hateful_memes_fine_grained
收藏Hateful Memes Fine-Grained 数据集概述
基本信息
- 数据集名称:Hateful Memes Fine-Grained Dataset
- 维护者:Nils A. Herrmann
- 语言:英语
- 许可证:MIT
- 数据来源:基于 Hateful Memes 数据集构建
- 相关资源:
- 代码仓库:https://github.com/nils-herrmann/beyond_hate
- 预印本论文:https://arxiv.org/abs/2603.22985
数据集简介
该数据集是广泛使用的 Hateful Memes 数据集的细粒度扩展,旨在支持对有害多模态内容进行更细致的分析。原始数据集侧重于二元仇恨性分类,而此扩展引入了额外的注释维度,以更细粒度的级别捕捉不文明和不容忍内容。
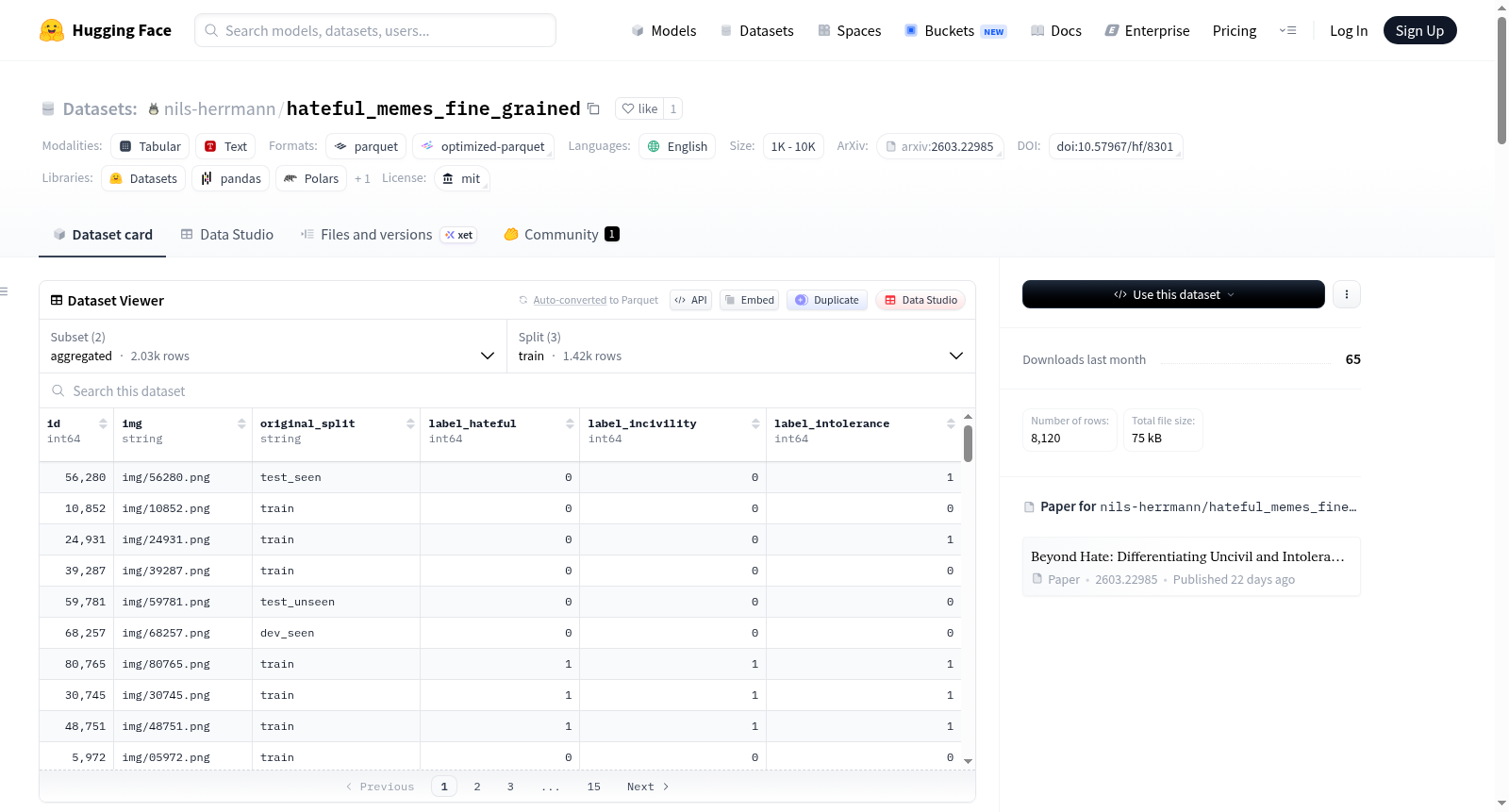
数据集包含 2,030 个模因(meme)的子集,每个模因由三位标注者独立标注。标注既提供个体标注者级别的数据,也提供二值化后的聚合多数投票标签。
数据集结构
数据集包含两个主要配置:
1. 聚合数据 (aggregated)
- 描述:包含二值化后的多数投票标签。
- 数据量:2,030 行(每个模因一行)。
- 特征:
id:模因标识符 (int64)img:图像文件名 (string)original_split:在原始数据集中的对应划分 (string)label_hateful:原始二元标签 (int64)label_incivility:多数投票后的二元标签 (int64)label_intolerance:多数投票后的二元标签 (int64)
- 数据划分与大小:
- 训练集:1,420 个样本,84,506 字节
- 验证集:203 个样本,12,080 字节
- 测试集:407 个样本,24,220 字节
- 总下载大小:38,974 字节
- 总数据集大小:120,806 字节
2. 标注级数据 (annotations)
- 描述:包含来自每位标注者的个体标注。
- 数据量:6,090 行(2,030 个样本 × 3 位标注者)。
- 特征:
id:模因标识符 (int64)annotator:标注者标识符 (string)label_hateful:原始二元标签 (int64)label_incivility:多类别标签(逗号分隔)(string)label_intolerance:多类别标签(逗号分隔)(string)
- 数据划分与大小:
- 训练集:6,090 个样本,234,632 字节
- 总下载大小:27,211 字节
- 总数据集大小:234,632 字节
预期用途
- 训练和评估多模态分类模型。
- 研究超越二元仇恨性的细粒度有害内容检测。
- 分析不文明(语气)与不容忍(内容)之间的区别。
- 评估内容审核系统中的偏见和公平性。
- 研究标注不一致性和不确定性建模。
超出范围的用途:不应在没有人工监督的情况下用于全自动审核系统。
数据集创建
动机
现有的多模态仇恨检测数据集主要关注二元标签,这掩盖了有害内容中的重要区别。创建此数据集旨在:
- 捕捉有害性的不同维度。
- 实现更可解释的模型行为。
- 支持标注模糊性和不一致性的研究。
- 为细粒度审核策略提供测试平台。
数据收集与处理
- 从 Hateful Memes 数据集中选择了 2,030 个模因的子集。
- 每个模因由三位标注者独立标注。
- 标注内容包括:
- 二元仇恨性
- 不文明类别(语气)
- 不容忍类别(内容)
- 通过以下方式计算聚合标签:
- 标签二值化
- 多数投票
标注者
- 2 位专家标注者:具有社会科学背景和传播学研究经验。
- 1 位经过培训的非专家标注者:具有计算机科学背景,接受了任务特定培训。
标注流程
- 每个模因由3 位标注者标注。
- 标注分两个阶段进行:
- 初始标注
- 审查/解决分歧(如适用)
偏见、风险与局限性
- 标注的主观性。
- 数据集规模有限(2,030 个样本)。
- 标注者因背景差异导致的偏见。
- 对有害内容解释的文化偏见。
- 模因的合成性质可能限制其在现实世界中的泛化能力。
引用信息
引用格式: Herrmann, N. A., Eder, T., He, J., & Groh, G. (2026). Beyond Hate: Differentiating Uncivil and Intolerant Speech in Multimodal Content Moderation (arXiv:2603.22985). arXiv. https://doi.org/10.48550/arXiv.2603.22985
BibTeX: bibtex @misc{herrmann2026hatedifferentiatinguncivilintolerant, title={Beyond Hate: Differentiating Uncivil and Intolerant Speech in Multimodal Content Moderation}, author={Nils A. Herrmann and Tobias Eder and Jingyi He and Georg Groh}, year={2026}, eprint={2603.22985}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2603.22985}, }