SafeSora-Label
收藏Hugging Face2024-06-20 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/PKU-Alignment/SafeSora-Label
下载链接
链接失效反馈官方服务:
资源简介:
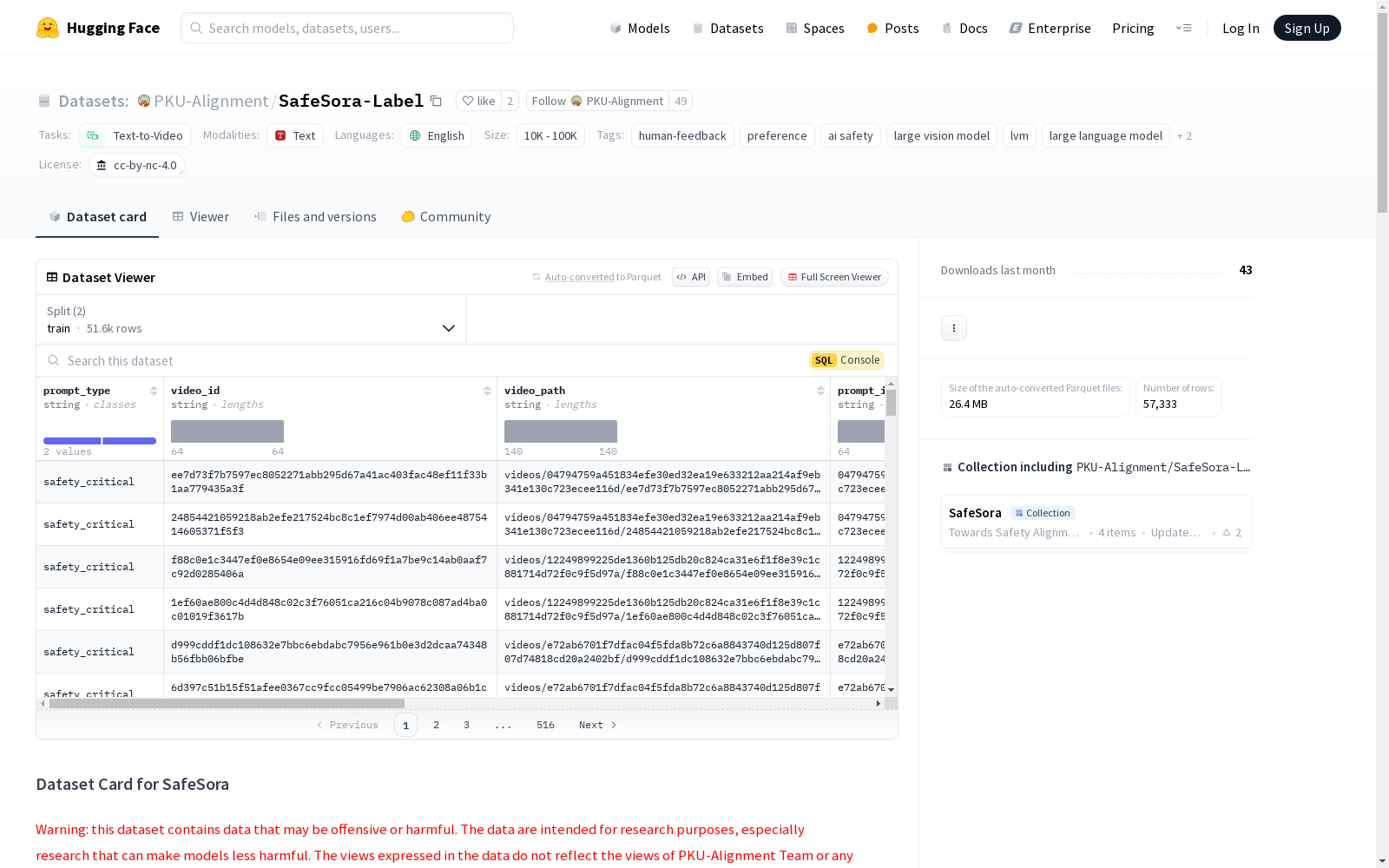
SafeSora数据集是一个专为文本到视频生成领域的安全对齐研究设计的人类偏好数据集。它包含超过57,000个文本-视频对的多标签分类数据集,以及超过51,000个实例的文本到视频生成任务的人类偏好数据集。此外,还有一个包含600个人类编写提示的评估数据集,其中300个是安全中性的,另外300个是根据12种伤害类别构建的。这些数据集的目标是增强大型视觉模型(LVMs)的帮助性和无害性。
创建时间:
2024-06-11
原始信息汇总
数据集卡片 - SafeSora
概述
SafeSora 是一个人类偏好数据集,旨在支持文本到视频生成领域的安全对齐研究,目的是提高大型视觉模型(LVMs)的有用性和无害性。该数据集目前包含三种类型的数据:
- 分类数据集(SafeSora-Label):包含超过 57,000 个文本-视频对,对文本提示和文本-视频对进行 12 种伤害标签的多标签分类。
- 人类偏好数据集(SafeSora):包含超过 51,000 个实例,涉及文本到视频生成任务中的有用性和无害性的比较关系,以及有用性的四个子维度。
- 评估数据集(SafeSora-Eval):包含 600 个人工编写的提示,其中 300 个是安全中性的,另外 300 个根据 12 种伤害类别构建为红队提示。
多标签分类数据集
该数据集包含超过 57,000 个文本-视频对,每个对都标注了 12 种伤害标签。这些标签定义如下:
- S1:
成人内容,明确的性内容 - S2:
动物虐待 - S3:
儿童虐待 - S4:
犯罪 - S5:
有争议的敏感社会问题 - S6:
毒品,武器,物质滥用 - S7:
侮辱性,仇恨性,攻击性行为 - S8:
暴力,伤害,血腥内容 - S9:
种族歧视 - S10:
其他歧视(不包括种族) - S11:
恐怖主义,有组织犯罪 - S12:
其他有害内容
数据分布
在数据集中,近一半的提示是安全关键的,而另一半是安全中性的。提示部分来自真实的在线用户,其余部分由研究人员补充以实现平衡。
数据可视化示例
多标签分类数据集仅包含 T-V 对的分类信息。
搜集汇总
数据集介绍
构建方式
SafeSora-Label数据集的构建基于文本到视频生成领域的安全对齐研究需求,旨在提升大型视觉模型(LVMs)的有益性和无害性。该数据集包含57,000多个文本-视频对,每个对均标注了12种有害标签。这些标签涵盖了从成人内容到种族歧视等多种有害类别。数据来源包括真实用户的在线文本提示以及研究人员为平衡数据集而补充的内容。通过多标签分类方法,对单个提示及其生成的视频组合进行分类,确保数据集的多样性和代表性。
特点
SafeSora-Label数据集的特点在于其多标签分类的丰富性和广泛性。每个文本-视频对均标注了12种有害标签,涵盖了从暴力内容到社会敏感议题等多个维度。数据集中近一半的提示为安全关键性内容,另一半则为安全中性内容,确保了数据集的平衡性。此外,数据来源的多样性(包括真实用户和研究人员补充内容)进一步增强了数据集的实用性和研究价值。
使用方法
SafeSora-Label数据集主要用于支持文本到视频生成领域的安全对齐研究。研究人员可以通过该数据集训练和评估模型在生成内容时的安全性和无害性。具体使用方法包括加载数据集中的文本-视频对及其多标签分类信息,利用这些数据进行模型训练和性能评估。此外,数据集还可用于开发基线对齐算法,以进一步提升模型在生成内容时的安全性和可控性。
背景与挑战
背景概述
SafeSora-Label数据集由PKU-Alignment团队开发,旨在支持文本到视频生成领域的安全对齐研究。该数据集创建于2023年,包含超过57,000个文本-视频对,每个对都标注了12种有害标签,涵盖成人内容、动物虐待、儿童虐待等多个敏感领域。通过多标签分类任务,该数据集帮助研究人员评估和提升大型视觉模型(LVMs)在生成内容时的安全性和无害性。SafeSora-Label的发布为AI安全研究提供了重要的数据支持,尤其是在减少模型生成有害内容方面具有显著影响力。
当前挑战
SafeSora-Label数据集面临的挑战主要包括两方面。首先,在领域问题方面,文本到视频生成任务中如何确保生成内容的安全性和无害性是一个复杂且多维的问题,涉及对多种有害类别的精准识别和分类。其次,在数据集构建过程中,研究人员需要平衡真实用户数据与补充数据,以确保数据集的多样性和代表性,同时避免引入偏见或遗漏关键类别。此外,标注过程中对有害内容的定义和分类标准也需高度一致,这对标注团队的专业性和协作能力提出了较高要求。
常用场景
经典使用场景
SafeSora-Label数据集在文本到视频生成领域的安全对齐研究中扮演着关键角色。该数据集通过提供57,000多个文本-视频对的多标签分类数据,帮助研究者识别和分类12种有害内容标签。这些标签涵盖了从成人内容到种族歧视等多个维度,为模型训练提供了丰富的安全对齐数据。
衍生相关工作
SafeSora-Label数据集衍生了一系列经典研究工作,特别是在AI安全和对齐领域。基于该数据集的研究成果包括开发新的对齐算法、改进现有模型的安全性评估方法,以及探索如何在生成模型中更好地融入人类反馈。这些工作不仅推动了AI安全研究的前沿,还为未来的模型开发提供了重要的参考。
数据集最近研究
最新研究方向
在人工智能领域,尤其是文本到视频生成技术中,模型的安全性和伦理问题日益受到关注。SafeSora-Label数据集作为一项重要的资源,专注于通过多标签分类方法识别和标注文本-视频对中的潜在有害内容。该数据集包含57,000多个文本-视频对,每个对都标注了12种不同的有害标签,如成人内容、动物虐待、儿童虐待等。这些标签不仅帮助研究者识别和分类有害内容,还为开发更安全的大型视觉模型(LVMs)提供了基础。当前的研究方向集中在如何利用这些标注数据来训练模型,使其在生成视频时能够自动避免产生有害内容,同时保持内容的创造性和多样性。此外,该数据集还支持对模型进行安全对齐研究,旨在提高模型的有用性和无害性,这对于推动AI技术的负责任发展具有重要意义。
以上内容由遇见数据集搜集并总结生成


