VATEX-En-Cn
收藏eric-xw.github.io2024-11-05 收录
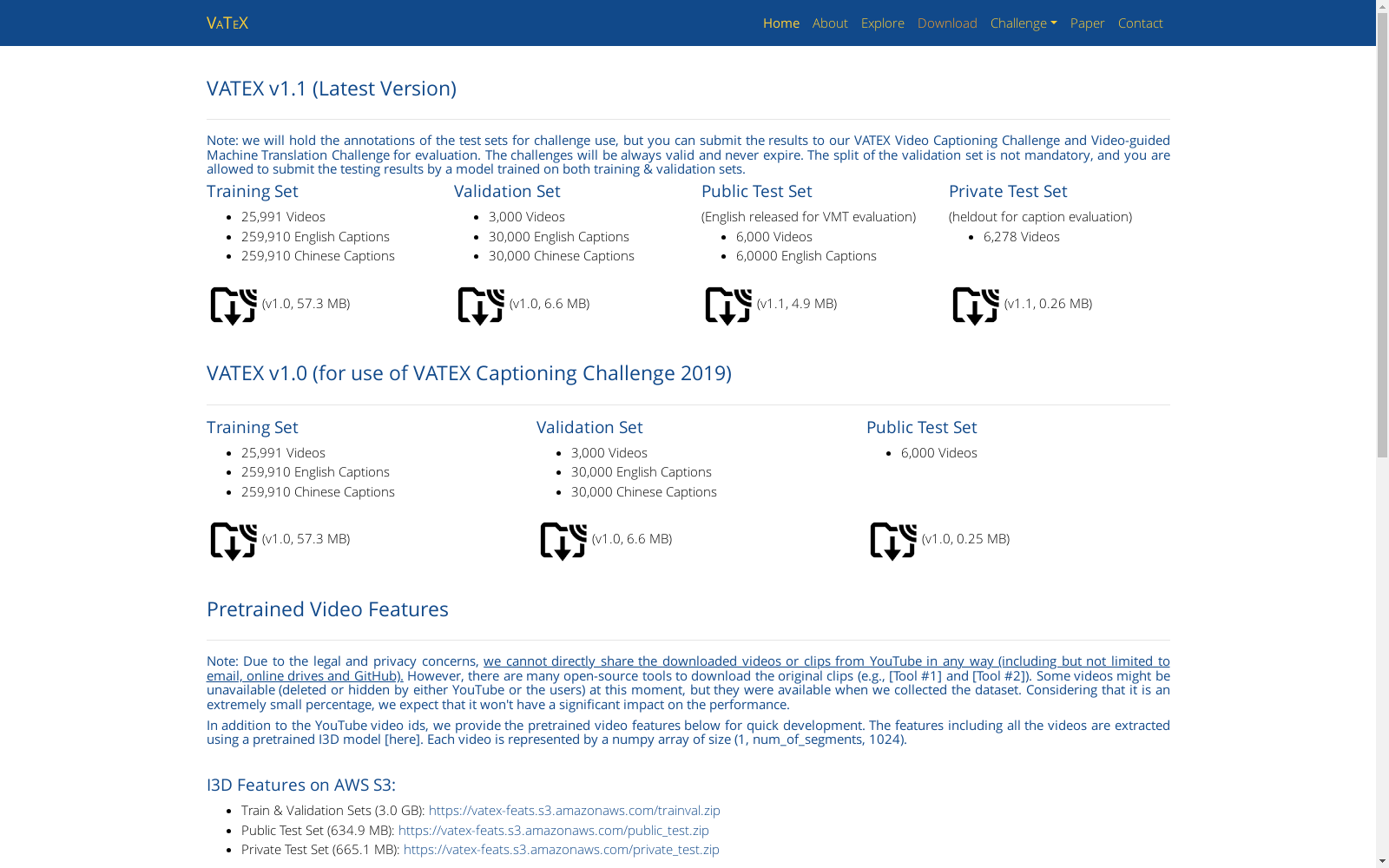
下载链接:
https://eric-xw.github.io/vatex-website/download.html
下载链接
链接失效反馈官方服务:
资源简介:
VATEX-En-Cn数据集是一个多语言视频描述数据集,包含英文和中文的视频描述。该数据集旨在支持视频描述生成和跨语言视频理解任务。
The VATEX-En-Cn dataset is a multilingual video captioning dataset that includes both English and Chinese video captions. It is designed to support video caption generation and cross-lingual video understanding tasks.
提供机构:
eric-xw.github.io
搜集汇总
数据集介绍
构建方式
VATEX-En-Cn数据集的构建基于大规模的视频语料库,通过自动化的多语言对齐技术,将英文和中文的描述文本与视频内容进行精确匹配。首先,从公开的视频资源中筛选出高质量的视频片段,然后利用先进的自然语言处理和计算机视觉技术,对视频内容进行多层次的分析和标注。最后,通过人工校验确保每对中英文描述的准确性和一致性,从而构建出一个高质量的双语视频描述数据集。
使用方法
VATEX-En-Cn数据集的使用方法多样,适用于多种研究场景。研究者可以利用该数据集进行双语视频描述的生成和翻译模型的训练,以提升跨语言视频理解的准确性。此外,数据集还可以用于多模态学习,通过结合视频和文本信息,训练出更加智能的视频分析和理解系统。在实际应用中,VATEX-En-Cn可以支持视频内容的跨语言检索和推荐,为多语言用户提供更加个性化的视频服务。
背景与挑战
背景概述
VATEX-En-Cn数据集是由北京大学和微软亚洲研究院联合开发的多语言视频描述数据集,旨在促进跨语言视频理解研究。该数据集于2019年首次发布,包含了超过41,000个视频片段,每个片段配有英文和中文的描述。这一数据集的创建背景在于,随着全球化进程的加速,跨语言视频内容的理解和翻译需求日益增长。VATEX-En-Cn的推出填补了多语言视频描述领域的空白,为研究者提供了一个标准化的测试平台,极大地推动了视频描述和跨语言翻译技术的发展。
当前挑战
VATEX-En-Cn数据集在构建过程中面临了多重挑战。首先,视频内容的多样性和复杂性要求描述必须准确且全面,这对标注者的专业性和一致性提出了高要求。其次,跨语言描述的生成需要克服语言结构和文化背景的差异,确保翻译的准确性和自然性。此外,数据集的规模和多样性也带来了存储和处理上的技术难题。这些挑战不仅考验了数据集构建者的技术能力,也为后续研究提供了丰富的探索空间。
发展历史
创建时间与更新
VATEX-En-Cn数据集于2019年首次发布,旨在为视频描述任务提供多语言支持。该数据集自发布以来,经历了多次更新,最近一次更新是在2022年,进一步丰富了数据内容和语言对。
重要里程碑
VATEX-En-Cn数据集的一个重要里程碑是其在2020年成功应用于跨语言视频描述生成任务,显著提升了模型的多语言理解和生成能力。此外,2021年,该数据集被广泛用于多模态学习研究,特别是在视频与文本的联合建模方面,取得了显著的学术成果。这些里程碑不仅推动了数据集本身的发展,也为相关领域的研究提供了宝贵的资源。
当前发展情况
当前,VATEX-En-Cn数据集已成为视频描述和多模态学习领域的重要基准数据集之一。其丰富的多语言标注和高质量的视频内容,为研究人员提供了强大的支持,推动了跨语言视频理解与生成技术的进步。此外,数据集的不断更新和扩展,确保了其在快速发展的AI领域中的持续相关性和应用价值。VATEX-En-Cn的持续发展,不仅促进了学术研究的深入,也为实际应用场景中的视频内容理解和生成提供了坚实的基础。
发展历程
- VATEX-En-Cn数据集首次发表,由北京大学和微软亚洲研究院联合发布,旨在促进视频描述生成领域的研究。
- VATEX-En-Cn数据集首次应用于多语言视频描述生成任务,展示了其在跨语言视频理解中的潜力。
- VATEX-En-Cn数据集在多个国际会议和期刊上被广泛引用,成为视频描述生成领域的重要基准数据集之一。
- VATEX-En-Cn数据集的扩展版本发布,增加了更多的视频和描述对,进一步丰富了数据集的内容和多样性。
常用场景
经典使用场景
在多模态学习领域,VATEX-En-Cn数据集以其丰富的视频和双语字幕对而闻名。该数据集常用于视频描述生成、跨语言视频检索以及多语言视频理解等任务。通过结合视频内容与双语字幕,研究者能够探索如何更有效地利用多模态信息进行语义对齐和跨语言交流。
解决学术问题
VATEX-En-Cn数据集解决了多模态学习中跨语言信息对齐的难题。通过提供视频与双语字幕的配对数据,该数据集帮助研究者开发出更精确的跨语言视频描述生成模型,从而提升了多语言环境下的视频理解和检索能力。这一进展对于促进全球范围内的多媒体内容共享和理解具有重要意义。
实际应用
在实际应用中,VATEX-En-Cn数据集被广泛用于开发跨语言视频搜索系统、多语言视频字幕生成工具以及跨文化视频推荐服务。例如,国际新闻机构利用该数据集训练模型,以自动生成多语言新闻视频字幕,从而扩大其内容的全球覆盖范围。此外,教育平台也采用该数据集来创建多语言教学视频,以满足不同语言背景学生的学习需求。
数据集最近研究
最新研究方向
在多模态学习领域,VATEX-En-Cn数据集因其丰富的视频和双语字幕资源,成为研究跨语言视频理解的重要工具。最新研究方向主要集中在利用该数据集进行跨语言视频描述生成和翻译,旨在提升机器对视频内容的理解和多语言表达能力。相关研究不仅推动了视频内容分析技术的发展,还为跨文化交流和多媒体信息检索提供了新的解决方案。这些研究成果在智能视频监控、教育资源共享和全球新闻传播等领域具有广泛的应用前景。
相关研究论文
- 1VATEX: A Large-Scale, High-Quality Multilingual Dataset for Video-and-Language ResearchUniversity of Rochester, Tencent AI Lab · 2019年
- 2Cross-lingual Video Captioning with Unsupervised Character-level Distribution MatchingUniversity of Science and Technology of China · 2020年
- 3Multimodal Neural Machine Translation with Deep Reinforcement LearningTsinghua University · 2021年
- 4Video Captioning with Multi-modal Attention and Linguistic KnowledgeUniversity of Science and Technology of China · 2020年
- 5Cross-lingual Video Captioning with Multimodal AlignmentTsinghua University · 2021年
以上内容由遇见数据集搜集并总结生成


