SA-Text
收藏arXiv2025-09-30 收录
下载链接:
https://cvlab-kaist.github.io/TAIR/
下载链接
链接失效反馈官方服务:
资源简介:
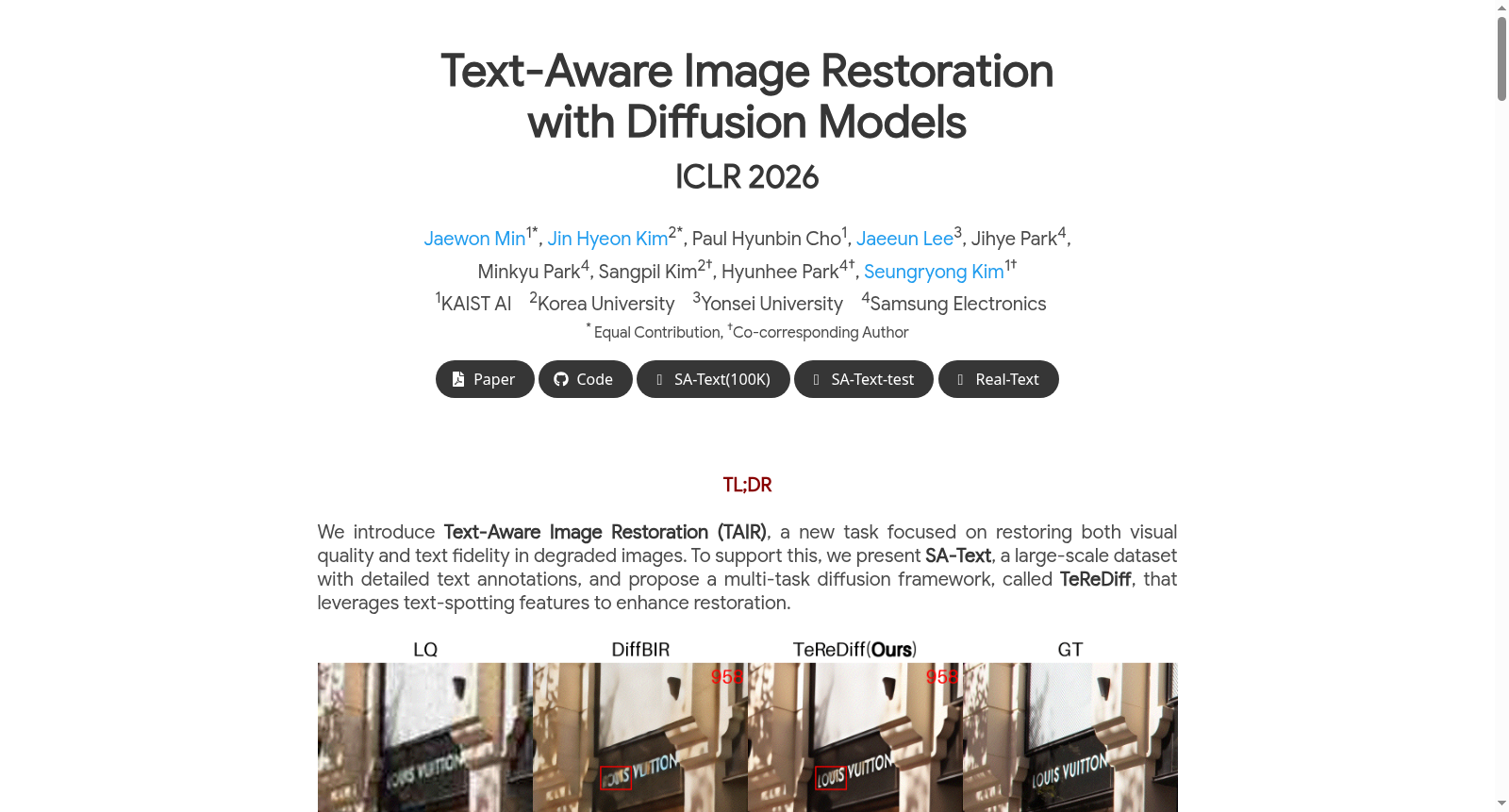
该数据集是一个大规模的基准测试,包含了10万张高质量的场景图像,这些图像被密集地标注了各种复杂文本实例。此外,数据集还包含了明确的文本标注,旨在提高文本标注的准确性,使其非常适合用于图像恢复任务。规模上,该数据集拥有10万张高质量图像,针对的任务是文本感知型图像恢复。
This dataset is a large-scale benchmark that includes 100,000 high-quality scene images densely annotated with various complex text instances. Additionally, the dataset provides explicit text annotations to improve the accuracy of text annotation, making it highly suitable for text-aware image restoration tasks. In terms of scale, this dataset has 100,000 high-quality images, targeting text-aware image restoration tasks.
提供机构:
Authors of the paper
搜集汇总
数据集介绍
背景与挑战
背景概述
SA-Text是一个大规模数据集,包含10万张高质量场景图像,密集标注了多样化和复杂的文本实例,用于文本感知图像恢复任务。该数据集基于SA-1B构建,支持恢复视觉质量和文本保真度,为多任务扩散框架TeReDiff提供训练和评估基础。
以上内容由遇见数据集搜集并总结生成


