捷径并提高问题的难度。此外,数据集的多样性和专家标注的高成本也是构建过程中的主要挑战。
常用场景
经典使用场景
MicroVQA数据集主要用于评估多模态大语言模型(MLLMs)在生物显微镜图像分析中的推理能力。该数据集通过视觉问答(VQA)的形式,测试模型在专家图像理解、假设生成和实验设计等任务中的表现。每个问题均由生物学专家精心设计,确保问题能够反映真实的科学研究场景。
解决学术问题
MicroVQA解决了现有多模态推理基准在科学研究场景中的不足,尤其是针对显微镜图像的高级推理任务。通过提供1042个由专家设计的多选题,该数据集填补了现有基准在复杂多模态推理任务上的空白,推动了AI在生物医学研究中的应用。
衍生相关工作
MicroVQA的推出激发了相关领域的研究工作,尤其是在多模态推理和生物医学AI领域。基于该数据集,研究人员开发了新的多模态推理模型,并探索了如何将AI技术应用于显微镜图像分析、假设生成和实验设计等任务。此外,该数据集还为其他科学领域的多模态推理基准提供了参考。
以上内容由遇见数据集搜集并总结生成


