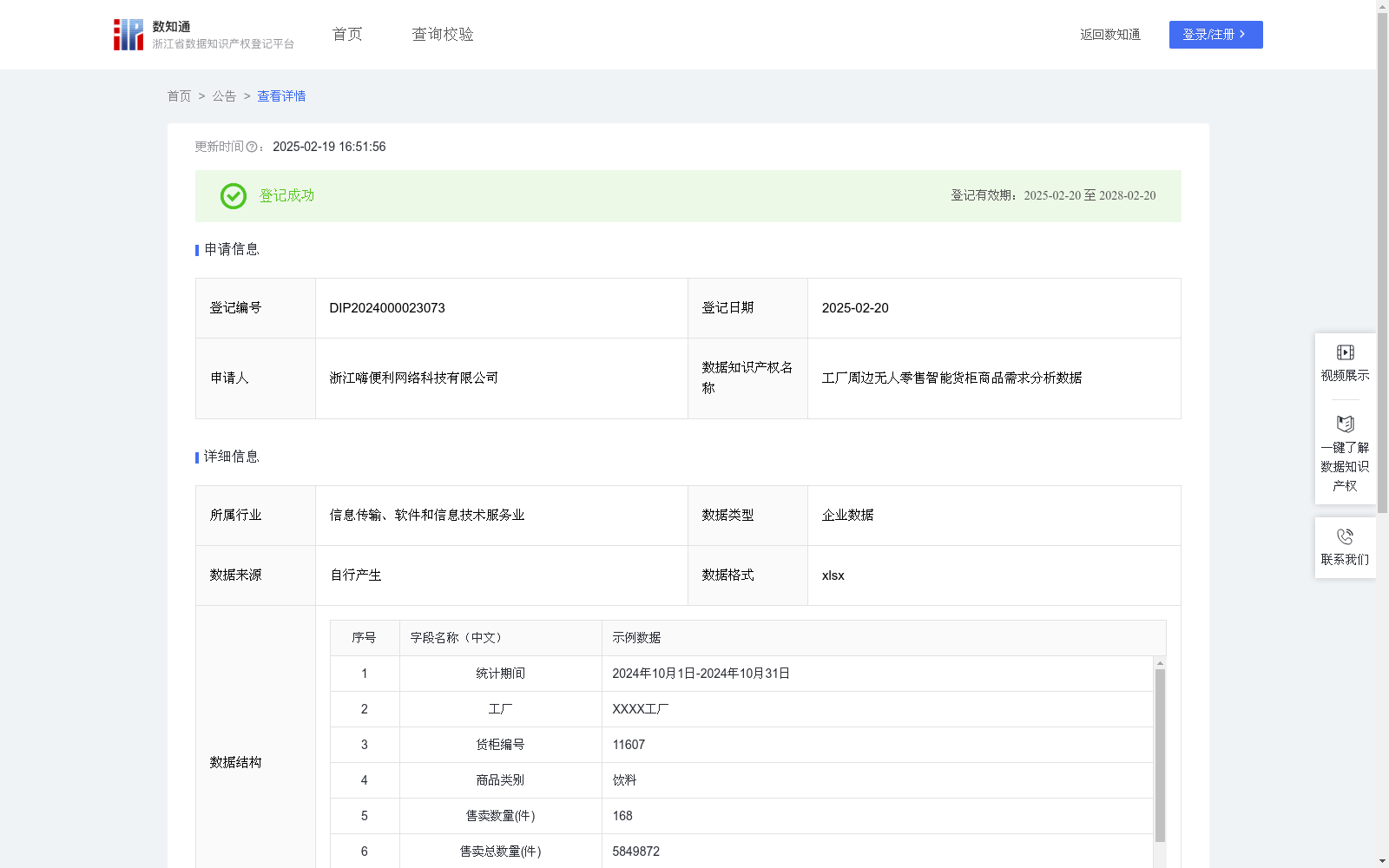
工厂周边无人零售智能货柜商品需求分析数据
收藏浙江省数据知识产权登记平台2025-02-19 更新2025-02-20 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/113219
下载链接
链接失效反馈官方服务:
资源简介:
通过研究以及过往经验发现,不同生活场景下人们消费的商品类型也有很大差别,比如学校周边的主要消费的商品为零食、文具等,而工厂周边的主要消费的商品为饮料、泡面等,所以不同场景下人们的商品需求是无人零售智能货柜行业的一个重要关注点。本数据对各个工厂周边无人零售智能货柜的售卖情况进行分析,从消费者对不同商品类别的选择中,可以得出不同商品类别的售卖占比,体现工厂场景中商品的消费需求情况,帮助充实无人零售智能货柜的企业优化不同类型商品的投放比重,指导各商家在工厂场景的智能货柜上合理分配不同类型商品的优惠方式、优惠力度及新品投放方案。
1、提取了统计区间内无人零售智能货柜有商品售出的数据,包含工厂、货柜编号、商品类别、售卖数量四个字段,对统计区间内的数据聚合,其中数量字段为统计区间内本货柜该商品类型的累计交易件数,对售卖数量及商品类别字段进行分析,2、同类商品售卖数量是通过SUMIFS函数对相同商品类别的售卖数量的求和;3、商品售卖总数量是通过SUM函数将数据统计范围内所有售卖数量求和;4、同类商品售卖数量占比=同类商品售卖数量/售卖总数量*100%;5、商品需求等级运用了ABC分类法,对同类商品售卖数量占比≥40%的,给予“A级”的评价,对40%>同类商品售卖数量占比≥20%区间的,给予“B级”的评价,同类商品售卖数量占比<20%的,给予“C级”的评价。
提供机构:
浙江嗨便利网络科技有限公司
创建时间:
2024-12-13
搜集汇总
数据集介绍
特点
该数据集为工厂周边无人零售智能货柜商品需求分析数据,包含12393条记录,每月更新。数据记录了不同工厂周边智能货柜的商品售卖情况,涵盖商品类别、售卖数量、同类商品售卖数量占比等字段,并通过ABC分类法对商品需求等级进行划分,旨在帮助优化商品投放策略。
以上内容由遇见数据集搜集并总结生成


