food-description-text
收藏官方服务:
资源简介:
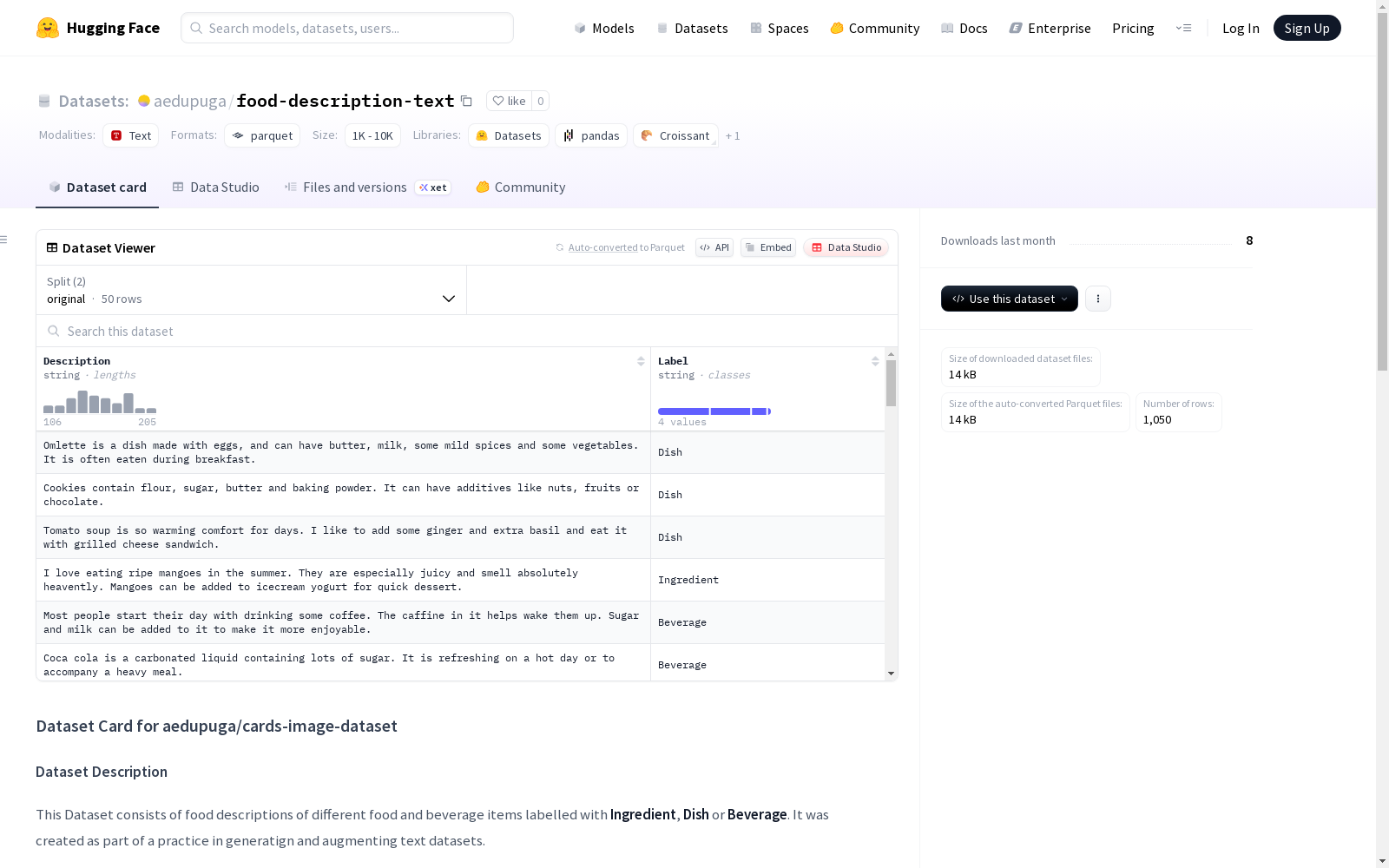
该数据集包含不同食物和饮料项目的描述,这些描述被标记为“原料”、“菜肴”或“饮料”。它是作为生成和增强文本数据集的实践的一部分而创建的。数据集包含两个部分:原始部分包含50个手写食物描述样本,增强部分包含通过增强技术生成的300个样本来扩展数据多样性和变化。每一行数据包括食物的文本描述和分类标签(菜肴、原料、饮料)。
创建时间:
2025-09-15
原始信息汇总
数据集概述
基本信息
- 数据集名称: aedupuga/food-description-text
- 创建者: Anuhya Edupuganti
- 创建目的: 用于文本数据集生成和增强的练习
数据集结构
- 特征列:
Description(string): 食物描述文本Label(string): 类别标签,包括Dish、Ingredient和Beverage
- 数据划分:
- original: 50个样本,包含手写食物描述
- augmented: 1000个样本,通过增强技术生成
技术细节
- 原始数据大小: 8,415字节
- 增强数据大小: 165,260字节
- 总数据集大小: 173,675字节
- 下载大小: 13,985字节
数据收集与处理
- 原始数据: 手写收集
- 增强方法: 回译技术
用途
- 训练和评估文本分类模型
- 文本数据集预处理实验
局限性
- 样本量小: 仅50个原始样本
- 合成增强: 可能无法准确描述真实食物
使用建议
- 主要用于分类方法练习
联系方式
- Anuhya Edupuganti (卡内基梅隆大学) - aedupuga@andrew.cmu.edu
搜集汇总
数据集介绍
构建方式
在食品文本描述数据集的构建过程中,原始数据通过人工手写方式收集了50条食品描述样本,涵盖食材、菜肴和饮品三个类别。随后采用回译技术进行数据增强,生成了1000条增强样本,有效扩展了数据多样性和规模,为文本分类任务提供了更丰富的训练资源。
特点
该数据集包含50条原始手写描述和1000条增强样本,每条数据均包含文本描述和对应的类别标签。其特点在于通过增强技术显著提升了数据多样性,同时保持了食材、菜肴、饮品三类标签体系的完整性,为自然语言处理模型提供了结构清晰的多类别文本分类基础。
使用方法
研究者可直接使用该数据集进行文本分类模型的训练与评估,原始集适用于基准测试,增强集则能有效提升模型泛化能力。建议采用预处理技术优化文本质量,重点关注三类标签的分布规律,适用于教学场景中的分类方法实践与研究验证。
背景与挑战
背景概述
食品描述文本数据集由卡内基梅隆大学的Anuhya Edupuganti创建,旨在探索食品文本分类任务的数据构建方法。该数据集聚焦于食品描述文本的多类别分类问题,涵盖原料、菜肴和饮料三大类别,为自然语言处理领域提供了专门针对食品领域的文本分类基准。通过手工标注与数据增强技术的结合,该数据集虽规模有限,却为研究者在食品文本分析领域的模型训练与评估提供了重要资源。
当前挑战
该数据集核心挑战在于解决食品文本分类中语义细粒度区分问题,例如区分'原料'与'菜肴'的语义边界。构建过程中面临原始样本稀缺的困境,仅50条手写描述需通过回译增强技术扩展至1000条样本,但合成数据可能引入描述失真风险,且领域专业性要求高,需确保增强后文本保持食品描述的真实性与一致性。
常用场景
经典使用场景
在食品文本分析领域,该数据集为研究者提供了标准化的分类基准,通过50个原始样本和1000个增强样本构建的文本描述,支持多类别分类任务的模型训练与验证。其经典应用场景包括食品描述文本的自动分类,将输入文本精准划分为食材、菜肴或饮料三大类别,为自然语言处理技术在食品领域的应用奠定数据基础。
实际应用
实际应用中,该数据集可服务于智能餐饮系统的菜单自动归类、食品电商平台的商品描述分类,以及营养分析应用的成分识别。通过自动化文本分类,能够提升食品行业信息管理的效率,辅助餐饮企业进行菜品数字化管理,并为消费者提供更精准的食品信息检索与推荐服务,具有明显的商业应用价值。
衍生相关工作
基于该数据集衍生的经典工作主要包括小样本文本增强技术的比较研究,以及轻量级文本分类模型的开发。相关研究探索了回译、同义词替换等增强策略在食品文本上的效果,并开发了适用于有限数据的高效分类器,这些工作为食品计算领域的文本处理提供了方法论参考,促进了领域适应性模型的研究进展。
以上内容由遇见数据集搜集并总结生成


