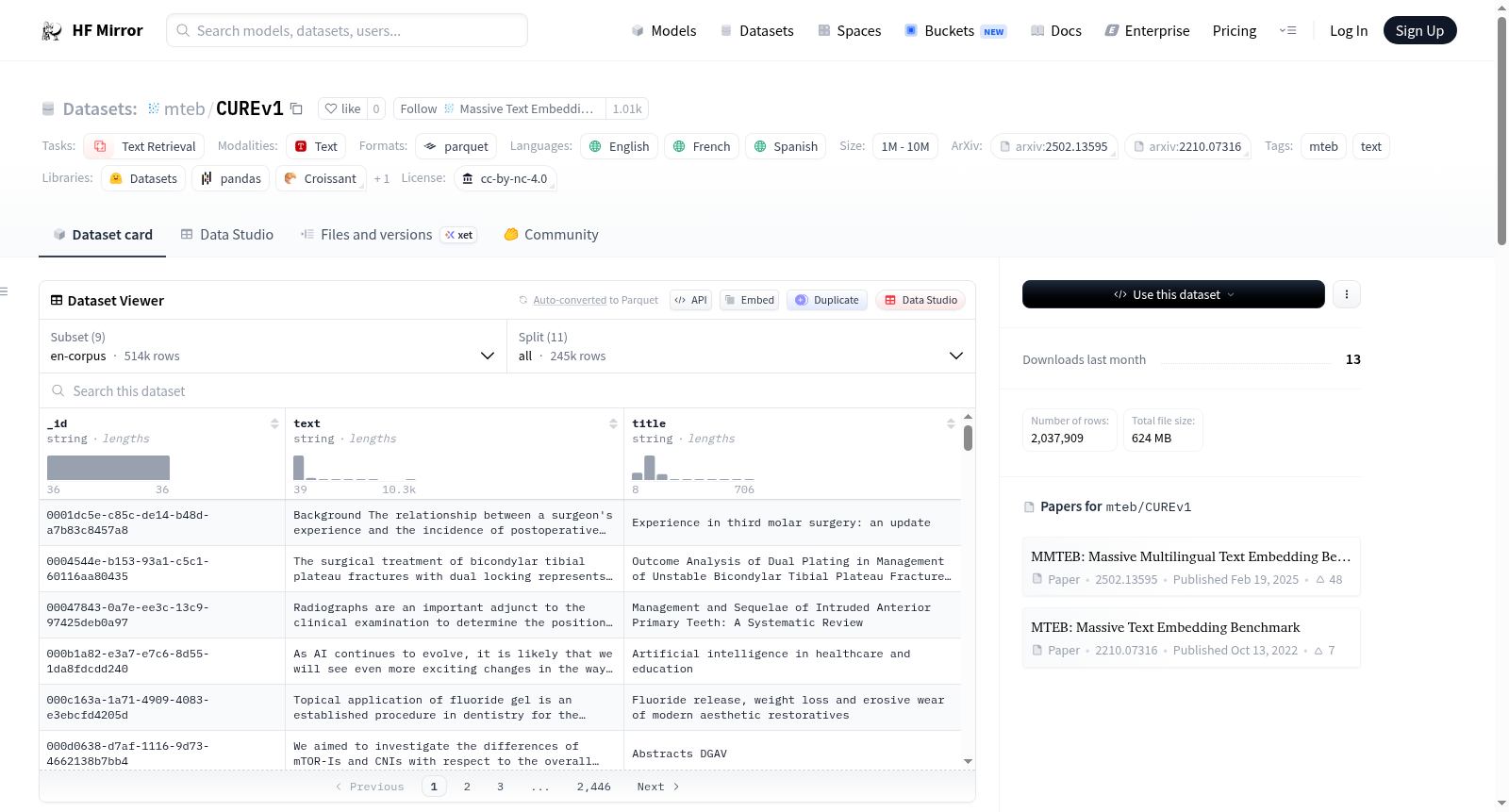
mteb/CUREv1
收藏Hugging Face2025-05-06 更新2025-05-31 收录
下载链接:
https://hf-mirror.com/datasets/mteb/CUREv1
下载链接
链接失效反馈官方服务:
资源简介:
CUREv1数据集是一个由医疗专业人员精心策划的查询-段落对集合,用于文本检索任务。该数据集是跨语言的,包括英语、法语和西班牙语,并具有专家注释。它被用于MTEB(大规模文本嵌入基准)任务,用于评估文本嵌入模型。数据集分为多个配置,包括en-corpus、en-qrels、en-queries、es-corpus、es-qrels、es-queries、fr-corpus、fr-qrels和fr-queries,每个配置包含不同特征和分割的数据。数据集包括不同领域的数据,如牙科和口腔健康、皮肤科、胃肠病学、遗传学、神经科学和神经病学、矫形外科、耳鼻喉科、整形外科、精神病学和心理学、肺病学。
CUREv1 is a collection of query-passage pairs curated by medical professionals for the task of text retrieval. It is multilingual, supporting English, French, and Spanish, and includes expert annotations. The dataset is part of the MTEB (Massive Text Embedding Benchmark) and is used to evaluate text embedding models. It is split into several configurations with different features and splits, such as en-corpus, en-qrels, en-queries, es-corpus, es-qrels, es-queries, fr-corpus, fr-qrels, and fr-queries. Each configuration includes data files for different splits like all, dentistry_and_oral_health, dermatology, gastroenterology, genetics, neuroscience_and_neurology, orthopedic_surgery, otorhinolaryngology, plastic_surgery, psychiatry_and_psychology, and pulmonology. The dataset is available in both binary and text formats, and it is used for benchmarking text embedding models across different medical disciplines and languages.
提供机构:
mteb
搜集汇总
数据集介绍
构建方式
在医学信息检索领域,构建高质量的数据集对于评估文本嵌入模型的性能至关重要。CUREv1数据集通过专家标注的方式精心构建,其核心内容涵盖了十个医学专业领域,包括牙科与口腔健康、皮肤病学、胃肠病学等。该数据集以多语言形式呈现,支持英语、西班牙语和法语,每种语言均包含独立的语料库、查询集及相关性标注。构建过程中,医学专业人员负责筛选和标注查询-段落对,确保了数据的专业性和准确性,为跨语言医学信息检索任务提供了坚实的基准。
特点
CUREv1数据集在医学文本嵌入基准中展现出鲜明的特点。其多语言架构覆盖了三种广泛使用的语言,为跨语言检索模型提供了丰富的测试环境。数据集按医学学科细致划分,每个学科包含独立的子集,便于针对特定领域进行深入分析。数据规模庞大,总语料库包含数十万条文本,查询集和相关性标注数量可观,确保了评估的统计可靠性。专家标注的引入进一步提升了数据的权威性,使其成为衡量模型在专业医学语境下性能的理想工具。
使用方法
利用CUREv1数据集进行模型评估,需遵循规范的流程。研究人员可通过MTEB框架便捷地加载该任务,使用预定义的评估器对嵌入模型进行测试。具体操作包括导入mteb库,获取CUREv1任务实例,并初始化评估器。随后,将待测模型传入评估器,执行自动化评估流程,从而获取模型在跨语言医学检索任务上的性能指标。这种方法不仅简化了评估步骤,还确保了结果的可比性和可重复性,有力支持了医学自然语言处理技术的迭代与优化。
背景与挑战
背景概述
在医学信息检索领域,专业文献的精准定位对临床决策与科研进展至关重要。CUREv1数据集由MTEB(Massive Text Embedding Benchmark)团队构建,旨在为跨语言医学文本检索提供基准。该数据集收录了涵盖牙科与口腔健康、皮肤病学、胃肠病学等十个医学专科的专家标注数据,并支持英语、西班牙语和法语三种语言。其核心研究问题聚焦于评估嵌入模型在复杂医学术语和多语言语境下的检索效能,为医学自然语言处理模型的开发与优化提供了关键资源。
当前挑战
CUREv1数据集所应对的领域挑战在于医学文本检索中专业术语的歧义性、多语言对齐的复杂性以及跨学科知识的融合需求。构建过程中的挑战包括医学文献的专家级标注需要高度专业的知识背景,确保不同语言版本间语义一致性的翻译与校对,以及处理大规模医学语料时面临的数据清洗与结构化难题。这些挑战共同塑造了数据集在推动医学信息检索技术发展中的独特价值。
常用场景
经典使用场景
在医学信息检索领域,CUREv1数据集以其专业标注和多语言特性,成为评估文本嵌入模型性能的经典基准。该数据集涵盖了牙科与口腔健康、皮肤病学、胃肠病学等十个医学专科,通过专家构建的查询-段落对,为模型提供了精准的语义匹配任务。研究人员通常利用该数据集,在多语言环境下测试模型对复杂医学术语的理解能力,从而推动跨语言医学检索技术的发展。
衍生相关工作
围绕CUREv1数据集,学术界衍生出一系列重要的研究工作。这些工作主要集中在多语言医学嵌入模型的优化与评估框架的拓展上。例如,部分研究利用该数据集探索了领域自适应技术在医学文本检索中的应用,另一些工作则基于其多语言特性,开发了新型的跨语言语义对齐算法,进一步丰富了医学自然语言处理的技术体系。
数据集最近研究
最新研究方向
在医学信息检索领域,CUREv1数据集凭借其多语言、多学科的专家标注特性,正成为评估跨语言文本嵌入模型性能的关键基准。随着全球医疗数据共享需求的增长,该数据集推动了多语言医学文本表示学习的前沿探索,研究焦点集中于提升模型在英语、法语和西班牙语间的语义对齐能力,以及针对牙科、皮肤科等细分专科的精准检索效果。这一趋势与当前多语言大模型在专业领域的应用热潮相呼应,为构建泛化性强、可解释性高的临床决策支持系统提供了重要数据支撑,促进了医学人工智能的国际化与专业化发展。
以上内容由遇见数据集搜集并总结生成


