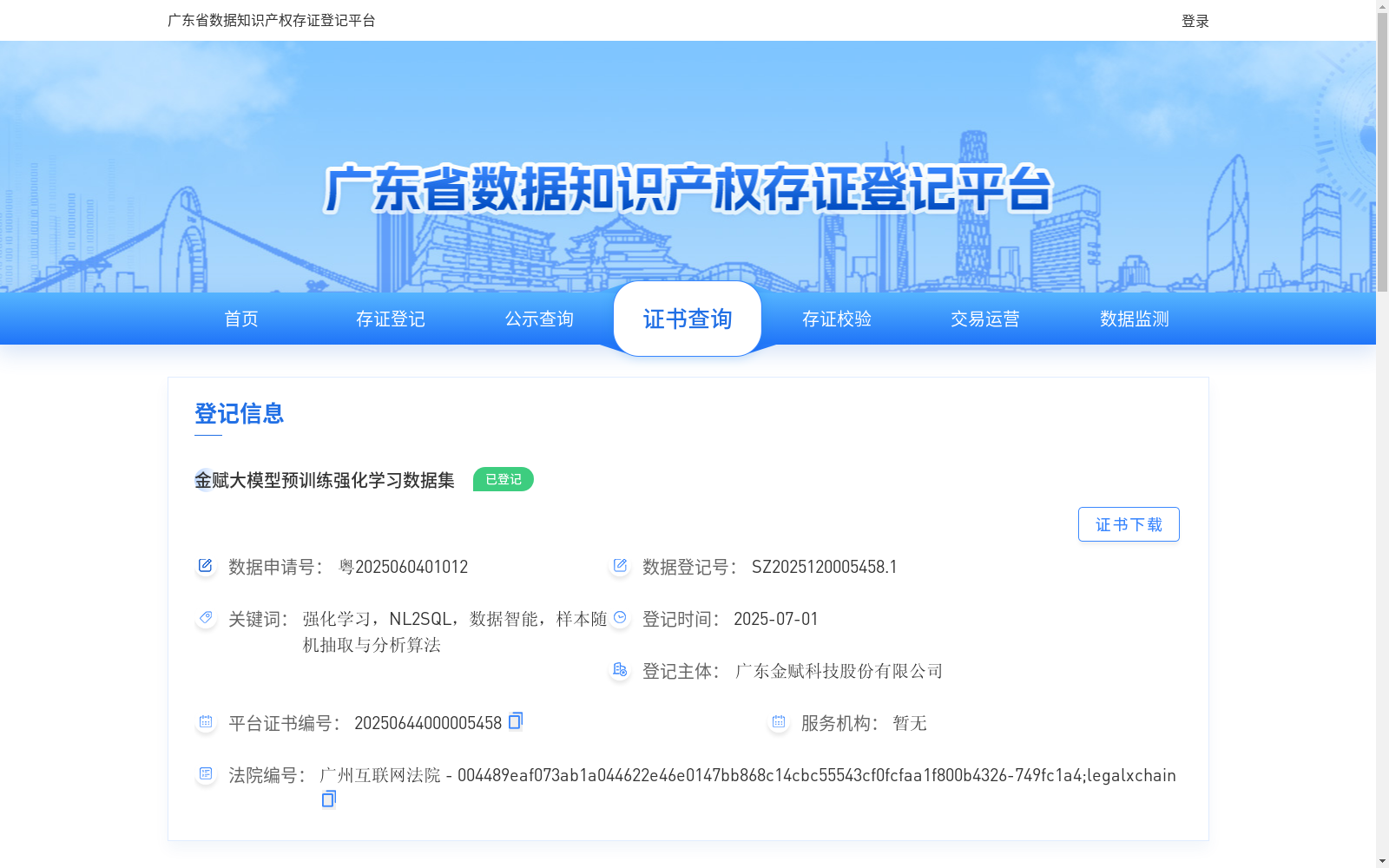
金赋大模型预训练强化学习数据集
收藏广东省数据知识产权存证登记平台2025-06-05 更新2025-07-05 收录
下载链接:
https://data.gpic.gd.cn/dataStorage/credentialInfo.jhtml?no=20250644000005458
下载链接
链接失效反馈官方服务:
资源简介:
本数据集主要包括以下字段,id, questions, query, db_name, shcema。数据id为数据主键,用于数据查询。Questions为模型训练问题,主要用于训练中自然语言处理部分,本字段为字符串,作为问题的自然语言文字部分。Query 为模型训练文字问题对应的 SQL 代码,db_name 为训练题对应的数据库。 schema 用于解释数据库的数据结构。模型通过提取模型训练问题(Questions)生成SQL代码,样本检验通过模型生成代码和Query评估样本相关性和学习影响度。然后通过db_name选择高质量的数据进行模型强化学习。
提供机构:
广东金赋科技股份有限公司
创建时间:
2025-06-05
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个专注于强化学习的大模型预训练数据集,包含约44万条数据,主要用于提升7B和32B模型的NL2SQL能力,通过自然语言问题生成SQL查询。它采用创新的学习影响度量算法和样本随机抽取与分析算法,自动化筛选高质量样本,旨在优化强化学习训练过程,显著降低训练时间和硬件资源需求。
以上内容由遇见数据集搜集并总结生成


